Compare commits
253 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
| afb59c82a7 | |||
| eb312e4060 | |||
| 0ad2307e56 | |||
| 9602893cf9 | |||
| 8ca84c1684 | |||
| e31c3793ca | |||
| 916fcba0f8 | |||
| e0d0177bc0 | |||
| 07a2832c8f | |||
| 58b6cf5dfc | |||
| a785252783 | |||
| 110127174b | |||
| 5d1217ef3d | |||
| 53a90a7822 | |||
| 781ac5c70a | |||
| 9da172df28 | |||
| 9949016652 | |||
| 479e788b58 | |||
| 69b19f450f | |||
| d1112f6b80 | |||
| 3d2828948d | |||
| 52c05d3ced | |||
| 3d33c7ef84 | |||
| a05753a28a | |||
| 3812ed515e | |||
| 95e761806b | |||
| 5cc496e93c | |||
| 70df615718 | |||
| e4521cd202 | |||
| f42f30941b | |||
| 3d1b91d0b2 | |||
| 9e24f132ee | |||
| 27b95dc12e | |||
| 904efda674 | |||
| 3886e95f23 | |||
| 4205593761 | |||
| 05b09c5db5 | |||
| fcbbe6a6c9 | |||
| 1aab0bc7b1 | |||
| 59727f6fa8 | |||
| 4bd7dbe053 | |||
| 91acdabda0 | |||
| b18ac40bd4 | |||
| 9a9411823f | |||
| 931490c45d | |||
| a9615274f1 | |||
| 9ee315d8b0 | |||
| 02678b29a6 | |||
| a528a73ec8 | |||
| 869ca41971 | |||
| 39d6d7ed79 | |||
| 817b64f4db | |||
| cf22cc7551 | |||
| f20231ddae | |||
| 93286d80ce | |||
| 2d169295cc | |||
| d0ad514d40 | |||
| a9db77194e | |||
| b2c6cebdc1 | |||
| 583e9d4925 | |||
| 646a82a956 | |||
| a463c36441 | |||
| 755e0ced62 | |||
| c7456dbbf6 | |||
| a89e84fd38 | |||
| 0472fb4c71 | |||
| 3ef37e2dc9 | |||
| 62ccbf00e2 | |||
| abd246a4fd | |||
| 1cd0dc673f | |||
| 52423554ae | |||
| ae65d9f032 | |||
| bf1ec57e4a | |||
| 1bc3f10203 | |||
| 28e2057a2e | |||
| f1b9abb4e0 | |||
| 49b94d9e13 | |||
| fa6958e551 | |||
| 1993f568bf | |||
| 7c231504ec | |||
| e55bc2978a | |||
| 8553e94547 | |||
| 2cc64150d0 | |||
| 74ab9c9da6 | |||
| b53389532f | |||
| ff53187da7 | |||
| da00f63b08 | |||
| 4ccc349ac0 | |||
| fbd95b0a82 | |||
| efc8099db3 | |||
| ded4c43700 | |||
| c2a658c61c | |||
| 64238d0205 | |||
| 350644e36d | |||
| 9f784f5c0a | |||
| 94ee7240ad | |||
| 1c6ad3c8b0 | |||
| 9a1bd49f27 | |||
| e745cc0cff | |||
| a5cb7efff1 | |||
| 939c5668a0 | |||
| 73043cdac0 | |||
| 267f68c646 | |||
| 4ece2a9461 | |||
| 7ca90f3215 | |||
| a61bc9c761 | |||
| b3bf0a7112 | |||
| 1f03736280 | |||
| a6fb6bbb3d | |||
| 62f89a4948 | |||
| ddb266825c | |||
| 741ce8b01d | |||
| 856e79732e | |||
| 69dd5b4694 | |||
| 356ca2001a | |||
| 8006c44f81 | |||
| 6e6194f820 | |||
| c602d5b8f8 | |||
| 775e146a68 | |||
| 977917b2e7 | |||
| ba61bbd438 | |||
| a9456c32ea | |||
| de69589e0e | |||
| f0ebb59f06 | |||
| 806e14d747 | |||
| e7a6d934fa | |||
| 3a1848a95e | |||
| d8f62781cc | |||
| acf1f68f85 | |||
| b28e288d7d | |||
| 87b70c0777 | |||
| 837401b8ff | |||
| 4a5250474e | |||
| 214bf3ab39 | |||
| 7c0cc3c26e | |||
| 5a8f4cbada | |||
| 82ce418c09 | |||
| 8f5e21119d | |||
| 05302c3b04 | |||
| 2d6e58d41d | |||
| 7e8297bb8b | |||
| 62cd503704 | |||
| 6e02e0219a | |||
| 2d89dcddf6 | |||
| 56cb62bad7 | |||
| 9ea5880292 | |||
| d082b3b8b0 | |||
| 8bfd815084 | |||
| 0a09e7bbef | |||
| 4115f64f84 | |||
| 381cd6bac2 | |||
| 474e08516d | |||
| f64c5df9f3 | |||
| 388d489181 | |||
| e9101d6df5 | |||
| 07d55ab192 | |||
| 8e7aef938e | |||
| da0de2464e | |||
| bbaef875e0 | |||
| e96fdb5bde | |||
| 104f6b96d7 | |||
| d3611e5640 | |||
| 6970978920 | |||
| a66188f25e | |||
| 13aaec73fa | |||
| 70d7516b8e | |||
| 540ee04816 | |||
| 0c67713063 | |||
| 17fec0a2b1 | |||
| 815cbc034a | |||
| 1634778e57 | |||
| 42f9ab8e60 | |||
| e262ab229f | |||
| c3f77abb67 | |||
| 7630a3ba77 | |||
| cb743a31f5 | |||
| 72f94b9d41 | |||
| d563cd91f8 | |||
| 4be73a8a3b | |||
| ec891ab070 | |||
| 9ec9374ea2 | |||
| 59f866100a | |||
| 3af344a12c | |||
| 8e02173583 | |||
| 5dc2d2e6bc | |||
| 1f64934d03 | |||
| de3d09e1de | |||
| ce301fcc77 | |||
| e0bc9509d1 | |||
| 9c3957c8f0 | |||
| f101f38017 | |||
| dbdd34f521 | |||
| 348ef3245d | |||
| 57fafd2126 | |||
| 05455191f5 | |||
| 0a84015943 | |||
| 830a51c334 | |||
| d391bcd7e6 | |||
| b23e3071b6 | |||
| 75e87c8d93 | |||
| 0f561b0353 | |||
| c0d530be27 | |||
| 5d8f2a2b80 | |||
| 6d60520654 | |||
| 45c6601406 | |||
| 3b06237e12 | |||
| 344c53544a | |||
| b962825ba3 | |||
| 64b493bb31 | |||
| 7ee3d2f731 | |||
| 390671b8f3 | |||
| e7ac2eaf17 | |||
| c13d7eba4d | |||
| 983966b932 | |||
| 0066061a7b | |||
| 18a427c7b0 | |||
| aed95beea1 | |||
| 32d6465bf9 | |||
| b13ce5ca0c | |||
| e718252f74 | |||
| 530d7ddb05 | |||
| d215bdb89b | |||
| 5bd27c069e | |||
| dd89a3c577 | |||
| 33fdc1396c | |||
| f7fbbc2889 | |||
| c9dd063557 | |||
| fd20b088e4 | |||
| eb50ed4a11 | |||
| d58282df5d | |||
| 2609ac9e3f | |||
| 04f0d02a97 | |||
| 24606151ad | |||
| 3193423ddd | |||
| a53231160c | |||
| 462e2a232d | |||
| adebf8b317 | |||
| 85ec0ac68d | |||
| 1be3b8eea0 | |||
| bdc4cdaf77 | |||
| 099c9f138b | |||
| dab7a7d0f8 | |||
| 30b02e6084 | |||
| af22b29ec1 | |||
| 6f69ec66a4 | |||
| b1b6cfd650 | |||
| 2d0d653e83 | |||
| 9ff7d0bc8c | |||
| 5236c18fe1 | |||
| 4c97b608ee | |||
| 838dc4c706 | |||
| 719fd33dc5 | |||
| 0c9279805e |
2
.gitignore
vendored
@ -1,4 +1,4 @@
|
||||
node_modules
|
||||
package-lock.json
|
||||
.env
|
||||
|
||||
menu.md
|
||||
@ -1,5 +1,3 @@
|
||||
Here is a `README.md` file for your project:
|
||||
|
||||
```markdown
|
||||
# Raven Scott Blog Website
|
||||
|
||||
@ -62,7 +60,7 @@ raven-scott-website
|
||||
4. Run the project:
|
||||
|
||||
```bash
|
||||
npm start
|
||||
node app.js
|
||||
```
|
||||
|
||||
The server will run on [http://localhost:3000](http://localhost:3000).
|
||||
|
||||
333
app.js
@ -6,13 +6,13 @@ const { marked } = require('marked');
|
||||
const nodemailer = require('nodemailer');
|
||||
const hljs = require('highlight.js');
|
||||
const { format } = require('date-fns'); // To format dates in a proper XML format
|
||||
const axios = require('axios'); // Add axios for reCAPTCHA verification
|
||||
|
||||
const app = express();
|
||||
|
||||
// Set options for marked to use highlight.js for syntax highlighting
|
||||
marked.setOptions({
|
||||
highlight: function (code, language) {
|
||||
// Check if the language is valid
|
||||
const validLanguage = hljs.getLanguage(language) ? language : 'plaintext';
|
||||
return hljs.highlight(validLanguage, code).value;
|
||||
}
|
||||
@ -28,6 +28,35 @@ app.use(express.urlencoded({ extended: false }));
|
||||
// Serve static files (CSS, Images)
|
||||
app.use(express.static(path.join(__dirname, 'public')));
|
||||
|
||||
// Function to load menu items from the markdown file
|
||||
function loadMenuItems() {
|
||||
const menuFile = path.join(__dirname, 'menu.md');
|
||||
const content = fs.readFileSync(menuFile, 'utf-8');
|
||||
|
||||
const menuItems = [];
|
||||
const itemRegex = /<!--\s*title:\s*(.*?)\s*-->\s*(<!--\s*openNewPage\s*-->\s*)?<!--\s*url:\s*(.*?)\s*-->/g;
|
||||
|
||||
let match;
|
||||
|
||||
// Loop to find all menu items
|
||||
while ((match = itemRegex.exec(content)) !== null) {
|
||||
const title = match[1];
|
||||
const url = match[3];
|
||||
const openNewPage = !!match[2]; // Check if openNewPage is present in the match
|
||||
|
||||
menuItems.push({
|
||||
title,
|
||||
url,
|
||||
openNewPage
|
||||
});
|
||||
}
|
||||
|
||||
return menuItems;
|
||||
}
|
||||
|
||||
// Load the menu once and make it available to all routes
|
||||
const menuItems = loadMenuItems();
|
||||
|
||||
// Function to load and parse markdown files and extract lead
|
||||
function loadMarkdownWithLead(file) {
|
||||
const markdownContent = fs.readFileSync(path.join(__dirname, 'markdown', file), 'utf-8');
|
||||
@ -35,39 +64,44 @@ function loadMarkdownWithLead(file) {
|
||||
let lead = '';
|
||||
let contentMarkdown = markdownContent;
|
||||
|
||||
// Detect and extract the lead section
|
||||
const leadKeyword = '<!-- lead -->';
|
||||
if (contentMarkdown.includes(leadKeyword)) {
|
||||
const [beforeLead, afterLead] = contentMarkdown.split(leadKeyword);
|
||||
|
||||
// Extract the first paragraph after the lead keyword
|
||||
lead = afterLead.split('\n').find(line => line.trim() !== '').trim();
|
||||
|
||||
// Remove the lead from the main content
|
||||
contentMarkdown = beforeLead + afterLead.replace(lead, '').trim();
|
||||
}
|
||||
|
||||
// Convert markdown to HTML
|
||||
const contentHtml = marked.parse(contentMarkdown);
|
||||
|
||||
return { contentHtml, lead };
|
||||
}
|
||||
|
||||
// Function to convert a title (with spaces) into a URL-friendly slug (with dashes)
|
||||
// Function to convert a title into a URL-friendly slug
|
||||
function titleToSlug(title) {
|
||||
return title.replace(/\s+/g, '-').toLowerCase(); // Always lowercase the slug
|
||||
return title
|
||||
.toLowerCase()
|
||||
.replace(/[^a-z0-9\s-]/g, '')
|
||||
.replace(/\s+/g, '-');
|
||||
}
|
||||
|
||||
// Function to convert a slug (with dashes) back into a readable title (with spaces)
|
||||
function slugToTitle(slug) {
|
||||
return slug.replace(/-/g, ' ');
|
||||
}
|
||||
// Function to load all blog posts with pagination and search support
|
||||
function getAllBlogPosts(page = 1, postsPerPage = 5, searchQuery = '') {
|
||||
let blogFiles = fs.readdirSync(path.join(__dirname, 'markdown')).filter(file => file.endsWith('.md'));
|
||||
|
||||
// Function to load all blog posts with pagination support
|
||||
function getAllBlogPosts(page = 1, postsPerPage = 5) {
|
||||
const blogFiles = fs.readdirSync(path.join(__dirname, 'markdown')).filter(file => file.endsWith('.md'));
|
||||
if (searchQuery) {
|
||||
const lowerCaseQuery = searchQuery.toLowerCase();
|
||||
blogFiles = blogFiles.filter(file => file.toLowerCase().includes(lowerCaseQuery));
|
||||
}
|
||||
|
||||
if (blogFiles.length === 0) {
|
||||
return { blogPosts: [], totalPages: 0 }; // Return empty results if no files
|
||||
}
|
||||
|
||||
blogFiles.sort((a, b) => {
|
||||
const statA = fs.statSync(path.join(__dirname, 'markdown', a)).birthtime;
|
||||
const statB = fs.statSync(path.join(__dirname, 'markdown', b)).birthtime;
|
||||
return statB - statA;
|
||||
});
|
||||
|
||||
// Paginate the results
|
||||
const totalPosts = blogFiles.length;
|
||||
const totalPages = Math.ceil(totalPosts / postsPerPage);
|
||||
const start = (page - 1) * postsPerPage;
|
||||
@ -76,116 +110,101 @@ function getAllBlogPosts(page = 1, postsPerPage = 5) {
|
||||
const paginatedFiles = blogFiles.slice(start, end);
|
||||
|
||||
const blogPosts = paginatedFiles.map(file => {
|
||||
const title = file.replace('.md', '').replace(/-/g, ' '); // Keep original casing for title
|
||||
const slug = titleToSlug(title); // Convert title to slug (lowercase)
|
||||
|
||||
// Get the last modified date of the markdown file
|
||||
const title = file.replace('.md', '').replace(/-/g, ' ');
|
||||
const slug = titleToSlug(title);
|
||||
const stats = fs.statSync(path.join(__dirname, 'markdown', file));
|
||||
const lastModifiedDate = new Date(stats.mtime); // Use mtime for last modification time
|
||||
const dateCreated = new Date(stats.birthtime);
|
||||
|
||||
// Format the date
|
||||
const formattedDate = lastModifiedDate.toLocaleDateString('en-US', {
|
||||
year: 'numeric',
|
||||
month: 'long',
|
||||
day: 'numeric'
|
||||
});
|
||||
|
||||
return {
|
||||
title, // Original casing title
|
||||
slug,
|
||||
date: formattedDate // Include the formatted date
|
||||
};
|
||||
return { title, slug, dateCreated };
|
||||
});
|
||||
|
||||
return { blogPosts, totalPages };
|
||||
}
|
||||
|
||||
// Home Route (Blog Home with Pagination)
|
||||
// Home Route (Blog Home with Pagination and Search)
|
||||
app.get('/', (req, res) => {
|
||||
const page = parseInt(req.query.page) || 1;
|
||||
const searchQuery = req.query.search || '';
|
||||
|
||||
if (page < 1) {
|
||||
return res.redirect(req.hostname);
|
||||
}
|
||||
|
||||
const postsPerPage = 5; // Set how many posts to display per page
|
||||
const postsPerPage = 5;
|
||||
const { blogPosts, totalPages } = getAllBlogPosts(page, postsPerPage, searchQuery);
|
||||
|
||||
const { blogPosts, totalPages } = getAllBlogPosts(page, postsPerPage);
|
||||
const noResults = blogPosts.length === 0; // Check if there are no results
|
||||
|
||||
res.render('index', {
|
||||
title: 'Raven Scott Blog',
|
||||
title: `${process.env.OWNER_NAME}'s Blog`,
|
||||
blogPosts,
|
||||
currentPage: page,
|
||||
totalPages
|
||||
totalPages,
|
||||
searchQuery, // Pass search query to the view
|
||||
noResults, // Pass this flag to indicate no results found
|
||||
menuItems // Pass the menu items to the view
|
||||
});
|
||||
});
|
||||
|
||||
// About Route
|
||||
// About Route (Load markdown and render using EJS)
|
||||
app.get('/about', (req, res) => {
|
||||
res.render('about', { title: 'About Raven Scott' });
|
||||
});
|
||||
const aboutMarkdownFile = path.join(__dirname, 'me', 'about.md');
|
||||
|
||||
// Display the Request a Quote form
|
||||
app.get('/contact', (req, res) => {
|
||||
res.render('contact', { title: 'Contact Raven Scott', msg: undefined });
|
||||
});
|
||||
|
||||
// Handle contact form submission
|
||||
app.post('/contact', (req, res) => {
|
||||
const { name, email, subject, message } = req.body;
|
||||
|
||||
// Validate form inputs (basic example)
|
||||
if (!name || !email || !subject || !message) {
|
||||
return res.render('contact', { title: 'Contact Raven Scott', msg: 'All fields are required.' });
|
||||
}
|
||||
|
||||
// Create email content
|
||||
const output = `
|
||||
<p>You have a new contact request from <strong>${name}</strong>.</p>
|
||||
<h3>Contact Details</h3>
|
||||
<ul>
|
||||
<li><strong>Name:</strong> ${name}</li>
|
||||
<li><strong>Email:</strong> ${email}</li>
|
||||
<li><strong>Subject:</strong> ${subject}</li>
|
||||
</ul>
|
||||
<h3>Message</h3>
|
||||
<p>${message}</p>
|
||||
`;
|
||||
|
||||
// Set up Nodemailer transporter
|
||||
let transporter = nodemailer.createTransport({
|
||||
host: process.env.SMTP_HOST,
|
||||
port: process.env.SMTP_PORT,
|
||||
secure: false, // true for 465, false for other ports
|
||||
auth: {
|
||||
user: process.env.EMAIL_USER, // Email user from environment variables
|
||||
pass: process.env.EMAIL_PASS, // Email password from environment variables
|
||||
},
|
||||
tls: {
|
||||
rejectUnauthorized: false,
|
||||
},
|
||||
});
|
||||
|
||||
// Set up email options
|
||||
let mailOptions = {
|
||||
from: `"${name}" <quote@node-geeks.com>`,
|
||||
to: process.env.RECEIVER_EMAIL, // Your email address to receive contact form submissions
|
||||
subject: subject,
|
||||
html: output,
|
||||
};
|
||||
|
||||
// Send email
|
||||
transporter.sendMail(mailOptions, (error, info) => {
|
||||
if (error) {
|
||||
console.error(error);
|
||||
return res.render('contact', { title: 'Contact Raven Scott', msg: 'An error occurred. Please try again.' });
|
||||
} else {
|
||||
console.log('Email sent: ' + info.response);
|
||||
return res.render('contact', { title: 'Contact Raven Scott', msg: 'Your message has been sent successfully!' });
|
||||
// Read the markdown file and convert to HTML
|
||||
fs.readFile(aboutMarkdownFile, 'utf-8', (err, data) => {
|
||||
if (err) {
|
||||
return res.status(500).send('Error loading About page');
|
||||
}
|
||||
|
||||
const aboutContentHtml = marked(data); // Convert markdown to HTML
|
||||
|
||||
res.render('about', {
|
||||
title: `About ${process.env.OWNER_NAME}`,
|
||||
content: aboutContentHtml,
|
||||
menuItems // Pass the menu items to the view
|
||||
});
|
||||
});
|
||||
});
|
||||
|
||||
// About Route (Load markdown and render using EJS)
|
||||
app.get('/about-rayai', (req, res) => {
|
||||
const aboutMarkdownFile = path.join(__dirname, 'me', 'about-rayai.md');
|
||||
|
||||
// Read the markdown file and convert to HTML
|
||||
fs.readFile(aboutMarkdownFile, 'utf-8', (err, data) => {
|
||||
if (err) {
|
||||
return res.status(500).send('Error loading About page');
|
||||
}
|
||||
|
||||
const aboutContentHtml = marked(data); // Convert markdown to HTML
|
||||
|
||||
res.render('about-rayai', {
|
||||
title: `About RayAI`,
|
||||
content: aboutContentHtml,
|
||||
menuItems // Pass the menu items to the view
|
||||
});
|
||||
});
|
||||
});
|
||||
|
||||
// Contact Route (Render the contact form)
|
||||
app.get('/contact', (req, res) => {
|
||||
res.render('contact', {
|
||||
title: `Contact ${process.env.OWNER_NAME}`,
|
||||
msg: undefined,
|
||||
menuItems // Pass the menu items to the view
|
||||
});
|
||||
});
|
||||
|
||||
// Contact Route (Render the contact form)
|
||||
app.get('/chat', (req, res) => {
|
||||
res.render('chat', {
|
||||
title: `RayAI - Raven's Chatbot`,
|
||||
msg: undefined,
|
||||
menuItems // Pass the menu items to the view
|
||||
});
|
||||
});
|
||||
|
||||
|
||||
// Blog Post Route
|
||||
app.get('/blog/:slug', (req, res) => {
|
||||
const slug = req.params.slug;
|
||||
@ -193,59 +212,63 @@ app.get('/blog/:slug', (req, res) => {
|
||||
.find(file => titleToSlug(file.replace('.md', '')) === slug);
|
||||
|
||||
if (markdownFile) {
|
||||
const originalTitle = markdownFile.replace('.md', ''); // Original title with casing
|
||||
const originalTitle = markdownFile.replace('.md', '');
|
||||
const blogPosts = getAllBlogPosts();
|
||||
const { contentHtml, lead } = loadMarkdownWithLead(markdownFile);
|
||||
|
||||
// Fallback to a generic description if lead is not available
|
||||
const description = lead || `${originalTitle} - Read the full post on ${process.env.OWNER_NAME}'s blog.`;
|
||||
|
||||
res.render('blog-post', {
|
||||
title: originalTitle, // Use the original title with casing
|
||||
title: originalTitle,
|
||||
content: contentHtml,
|
||||
lead: lead,
|
||||
blogPosts
|
||||
lead,
|
||||
description, // Pass the description to the view
|
||||
blogPosts,
|
||||
menuItems // Pass the menu items to the view
|
||||
});
|
||||
} else {
|
||||
res.redirect('/'); // Redirect to the home page if the blog post is not found
|
||||
res.redirect('/');
|
||||
}
|
||||
});
|
||||
|
||||
|
||||
// Sitemap Route
|
||||
app.get('/sitemap.xml', (req, res) => {
|
||||
const hostname = req.headers.host || 'http://localhost'; // Ensure this is your site URL in production
|
||||
const blogFiles = fs.readdirSync(path.join(__dirname, 'markdown')).filter(file => file.endsWith('.md'));
|
||||
const hostname = req.headers.host || 'http://localhost';
|
||||
const blogFiles = fs.readdirSync(path.join(__dirname, 'markdown'))
|
||||
.filter(file => file.endsWith('.md'))
|
||||
.sort((a, b) => {
|
||||
const statA = fs.statSync(path.join(__dirname, 'markdown', a)).birthtime;
|
||||
const statB = fs.statSync(path.join(__dirname, 'markdown', b)).birthtime;
|
||||
return statB - statA;
|
||||
});
|
||||
|
||||
// Static URLs (e.g., homepage, about, contact)
|
||||
const staticUrls = [
|
||||
{ url: '/', changefreq: 'weekly', priority: 1.0 },
|
||||
{ url: '/about', changefreq: 'monthly', priority: 0.8 },
|
||||
{ url: '/contact', changefreq: 'monthly', priority: 0.8 }
|
||||
{ url: `${process.env.HOST_URL}`, changefreq: 'weekly', priority: 1.0 },
|
||||
{ url: `${process.env.HOST_URL}/about`, changefreq: 'monthly', priority: 0.8 },
|
||||
{ url: `${process.env.HOST_URL}/contact`, changefreq: 'monthly', priority: 0.8 }
|
||||
];
|
||||
|
||||
// Dynamic URLs (e.g., blog posts)
|
||||
const blogUrls = blogFiles.map(file => {
|
||||
const title = file.replace('.md', '');
|
||||
const slug = titleToSlug(title);
|
||||
|
||||
// Get the last modified date of the markdown file
|
||||
const stats = fs.statSync(path.join(__dirname, 'markdown', file));
|
||||
const lastModifiedDate = format(new Date(stats.mtime), 'yyyy-MM-dd');
|
||||
const lastModifiedDate = format(new Date(stats.birthtime), 'yyyy-MM-dd');
|
||||
|
||||
return {
|
||||
url: `/blog/${slug}`,
|
||||
url: `${process.env.BLOG_URL}${slug}`,
|
||||
lastmod: lastModifiedDate,
|
||||
changefreq: 'monthly',
|
||||
priority: 0.9
|
||||
};
|
||||
});
|
||||
|
||||
// Combine static and dynamic URLs
|
||||
const urls = [...staticUrls, ...blogUrls];
|
||||
|
||||
// Generate the XML for the sitemap
|
||||
let sitemap = `<?xml version="1.0" encoding="UTF-8"?>\n<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">\n`;
|
||||
urls.forEach(({ url, lastmod, changefreq, priority }) => {
|
||||
sitemap += ` <url>\n`;
|
||||
sitemap += ` <loc>https://${hostname}${url}</loc>\n`;
|
||||
sitemap += ` <loc>${url}</loc>\n`;
|
||||
if (lastmod) {
|
||||
sitemap += ` <lastmod>${lastmod}</lastmod>\n`;
|
||||
}
|
||||
@ -255,59 +278,85 @@ app.get('/sitemap.xml', (req, res) => {
|
||||
});
|
||||
sitemap += `</urlset>`;
|
||||
|
||||
// Set the content type to XML and send the response
|
||||
res.header('Content-Type', 'application/xml');
|
||||
res.send(sitemap);
|
||||
});
|
||||
|
||||
// RSS Feed Route
|
||||
app.get('/rss', (req, res) => {
|
||||
const hostname = req.headers.host || 'http://localhost'; // Adjust for production if needed
|
||||
const blogFiles = fs.readdirSync(path.join(__dirname, 'markdown')).filter(file => file.endsWith('.md'));
|
||||
const hostname = req.headers.host || 'http://localhost';
|
||||
const blogFiles = fs.readdirSync(path.join(__dirname, 'markdown'))
|
||||
.filter(file => file.endsWith('.md'))
|
||||
.sort((a, b) => {
|
||||
const statA = fs.statSync(path.join(__dirname, 'markdown', a)).birthtime;
|
||||
const statB = fs.statSync(path.join(__dirname, 'markdown', b)).birthtime;
|
||||
return statB - statA;
|
||||
});
|
||||
|
||||
// Build RSS feed
|
||||
let rssFeed = `<?xml version="1.0" encoding="UTF-8" ?>\n<rss version="2.0">\n<channel>\n`;
|
||||
rssFeed += `<title>Raven Scott Blog</title>\n`;
|
||||
rssFeed += `<title>${process.env.OWNER_NAME} Blog</title>\n`;
|
||||
rssFeed += `<link>https://${hostname}</link>\n`;
|
||||
rssFeed += `<description>This is the RSS feed for Raven Scott's blog.</description>\n`;
|
||||
rssFeed += `<description>This is the RSS feed for ${process.env.OWNER_NAME}'s blog.</description>\n`;
|
||||
|
||||
// Generate RSS items for each blog post
|
||||
blogFiles.forEach(file => {
|
||||
const title = file.replace('.md', '');
|
||||
const slug = titleToSlug(title);
|
||||
|
||||
// Get the last modified date of the markdown file
|
||||
const stats = fs.statSync(path.join(__dirname, 'markdown', file));
|
||||
const lastModifiedDate = new Date(stats.mtime).toUTCString(); // Use UTC date for RSS
|
||||
|
||||
// Load and parse markdown content to extract a lead or description
|
||||
const lastModifiedDate = new Date(stats.birthtime).toUTCString();
|
||||
const { lead } = loadMarkdownWithLead(file);
|
||||
|
||||
// RSS item for each post
|
||||
rssFeed += `<item>\n`;
|
||||
rssFeed += `<title>${title}</title>\n`;
|
||||
rssFeed += `<link>https://${hostname}/blog/${slug}</link>\n`;
|
||||
rssFeed += `<link>${process.env.BLOG_URL}${slug}</link>\n`;
|
||||
rssFeed += `<description>${lead || 'Read the full post on the blog.'}</description>\n`;
|
||||
rssFeed += `<pubDate>${lastModifiedDate}</pubDate>\n`;
|
||||
rssFeed += `<guid>https://${hostname}/blog/${slug}</guid>\n`;
|
||||
rssFeed += `<guid>${process.env.BLOG_URL}${slug}</guid>\n`;
|
||||
rssFeed += `</item>\n`;
|
||||
});
|
||||
|
||||
rssFeed += `</channel>\n</rss>`;
|
||||
|
||||
// Set content type to XML and send the RSS feed
|
||||
res.header('Content-Type', 'application/rss+xml');
|
||||
res.send(rssFeed);
|
||||
});
|
||||
|
||||
// Global 404 handler for any other unmatched routes
|
||||
app.use((req, res) => {
|
||||
res.redirect('/'); // Redirect to the home page for any 404 error
|
||||
// Route to return all blog content in plain text JSON format
|
||||
app.get('/json', (req, res) => {
|
||||
const blogFiles = fs.readdirSync(path.join(__dirname, 'markdown')).filter(file => file.endsWith('.md'));
|
||||
|
||||
const blogPosts = blogFiles.map(file => {
|
||||
const title = file.replace('.md', '').replace(/-/g, ' ');
|
||||
const slug = titleToSlug(title);
|
||||
const markdownContent = fs.readFileSync(path.join(__dirname, 'markdown', file), 'utf-8');
|
||||
|
||||
// Strip all formatting and return plain text
|
||||
const plainTextContent = markdownContent.replace(/[#*>\-`_~[\]]/g, '').replace(/\n+/g, ' ').trim();
|
||||
|
||||
return {
|
||||
title,
|
||||
slug,
|
||||
content: plainTextContent
|
||||
};
|
||||
});
|
||||
|
||||
res.json(blogPosts);
|
||||
});
|
||||
|
||||
// Create a URL object from the environment variable
|
||||
const blog_URL = new URL(process.env.BLOG_URL);
|
||||
|
||||
// Extract just the hostname (e.g., blog.raven-scott.fyi)
|
||||
const hostname = blog_URL.hostname;
|
||||
|
||||
// Global 404 handler for unmatched routes
|
||||
app.use((req, res) => {
|
||||
if (req.hostname === hostname) {
|
||||
res.redirect(process.env.HOST_URL);
|
||||
} else {
|
||||
res.redirect('/');
|
||||
}
|
||||
});
|
||||
|
||||
// ================================
|
||||
// Server Listening
|
||||
// ================================
|
||||
const PORT = process.env.PORT || 8899;
|
||||
app.listen(PORT, () => {
|
||||
console.log(`Server running on http://localhost:${PORT}`);
|
||||
|
||||
29
default.env
Normal file
@ -0,0 +1,29 @@
|
||||
# SMTP configuration for sending emails
|
||||
SMTP_HOST=us2.smtp.yourtld.com # SMTP server host
|
||||
SMTP_PORT=587 # SMTP server port
|
||||
EMAIL_USER=user@yourtld.com # Email address used for SMTP authentication
|
||||
EMAIL_PASS="ComplexPass" # Password for the SMTP user (Use a complex, secure password)
|
||||
RECEIVER_EMAIL=youremail@yourtld.com # Default receiver email for outgoing messages
|
||||
|
||||
# CAPTCHA key for form verification (replace with your real CAPTCHA secret key)
|
||||
CAPTCHA_SECRET_KEY="KEYHERE"
|
||||
CAPTCHA_SITE_KEY="SITE_KEY_HERE"
|
||||
|
||||
# URL configuration
|
||||
# NO TRAILING SLASH - Base host URL for the website
|
||||
HOST_URL="https://yourtld.com"
|
||||
# TRAILING SLASH - Blog URL, should have a trailing slash at the end
|
||||
BLOG_URL="https://blog.yourtld.com/"
|
||||
# Domain name, without URL structure
|
||||
DOMAIN_NAME="yourtld.com"
|
||||
|
||||
# Website branding
|
||||
SITE_NAME="what ever you want here" # Title used in the website's navbar
|
||||
OWNER_NAME="Your Name" # Name of the website's owner (you)
|
||||
|
||||
# Front page content
|
||||
FRONT_PAGE_TITLE="Hello, my name is Your Name" # Main heading on the homepage
|
||||
FRONT_PAGE_LEAD="Where Technology Meets Creativity: Insights from a Linux Enthusiast" # Short lead text on the homepage
|
||||
|
||||
# Footer content
|
||||
FOOTER_TAGLINE="Never Stop Learning" # Tagline for the footer section of the website
|
||||
12
default.menu.md
Normal file
@ -0,0 +1,12 @@
|
||||
<!-- title: Home -->
|
||||
<!-- url: / -->
|
||||
|
||||
<!-- title: About Me -->
|
||||
<!-- url: /about -->
|
||||
|
||||
<!-- title: Secrets -->
|
||||
<!-- openNewPage -->
|
||||
<!-- url: https://your-external-link.com -->
|
||||
|
||||
<!-- title: Contact -->
|
||||
<!-- url: /contact -->
|
||||
429
markdown/Autogen.space: Dynamically Generated Webpages.md
Normal file
@ -0,0 +1,429 @@
|
||||
|
||||
|
||||
<!-- lead -->
|
||||
Deep Dive: Building an AI-Powered Dynamic HTML Generator with Express, Groq SDK, and NodeCache
|
||||
|
||||
In this blog post, we’re going to dive into an advanced Node.js application that dynamically generates AI-powered HTML pages. We'll cover every aspect of the project—from setting up the server and caching mechanism to handling rate limits and errors when interfacing with an external AI service. This case study provides insight into high-end engineering decisions that help build a scalable, robust, and maintainable system.
|
||||
|
||||
# Main URL
|
||||
|
||||
https://autogen.space
|
||||
|
||||
## Introduction
|
||||
|
||||
Modern web applications demand real-time content generation and robust error handling. This project addresses several challenges:
|
||||
|
||||
- **Dynamic Content Generation:** Using AI to generate tailored HTML based on user requests.
|
||||
- **Efficient Caching:** Reducing repeated expensive API calls by caching generated HTML.
|
||||
- **Robust Error Handling:** Implementing exponential backoff to manage rate limits and transient server issues.
|
||||
- **Modular Design:** Separating concerns (cache management, AI communication, HTTP routing) for maintainability and scalability.
|
||||
- **Dynamic Subdomain Handling:** Utilizing wildcard DNS entries and a wildcard Virtual Host to route requests from any subdomain to the application, enabling multi-tenant support.
|
||||
|
||||
By analyzing each component of the code, you'll gain insights into how to build similar systems that rely on external APIs for dynamic content while ensuring high performance and reliability.
|
||||
|
||||
|
||||
|
||||
## Project Overview
|
||||
|
||||
The application listens for HTTP requests on an Express server and generates HTML pages dynamically. The high-level workflow is as follows:
|
||||
|
||||
1. **Keyword Extraction:**
|
||||
The system extracts a keyword from the request’s hostname. For multi-level domains, it uses the first subdomain (after replacing dashes with spaces) to determine the context; if no subdomain exists, it falls back to a default keyword.
|
||||
|
||||
2. **Cache Lookup:**
|
||||
The application first checks an in-memory cache (with disk persistence) to see if a page for the keyword has already been generated, thus avoiding unnecessary API calls.
|
||||
|
||||
3. **AI-Driven Content Generation:**
|
||||
- **Additional Context Request:** The system makes an initial request to the AI service to get contextual information about the keyword.
|
||||
- **HTML Generation Request:** Using the additional context, a second request generates a full HTML page styled with Bootstrap, enriched with SVG graphics, interactive modals, charts, and more.
|
||||
|
||||
4. **Caching and Response:**
|
||||
The generated HTML is stored in cache (and persisted to disk) and then served to the client.
|
||||
|
||||
5. **Error Handling and Rate Limiting:**
|
||||
The application implements an exponential backoff strategy for handling API rate limits and transient server errors, ensuring resilience and better user experience.
|
||||
|
||||
6. **Dynamic Subdomain Resolution:**
|
||||
By leveraging wildcard DNS entries and a wildcard Virtual Host, the application receives requests from any subdomain, which is then used to drive the dynamic HTML generation process.
|
||||
|
||||
|
||||
|
||||
## Detailed Code Walkthrough
|
||||
|
||||
Let's examine the code in detail, explaining the purpose and functionality of each segment.
|
||||
|
||||
### Dependency Imports and Environment Setup
|
||||
|
||||
The application begins with importing the necessary modules and configuring environment variables.
|
||||
|
||||
```javascript
|
||||
import express from 'express';
|
||||
import Groq from 'groq-sdk';
|
||||
import 'dotenv/config';
|
||||
import NodeCache from 'node-cache';
|
||||
import fs from 'fs';
|
||||
```
|
||||
|
||||
- **Express:** A minimal and flexible Node.js web application framework for building APIs.
|
||||
- **Groq SDK:** Provides a client to interact with the AI API.
|
||||
- **dotenv:** Loads environment variables from a `.env` file for secure configuration.
|
||||
- **NodeCache:** A simple in-memory caching solution with TTL (time-to-live) support.
|
||||
- **fs:** The Node.js file system module, used for cache persistence.
|
||||
|
||||
We then define constants and create our primary objects:
|
||||
|
||||
```javascript
|
||||
const CACHE_FILE = 'cache.json';
|
||||
const app = express();
|
||||
const port = 8998;
|
||||
const cache = new NodeCache({ stdTTL: 30 * 24 * 60 * 60, checkperiod: 60 * 60 }); // 30 days TTL, checks every hour
|
||||
```
|
||||
|
||||
**Highlights:**
|
||||
|
||||
- **Cache Lifetime:** The cache is configured with a 30-day TTL and an hourly check to remove expired entries.
|
||||
- **Port Assignment:** The Express server listens on port `8998`.
|
||||
|
||||
|
||||
|
||||
### Cache Management and Persistence
|
||||
|
||||
Caching is essential to reduce repeated expensive API calls. Here, NodeCache is used for in-memory caching, and the cache is serialized to a file for persistence across server restarts.
|
||||
|
||||
#### Loading Cache from Disk
|
||||
|
||||
When the server starts, it attempts to load a previously saved cache:
|
||||
|
||||
```javascript
|
||||
function loadCacheFromDisk() {
|
||||
if (fs.existsSync(CACHE_FILE)) {
|
||||
try {
|
||||
const data = fs.readFileSync(CACHE_FILE, 'utf8');
|
||||
const jsonData = JSON.parse(data);
|
||||
for (const [key, value] of Object.entries(jsonData)) {
|
||||
cache.set(key, value);
|
||||
}
|
||||
console.log('✅ Cache loaded from disk');
|
||||
} catch (error) {
|
||||
console.error('❌ Error loading cache from disk:', error);
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
**Key Considerations:**
|
||||
|
||||
- **Robustness:** The code checks if the cache file exists and handles any errors during file reading or JSON parsing.
|
||||
- **Granularity:** Each key-value pair is loaded into the in-memory cache, ensuring that subsequent requests can be served quickly.
|
||||
|
||||
#### Saving Cache to Disk
|
||||
|
||||
After updates to the cache, the new state is saved back to disk:
|
||||
|
||||
```javascript
|
||||
function saveCacheToDisk() {
|
||||
try {
|
||||
const data = JSON.stringify(cache.mget(cache.keys()), null, 2);
|
||||
fs.writeFileSync(CACHE_FILE, data, 'utf8');
|
||||
console.log('💾 Cache saved to disk');
|
||||
} catch (error) {
|
||||
console.error('❌ Error saving cache to disk:', error);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
**Highlights:**
|
||||
|
||||
- **Serialization:** The entire cache is serialized in a human-readable JSON format.
|
||||
- **Synchronization:** This persistence mechanism helps to ensure that the cache survives server restarts, reducing the need to re-fetch data from the AI API.
|
||||
|
||||
|
||||
|
||||
### Initializing the Groq Client and AI Request Handling
|
||||
|
||||
The Groq client is configured using the API key stored in the environment, with settings for retries and timeouts:
|
||||
|
||||
```javascript
|
||||
const client = new Groq({
|
||||
apiKey: process.env['GROQ_API_KEY'],
|
||||
maxRetries: 2,
|
||||
timeout: 20 * 1000, // 20 seconds timeout per request
|
||||
});
|
||||
```
|
||||
|
||||
**Considerations:**
|
||||
|
||||
- **Security:** The API key is securely loaded from environment variables.
|
||||
- **Timeouts and Retries:** Configuring retries and timeouts ensures that API calls do not hang indefinitely, which is crucial for maintaining a responsive server.
|
||||
|
||||
#### Utility Function: `sleep`
|
||||
|
||||
To handle delays between retry attempts, a simple sleep function is implemented:
|
||||
|
||||
```javascript
|
||||
const sleep = (ms) => new Promise(resolve => setTimeout(resolve, ms));
|
||||
```
|
||||
|
||||
This function is used to introduce delays, implementing an exponential backoff mechanism when rate limits are encountered.
|
||||
|
||||
#### AI Request with Rate Limit Handling
|
||||
|
||||
The function `requestWithRateLimitHandling` abstracts the logic of making requests to the AI API while managing errors and rate limits.
|
||||
|
||||
```javascript
|
||||
async function requestWithRateLimitHandling(prompt) {
|
||||
let attempt = 0;
|
||||
const maxAttempts = 5;
|
||||
|
||||
while (attempt < maxAttempts) {
|
||||
try {
|
||||
const response = await client.chat.completions.create({
|
||||
messages: [{ role: 'user', content: prompt }],
|
||||
model: 'llama-3.1-8b-instant',
|
||||
});
|
||||
console.log('✅ Response received');
|
||||
return response.choices[0].message.content;
|
||||
} catch (err) {
|
||||
if (err instanceof Groq.APIError) {
|
||||
console.error(`❌ Error ${err.status}: ${err.name}`);
|
||||
|
||||
if (err.status === 429) { // Rate limit handling
|
||||
const retryAfterMs = (2 ** attempt) * 1000;
|
||||
console.log(`⚠️ Rate limit hit. Retrying in ${retryAfterMs / 1000} seconds...`);
|
||||
await sleep(retryAfterMs);
|
||||
attempt++;
|
||||
continue;
|
||||
}
|
||||
|
||||
if (err.status >= 500 || err.status === 408 || err.status === 409) { // Server errors
|
||||
const retryAfterMs = (2 ** attempt) * 1000;
|
||||
console.log(`⚠️ Server error. Retrying in ${retryAfterMs / 1000} seconds...`);
|
||||
await sleep(retryAfterMs);
|
||||
attempt++;
|
||||
continue;
|
||||
}
|
||||
}
|
||||
throw err;
|
||||
}
|
||||
}
|
||||
throw new Error('❌ Max retry attempts reached, request failed.');
|
||||
}
|
||||
```
|
||||
|
||||
**Important Aspects:**
|
||||
|
||||
- **Exponential Backoff:** Each retry increases the delay exponentially (`2^attempt * 1000 ms`), which helps mitigate further rate limit issues.
|
||||
- **Error Differentiation:** The code distinguishes between rate limit errors (HTTP 429) and server errors (HTTP 5xx, 408, 409), allowing for tailored retry strategies.
|
||||
- **Fail-Safe:** After exhausting the maximum attempts, the function throws an error, enabling the calling code to handle the failure appropriately.
|
||||
|
||||
|
||||
|
||||
### Express Route: Dynamic HTML Generation
|
||||
|
||||
The core of the application is the Express route that generates HTML content based on the incoming request. This route encapsulates the entire workflow from keyword extraction to AI-driven HTML generation and caching.
|
||||
|
||||
```javascript
|
||||
app.get('*', async (req, res) => {
|
||||
try {
|
||||
const hostHeader = req.headers.host || '';
|
||||
const hostname = hostHeader.split(':')[0];
|
||||
const parts = hostname.split('.');
|
||||
let keyword = parts.length > 2 ? parts[0].replace(/-/g, ' ') : 'default';
|
||||
|
||||
// Check cache first
|
||||
const cachedHTML = cache.get(keyword);
|
||||
if (cachedHTML) {
|
||||
console.log(`⚡ Serving from cache: ${keyword}`);
|
||||
res.set('Content-Type', 'text/html');
|
||||
return res.send(cachedHTML);
|
||||
}
|
||||
|
||||
console.log(`🆕 Fetching additional context for: ${keyword}`);
|
||||
|
||||
// First AI request: Get additional context about the keyword
|
||||
const contextPrompt = `
|
||||
Act as a research assistant tasked with providing a comprehensive overview of the topic "${keyword}". In your explanation, describe what makes this subject fascinating by highlighting its significance, sharing any notable historical or amusing anecdotes, and outlining its key components. Ensure your response is engaging, clear, and easily digestible, keeping in mind that it will be used by another AI.
|
||||
`;
|
||||
const additionalContext = await requestWithRateLimitHandling(contextPrompt);
|
||||
|
||||
console.log(`🔍 Additional context retrieved: ${additionalContext.slice(0, 100)}...`);
|
||||
|
||||
console.log(`🆕 Generating new content for: ${keyword}`);
|
||||
|
||||
// Second AI request: Generate HTML using the additional context
|
||||
const prompt = `You are an AI web designer in 2025. Generate a fully structured, valid HTML5 webpage based on the keyword: "${keyword}". Use the following additional context for "${keyword}":
|
||||
${additionalContext}
|
||||
|
||||
Requirements:
|
||||
• Start with a proper <!DOCTYPE html> declaration and include well-formed <html>, <head>, and <body> sections.
|
||||
• Use Bootstrap for styling and layout—incorporate all of its components—and integrate FontAwesome icons.
|
||||
• Place all CSS inside <style></style> tags in the head; do not use external stylesheets.
|
||||
• Text content must be vast and informative.
|
||||
• Theme the page and its functionality to reflect the keyword. For example, if the keyword is "stopwatch," create a stopwatch app; if the keyword is "List App," build a list app. If a specific function is not clear, design a page that reflects ideas and concepts related to the keyword.
|
||||
• Use only SVG graphics (do not use images in other formats).
|
||||
• Design a rich, engaging layout with plenty of relevant, humorous, and meme-inspired content (emojis are welcome).
|
||||
• Include multiple interactive modals with unique content. All navigation should open modals (do not use anchor links or traditional navigation menus).
|
||||
• If possible, incorporate charts using Chart.js and display interesting tables.
|
||||
• Add cool effects and custom scrollbars where appropriate.
|
||||
• Do not add any "Learn More" or "Read More" buttons unless they open a modal.
|
||||
• Do not include any contact forms or any extra explanatory text.
|
||||
• The webpage URL is: https://${keyword}.autogen.space/
|
||||
• Output only the complete HTML code (with embedded CSS) for the webpage. Do not include any extra text, explanations, notes, or commentary.
|
||||
• Do not include the word “html” or any other text before the HTML code.
|
||||
• Do not include any note or code block at the end—only output the HTML code.`;
|
||||
|
||||
const generatedHTML = await requestWithRateLimitHandling(prompt);
|
||||
let replacedHTML = generatedHTML.replace(/[\s\S]*?/g, '');
|
||||
|
||||
// Store in cache
|
||||
cache.set(keyword, replacedHTML);
|
||||
saveCacheToDisk(); // Save to disk after updating cache
|
||||
|
||||
res.set('Content-Type', 'text/html');
|
||||
res.send(replacedHTML);
|
||||
} catch (error) {
|
||||
console.error('🚨 Error generating HTML:', error);
|
||||
res.status(500).send('Internal Server Error');
|
||||
}
|
||||
});
|
||||
```
|
||||
|
||||
**Workflow Breakdown:**
|
||||
|
||||
1. **Keyword Extraction:**
|
||||
- The hostname is parsed and segmented. For domains with multiple subdomains, the first subdomain (with dashes replaced by spaces) is used as the keyword.
|
||||
- If the domain does not match the expected format, a default keyword is applied.
|
||||
|
||||
2. **Cache Check:**
|
||||
- The cache is queried to see if an HTML page for the given keyword already exists. If found, the cached HTML is immediately served, improving response time.
|
||||
|
||||
3. **AI-Driven Context and HTML Generation:**
|
||||
- The first AI call generates additional context for the keyword, providing a rich background that informs the final HTML generation.
|
||||
- The second AI call uses this context to generate a fully structured HTML page. The generated code adheres strictly to specified constraints, ensuring a modern, engaging, and interactive webpage.
|
||||
|
||||
4. **Caching and Persistence:**
|
||||
- Once generated, the HTML is cached in memory and persisted to disk, ensuring that subsequent requests can bypass the expensive AI calls.
|
||||
- This step is critical for performance optimization, especially under heavy load.
|
||||
|
||||
5. **Error Handling:**
|
||||
- Any errors encountered during the process trigger a fallback mechanism, logging the error and returning a 500 status code.
|
||||
|
||||
|
||||
|
||||
### DNS and Virtual Host Configuration
|
||||
|
||||
A key enabler of the dynamic subdomain functionality in this system is the proper configuration of DNS and Virtual Hosts.
|
||||
|
||||
#### Wildcard DNS Entries
|
||||
|
||||
Since the application extracts keywords from the subdomain portion of the URL (e.g., `keyword.example.com`), a wildcard DNS entry is essential. Configuring an A record like:
|
||||
|
||||
```
|
||||
*.example.com IN A <your-server-IP>
|
||||
```
|
||||
|
||||
ensures that any subdomain request, regardless of the value before the domain (e.g., `foo.example.com`, `bar.example.com`), resolves to your server. This flexibility is critical for dynamically handling multiple tenant-like requests without needing separate DNS entries for each.
|
||||
|
||||
#### Wildcard Virtual Host
|
||||
|
||||
Equally important is the configuration of a wildcard Virtual Host on your web server (such as Nginx or Apache). For instance, an Nginx configuration block might look like this:
|
||||
|
||||
```nginx
|
||||
server {
|
||||
listen 80;
|
||||
server_name *.example.com;
|
||||
|
||||
location / {
|
||||
proxy_pass http://localhost:8998;
|
||||
proxy_set_header Host $host;
|
||||
proxy_set_header X-Real-IP $remote_addr;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
This configuration directs all subdomain requests to the Node.js application, ensuring that the extracted subdomain (i.e., the keyword) is available for processing. Without a wildcard Virtual Host, your server might only handle requests for a single domain, breaking the dynamic HTML generation workflow.
|
||||
|
||||
By integrating wildcard DNS entries and a wildcard Virtual Host, the system robustly supports multi-tenancy and ensures that every subdomain request reaches the application for dynamic processing.
|
||||
|
||||
|
||||
|
||||
## Error Handling, Rate Limiting, and Retry Strategy
|
||||
|
||||
Robust error handling is fundamental in distributed systems, especially when dealing with external APIs. In our application:
|
||||
|
||||
- **Categorization of Errors:**
|
||||
Errors are categorized based on their HTTP status codes:
|
||||
- **429 (Too Many Requests):** Indicates rate limiting, triggering an exponential backoff.
|
||||
- **408, 409, 5xx (Server Errors):** Also retried with increasing delays.
|
||||
|
||||
- **Exponential Backoff:**
|
||||
With each retry, the delay doubles, mitigating the risk of overwhelming the API further while increasing the chance that transient errors will resolve.
|
||||
|
||||
- **Retry Limit:**
|
||||
The application gives up after five attempts, ensuring that it doesn’t get stuck in an infinite loop. This allows the Express route to return a proper error response to the client.
|
||||
|
||||
|
||||
|
||||
## Advanced Considerations
|
||||
|
||||
Beyond the basic functionality, several advanced topics are worth exploring for a production-grade implementation.
|
||||
|
||||
### Scalability and Concurrency
|
||||
|
||||
- **Load Balancing:**
|
||||
In high-traffic scenarios, consider deploying multiple instances of the application behind a load balancer. This architecture ensures that requests are distributed evenly, reducing response times and improving reliability.
|
||||
|
||||
- **Cluster Mode:**
|
||||
Use Node.js's cluster module to spawn multiple worker processes on multi-core systems. This improves CPU utilization and can handle higher concurrency.
|
||||
|
||||
- **Distributed Caching:**
|
||||
For a horizontally scaled environment, in-memory caches like NodeCache might need to be replaced or supplemented with a distributed caching solution like Redis to maintain consistency across multiple instances.
|
||||
|
||||
### Security Considerations
|
||||
|
||||
- **API Key Management:**
|
||||
Ensure API keys and sensitive configurations are stored securely. Use environment variables or secrets management tools to avoid exposure.
|
||||
|
||||
- **Input Sanitization:**
|
||||
Although the AI prompts are largely pre-defined, always validate and sanitize any input derived from HTTP headers to prevent injection attacks.
|
||||
|
||||
- **HTTPS Enforcement:**
|
||||
Running the application behind a reverse proxy (like Nginx) with SSL/TLS ensures that all communications are secure.
|
||||
|
||||
### Monitoring and Observability
|
||||
|
||||
- **Logging:**
|
||||
Enhance the logging mechanism to include structured logs (JSON format) for better integration with log aggregators and monitoring tools.
|
||||
|
||||
- **Metrics and Alerts:**
|
||||
Integrate monitoring tools like Prometheus and Grafana to track API response times, error rates, and cache hit/miss ratios. Alerts can be set up to notify the operations team in case of abnormal behavior.
|
||||
|
||||
- **Tracing:**
|
||||
Implement distributed tracing (e.g., using OpenTelemetry) to gain insights into the end-to-end request flow, particularly useful when diagnosing performance issues or API bottlenecks.
|
||||
|
||||
## My thoughts
|
||||
|
||||
In this post we dissected a modern, AI-powered dynamic HTML generator built with Node.js. The application showcases several advanced engineering techniques:
|
||||
|
||||
- **Express Routing:**
|
||||
A flexible and powerful HTTP server that orchestrates the flow from incoming requests to dynamic content generation.
|
||||
|
||||
- **AI Integration via Groq SDK:**
|
||||
Leveraging AI to provide contextual understanding and to generate rich HTML content dynamically.
|
||||
|
||||
- **Efficient Caching Strategies:**
|
||||
Combining in-memory caching with disk persistence to minimize redundant API calls and reduce latency.
|
||||
|
||||
- **Robust Error Handling:**
|
||||
Implementing exponential backoff and retry strategies to gracefully manage API rate limits and transient errors.
|
||||
|
||||
- **Dynamic Subdomain Resolution:**
|
||||
The use of wildcard DNS entries and a wildcard Virtual Host is essential to direct all subdomain traffic to the application, enabling it to extract keywords dynamically and generate tailored content.
|
||||
|
||||
- **Advanced Engineering Considerations:**
|
||||
Addressing scalability, security, and observability to build a production-ready system.
|
||||
|
||||
This architecture is an excellent example of how modern web applications can harness AI to deliver highly personalized and interactive content in real time. Whether you’re building an AI assistant, a dynamic content generator, or an interactive web application, the patterns demonstrated here will guide you in designing resilient, scalable, and maintainable systems.
|
||||
|
||||
Happy coding!
|
||||
|
||||
@ -1,7 +1,7 @@
|
||||
<!-- lead -->
|
||||
Deep Dive: Automating Container Backups and Saving Space Using `docker export` and `docker import`
|
||||
|
||||
In modern infrastructure, Docker containers provide a lightweight and efficient way to run applications, but managing container storage, backups, and minimizing overhead can be complex. The method you are using to shrink running containers into new images by leveraging `docker export` and `docker import` provides an elegant solution to this challenge. This approach not only automates backups but also optimizes space usage. Let’s dive into the details of how it works and its potential applications.
|
||||
In modern infrastructure, Docker containers provide a lightweight and efficient way to run applications, but managing container storage, backups, and minimizing overhead can be complex. The method used in this article to shrink running containers into new images by leveraging `docker export` and `docker import` provides an elegant solution to this challenge. This approach not only automates backups but also optimizes space usage. Let’s dive into the details of how it works and its potential applications.
|
||||
|
||||
### Command Overview
|
||||
|
||||
|
||||
@ -0,0 +1,372 @@
|
||||
<!-- lead -->
|
||||
How I Built This Blog: A Deep Dive into Modern Web Development
|
||||
|
||||
A blog is one of the most powerful tools for sharing information, building authority, and engaging with an audience. When I decided to build a blog platform using **Node.js**, I wanted to go beyond the typical setup. I aimed for a feature-rich platform that dynamically serves content from Markdown files, supports pagination, integrates syntax highlighting for code snippets, offers a functional contact form with **reCAPTCHA** validation, generates **RSS** feeds and **sitemaps** for better SEO, and allows for customized pages like "About Me" to be loaded directly from Markdown files.
|
||||
|
||||
In this in-depth technical breakdown, I’ll walk you through every aspect of the platform’s architecture and code, explaining why I chose each technology and how the different parts work together. If you're looking to create your own blog platform or simply want to dive deeper into building dynamic web applications with **Node.js**, this post will cover everything in great detail.
|
||||
|
||||
# Source
|
||||
|
||||
https://git.ssh.surf/snxraven/ravenscott-blog
|
||||
|
||||
## Why Node.js and Express?
|
||||
|
||||
Before we get into the technical details, let's talk about the choice of technologies. I chose **Node.js** as the runtime because of its event-driven, non-blocking I/O model, which is great for building scalable and performant web applications. **Express.js**, a minimalist web framework for Node, simplifies the process of setting up a web server, routing requests, and serving static files.
|
||||
|
||||
Here’s why these choices make sense for this project:
|
||||
|
||||
- **Node.js**: Handles high-concurrency applications well, meaning it can efficiently serve multiple blog readers without performance bottlenecks.
|
||||
- **Express.js**: Provides a straightforward way to build a RESTful architecture for managing routes, handling form submissions, and rendering views dynamically.
|
||||
|
||||
## Folder Structure: Organizing the Blog Platform
|
||||
|
||||
One of the first things you need to think about when building a project is its structure. Here's a breakdown of the folder structure I used for this blog platform:
|
||||
|
||||
```
|
||||
/blog-platform
|
||||
│
|
||||
├── /markdown # Contains all blog posts written in Markdown
|
||||
│ └── post-1.md # Example Markdown blog post
|
||||
│
|
||||
├── /public # Public assets (CSS, images, etc.)
|
||||
│ └── /css
|
||||
│ └── styles.css # Custom styles for the blog
|
||||
│
|
||||
├── /views # EJS templates (HTML views rendered by the server)
|
||||
│ ├── index.ejs # Homepage template showing a list of blog posts
|
||||
│ ├── blog-post.ejs # Template for individual blog posts
|
||||
│ ├── about.ejs # "About Me" page (loaded from markdown)
|
||||
│ └── contact.ejs # Contact form page
|
||||
│
|
||||
├── /me # Personal markdown files (like About Me)
|
||||
│ └── about.md # Markdown file for the "About Me" page
|
||||
│
|
||||
├── app.js # Main server file, handles all backend logic
|
||||
├── package.json # Project dependencies and scripts
|
||||
├── .env # Environment variables (API keys, credentials, etc.)
|
||||
└── README.md # Documentation
|
||||
```
|
||||
|
||||
This structure provides a clear separation of concerns:
|
||||
|
||||
- **Markdown** files are stored in their own directory.
|
||||
- **Public** assets (CSS, images) are isolated for easy reference.
|
||||
- **Views** are where EJS templates are stored, allowing us to easily manage the HTML structure of each page.
|
||||
- **me** contains personal information like the **about.md** file, which gets rendered dynamically for the "About Me" page.
|
||||
- **app.js** acts as the control center, handling the routes, form submissions, and the logic for rendering content.
|
||||
|
||||
## Setting Up the Express Server
|
||||
|
||||
The core of the application is the **Express.js** server, which powers the entire backend. In `app.js`, we initialize Express, set up the middleware, and define the routes. But before we get into the route handling, let’s break down the middleware and configuration settings we used.
|
||||
|
||||
### 1. **Loading Dependencies**
|
||||
|
||||
Here are the key dependencies we load at the top of the file:
|
||||
|
||||
```javascript
|
||||
require('dotenv').config(); // Load environment variables from .env
|
||||
const express = require('express');
|
||||
const path = require('path');
|
||||
const fs = require('fs');
|
||||
const { marked } = require('marked'); // For parsing Markdown files
|
||||
const nodemailer = require('nodemailer'); // For sending emails from the contact form
|
||||
const hljs = require('highlight.js'); // For syntax highlighting in code blocks
|
||||
const axios = require('axios'); // For making HTTP requests, e.g., reCAPTCHA verification
|
||||
const { format } = require('date-fns'); // For formatting dates in RSS feeds and sitemaps
|
||||
|
||||
const app = express(); // Initialize Express
|
||||
```
|
||||
|
||||
Here’s what each dependency does:
|
||||
|
||||
- **dotenv**: Loads environment variables from a `.env` file, which we use to store sensitive information like API keys and email credentials.
|
||||
- **path** and **fs**: Standard Node.js modules that help us work with file paths and file systems. We use these to read Markdown files and serve static assets.
|
||||
- **marked**: A Markdown parser that converts Markdown syntax into HTML, allowing us to write blog posts using a simple syntax.
|
||||
- **nodemailer**: Handles sending emails when users submit the contact form.
|
||||
- **highlight.js**: Provides syntax highlighting for any code blocks in the blog posts. This is essential for making technical posts more readable.
|
||||
- **axios**: Used for making external HTTP requests (e.g., verifying the Google reCAPTCHA response).
|
||||
- **date-fns**: A utility for formatting dates, which we use to ensure dates are correctly formatted in RSS feeds and sitemaps.
|
||||
|
||||
### 2. **Setting Up Middleware and Template Engine**
|
||||
|
||||
Express makes it easy to set up middleware, which is crucial for handling static assets (like CSS files), parsing form data, and rendering templates using a view engine.
|
||||
|
||||
#### EJS Templating Engine
|
||||
|
||||
We use **EJS** as the templating engine. This allows us to embed JavaScript logic directly within our HTML, making it possible to render dynamic content like blog posts and form submission results.
|
||||
|
||||
```javascript
|
||||
app.set('view engine', 'ejs');
|
||||
app.set('views', path.join(__dirname, 'views'));
|
||||
```
|
||||
|
||||
This configuration tells Express to use the `views` folder for storing the HTML templates and `EJS` as the engine to render those templates.
|
||||
|
||||
#### Serving Static Files
|
||||
|
||||
Static files (like CSS and images) need to be served from the `/public` directory. This is where we store the CSS styles used to make the blog look visually appealing.
|
||||
|
||||
```javascript
|
||||
app.use(express.static(path.join(__dirname, 'public')));
|
||||
```
|
||||
|
||||
#### Parsing Form Data
|
||||
|
||||
When users submit the contact form, the form data is sent as **URL-encoded** data. To handle this, we use `express.urlencoded` middleware, which parses the form submissions and makes the data accessible via `req.body`.
|
||||
|
||||
```javascript
|
||||
app.use(express.urlencoded({ extended: false }));
|
||||
```
|
||||
|
||||
## Markdown Parsing with Syntax Highlighting
|
||||
|
||||
One of the primary features of this blog platform is that it allows you to write blog posts using **Markdown**. Markdown is a simple markup language that converts easily to HTML and is especially popular among developers because of its lightweight syntax for writing formatted text.
|
||||
|
||||
### 1. **Setting Up `marked` and `highlight.js`**
|
||||
|
||||
To convert Markdown content to HTML, I used **Marked.js**, a fast and lightweight Markdown parser. Additionally, since many blog posts contain code snippets, **Highlight.js** is used to provide syntax highlighting for those snippets.
|
||||
|
||||
```javascript
|
||||
marked.setOptions({
|
||||
highlight: function (code, language) {
|
||||
const validLanguage = hljs.getLanguage(language) ? language : 'plaintext';
|
||||
return hljs.highlight(validLanguage, code).value;
|
||||
}
|
||||
});
|
||||
```
|
||||
|
||||
This makes code blocks in blog posts more readable by colorizing keywords, variables, and other syntax elements, which improves the user experience, especially for technical blogs.
|
||||
|
||||
### 2. **Loading the 'About Me' Page from Markdown**
|
||||
|
||||
To create a more personalized "About Me" page, I stored the content in a Markdown file (`me/about.md`) and dynamically rendered it with Express. Here's how we load the `about.md` file and render it using **EJS**:
|
||||
|
||||
```javascript
|
||||
app.get('/about', (req, res) => {
|
||||
const aboutMarkdownFile = path.join(__dirname, 'me', 'about.md');
|
||||
|
||||
// Read the markdown file and convert it to HTML
|
||||
fs.readFile(aboutMarkdownFile, 'utf-8', (err, data) => {
|
||||
if (err) {
|
||||
return res.status(500).send('Error loading About page');
|
||||
}
|
||||
|
||||
const aboutContentHtml = marked(data); // Convert markdown to HTML
|
||||
|
||||
res.render('about', {
|
||||
title: `About ${process.env.OWNER_NAME}`,
|
||||
content: aboutContentHtml
|
||||
});
|
||||
});
|
||||
});
|
||||
```
|
||||
|
||||
## Blog Post Storage and Rendering
|
||||
|
||||
### 1. **Storing Blog Posts as Markdown Files**
|
||||
|
||||
Instead of storing blog posts in a database, this platform uses a simpler approach: each blog post is a `.md` file stored in the `/markdown` directory. This approach is not only easier to manage, but it also gives writers the flexibility to create and update posts using any text editor.
|
||||
|
||||
### 2. **Rendering Markdown as HTML**
|
||||
|
||||
To render the Markdown content as HTML on the frontend, we define a function `loadMarkdownWithLead` that reads the Markdown file, parses it, and extracts the lead section if available.
|
||||
|
||||
```js
|
||||
function loadMarkdownWith
|
||||
|
||||
Lead(file) {
|
||||
const markdownContent = fs.readFileSync(path.join(__dirname, 'markdown', file), 'utf-8');
|
||||
|
||||
let lead = '';
|
||||
let contentMarkdown = markdownContent;
|
||||
|
||||
// Extract the lead section marked by `<-!-- lead -->`
|
||||
const leadKeyword = '<-!-- lead -->';
|
||||
if (contentMarkdown.includes(leadKeyword)) {
|
||||
const [beforeLead, afterLead] = contentMarkdown.split(leadKeyword);
|
||||
lead = afterLead.split('\n').find(line => line.trim() !== '').trim();
|
||||
contentMarkdown = beforeLead + afterLead.replace(lead, '').trim();
|
||||
}
|
||||
|
||||
const contentHtml = marked.parse(contentMarkdown);
|
||||
return { contentHtml, lead };
|
||||
}
|
||||
```
|
||||
|
||||
### 3. **Dynamically Rendering Blog Posts**
|
||||
|
||||
For each blog post, we generate a URL based on its title (converted to a slug format). The user can access a blog post by navigating to `/blog/{slug}`, where `{slug}` is the URL-friendly version of the title.
|
||||
|
||||
```javascript
|
||||
app.get('/blog/:slug', (req, res) => {
|
||||
const slug = req.params.slug;
|
||||
const markdownFile = fs.readdirSync(path.join(__dirname, 'markdown'))
|
||||
.find(file => titleToSlug(file.replace('.md', '')) === slug);
|
||||
|
||||
if (markdownFile) {
|
||||
const originalTitle = markdownFile.replace('.md', '');
|
||||
const { contentHtml, lead } = loadMarkdownWithLead(markdownFile);
|
||||
|
||||
res.render('blog-post', {
|
||||
title: originalTitle,
|
||||
content: contentHtml,
|
||||
lead: lead
|
||||
});
|
||||
} else {
|
||||
res.redirect('/');
|
||||
}
|
||||
});
|
||||
```
|
||||
|
||||
### 4. **Slug Generation for Blog Posts**
|
||||
|
||||
The title of each post is converted into a URL-friendly slug, which is used in the post's URL. Here's the utility function for converting a title into a slug:
|
||||
|
||||
```javascript
|
||||
function titleToSlug(title) {
|
||||
return title.toLowerCase()
|
||||
.replace(/[^a-z0-9\s-]/g, '') // Remove non-alphanumeric characters
|
||||
.replace(/\s+/g, '-'); // Replace spaces with dashes
|
||||
}
|
||||
```
|
||||
|
||||
This ensures that each blog post URL is clean and readable, with no special characters or extra whitespace.
|
||||
|
||||
## Adding Search Functionality
|
||||
|
||||
I’ve implemented a search feature that allows users to search for blog posts by title. The search functionality reads through all the Markdown filenames and returns posts that match the search query.
|
||||
|
||||
```javascript
|
||||
function getAllBlogPosts(page = 1, postsPerPage = 5, searchQuery = '') {
|
||||
let blogFiles = fs.readdirSync(path.join(__dirname, 'markdown')).filter(file => file.endsWith('.md'));
|
||||
|
||||
if (searchQuery) {
|
||||
const lowerCaseQuery = searchQuery.toLowerCase();
|
||||
blogFiles = blogFiles.filter(file => file.toLowerCase().includes(lowerCaseQuery));
|
||||
}
|
||||
|
||||
if (blogFiles.length === 0) {
|
||||
return { blogPosts: [], totalPages: 0 }; // Return empty results if no files
|
||||
}
|
||||
|
||||
blogFiles.sort((a, b) => {
|
||||
const statA = fs.statSync(path.join(__dirname, 'markdown', a)).birthtime;
|
||||
const statB = fs.statSync(path.join(__dirname, 'markdown', b)).birthtime;
|
||||
return statB - statA;
|
||||
});
|
||||
|
||||
const totalPosts = blogFiles.length;
|
||||
const totalPages = Math.ceil(totalPosts / postsPerPage);
|
||||
const start = (page - 1) * postsPerPage;
|
||||
const end = start + postsPerPage;
|
||||
|
||||
const paginatedFiles = blogFiles.slice(start, end);
|
||||
|
||||
const blogPosts = paginatedFiles.map(file => {
|
||||
const title = file.replace('.md', '').replace(/-/g, ' ');
|
||||
const slug = titleToSlug(title);
|
||||
const stats = fs.statSync(path.join(__dirname, 'markdown', file));
|
||||
const dateCreated = new Date(stats.birthtime);
|
||||
|
||||
return { title, slug, dateCreated };
|
||||
});
|
||||
|
||||
return { blogPosts, totalPages };
|
||||
}
|
||||
```
|
||||
|
||||
The search query is passed through the route and displayed dynamically on the homepage with the search results.
|
||||
|
||||
```javascript
|
||||
app.get('/', (req, res) => {
|
||||
const page = parseInt(req.query.page) || 1;
|
||||
const searchQuery = req.query.search || '';
|
||||
|
||||
if (page < 1) {
|
||||
return res.redirect(req.hostname);
|
||||
}
|
||||
|
||||
const postsPerPage = 5;
|
||||
const { blogPosts, totalPages } = getAllBlogPosts(page, postsPerPage, searchQuery);
|
||||
|
||||
const noResults = blogPosts.length === 0; // Check if there are no results
|
||||
|
||||
res.render('index', {
|
||||
title: `${process.env.OWNER_NAME}'s Blog`,
|
||||
blogPosts,
|
||||
currentPage: page,
|
||||
totalPages,
|
||||
searchQuery, // Pass search query to the view
|
||||
noResults // Pass this flag to indicate no results found
|
||||
});
|
||||
});
|
||||
```
|
||||
|
||||
In the `index.ejs` file, the search form dynamically updates the results, and the pagination controls help users navigate between pages.
|
||||
|
||||
```html
|
||||
<form action="/" method="get" class="mb-4">
|
||||
<div class="input-group">
|
||||
<input type="text" name="search" class="form-control" placeholder="Search blog posts..." value="<%= typeof searchQuery !== 'undefined' ? searchQuery : '' %>">
|
||||
</div>
|
||||
</form>
|
||||
```
|
||||
|
||||
## Environment Variable Customization
|
||||
|
||||
The `.env` file contains all the configuration settings for the site, making it easy to change things like the owner's name, email settings, and URLs without modifying the code.
|
||||
|
||||
Here’s a breakdown of the relevant `.env` variables:
|
||||
|
||||
```env
|
||||
# SMTP configuration for sending emails
|
||||
SMTP_HOST=us2.smtp.yourtld.com # SMTP server host
|
||||
SMTP_PORT=587 # SMTP server port
|
||||
EMAIL_USER=user@yourtld.com # Email address used for SMTP authentication
|
||||
EMAIL_PASS="ComplexPass" # Password for the SMTP user
|
||||
RECEIVER_EMAIL=youremail@yourtld.com # Default receiver email for outgoing messages
|
||||
|
||||
# CAPTCHA key for form verification
|
||||
CAPTCHA_SECRET_KEY="KEYHERE"
|
||||
|
||||
# URL configuration
|
||||
HOST_URL="https://yourtld.com" # Base host URL
|
||||
BLOG_URL="https://blog.yourtld.com/" # Blog URL (with trailing slash)
|
||||
|
||||
# Website branding
|
||||
SITE_NAME="Your Blog Title" # Title used in the website's navbar
|
||||
OWNER_NAME="Your Name" # Name of the website's owner (you)
|
||||
|
||||
# Front page content
|
||||
FRONT_PAGE_TITLE="Hello, my name is Your Name" # Main heading on the homepage
|
||||
FRONT_PAGE_LEAD="Where Technology Meets Creativity: Insights from a Linux Enthusiast" # Lead text on the homepage
|
||||
|
||||
# Footer content
|
||||
FOOTER_TAGLINE="Never Stop Learning" # Tagline for the footer
|
||||
```
|
||||
|
||||
# Final Thoughts
|
||||
|
||||
By leveraging **Node.js**, **Express**, **EJS**, and **Markdown**, this blog platform demonstrates how you can combine modern, lightweight technologies to build a dynamic, feature-rich website that is both scalable and easy to maintain. These technologies work together to offer a seamless development experience, allowing you to focus on creating content and functionality rather than worrying about performance bottlenecks or complex configurations.
|
||||
|
||||
**Node.js** is renowned for its event-driven, non-blocking architecture, making it perfect for real-time applications and websites that require high concurrency. It allows the platform to handle multiple users and requests simultaneously without compromising performance. This is crucial for blogs or websites with growing traffic, where responsiveness and speed are essential to user experience. The efficiency of Node.js, along with its ability to unify backend and frontend development through JavaScript, creates a cohesive environment that is both efficient and developer-friendly. Whether scaling the application for higher traffic or deploying updates quickly, Node.js provides a fast, reliable runtime.
|
||||
|
||||
**Express.js** simplifies the challenges of building a backend server. Its minimalist design allows for easy routing, middleware configuration, and management of HTTP requests. In this blog platform, Express plays a key role in routing different parts of the site, such as serving static assets, rendering dynamic content with EJS, handling form submissions, and integrating security features like reCAPTCHA in the contact form. Express is designed to be flexible and extendable, allowing you to integrate additional functionality like authentication, session management, or third-party APIs with minimal effort. Its built-in support for middleware also enables developers to easily add features or customize existing ones, making the platform adaptable to evolving needs.
|
||||
|
||||
**EJS (Embedded JavaScript Templates)** is used to render dynamic content within HTML, making it easy to inject variables and logic directly into views. In this project, EJS powers the dynamic rendering of blog posts, search results, pagination, and custom pages like the "About Me" section. By allowing us to integrate JavaScript logic directly into HTML templates, EJS enables a more interactive and personalized user experience. It also supports the reuse of templates, which helps to keep the code clean and modular. The familiarity of EJS with standard HTML means developers can quickly get up to speed without learning an entirely new templating language.
|
||||
|
||||
The use of **Markdown** as the primary format for content creation offers simplicity and flexibility. Storing blog posts in Markdown files removes the need for a complex database, making the platform lightweight and easy to manage. Markdown’s intuitive syntax allows content creators to focus on writing, while the platform automatically handles formatting and presentation. When paired with tools like **Marked.js**, Markdown becomes even more powerful, as it allows for easy conversion from plain text into rich HTML. This setup is particularly useful for technical blogs, where code snippets are often embedded. By integrating **highlight.js**, the platform ensures that code blocks are both functional and beautifully presented, making the reading experience more enjoyable and accessible for developers and technical audiences.
|
||||
|
||||
This combination of technologies unlocks several powerful features that enhance both the user experience and the development process. With **dynamic content rendering**, the platform efficiently serves blog posts, handles search queries, and manages pagination on the fly. The content is written and stored in Markdown files, but it’s transformed into fully styled HTML at the moment of request, allowing for quick updates and modifications. This approach not only makes content management easier but also ensures that users always see the most up-to-date version of the blog without requiring database queries or complex caching mechanisms.
|
||||
|
||||
The **flexibility and extendability** of this platform are key advantages. Whether you want to add new features, such as a gallery or portfolio section, or integrate external services like a newsletter or analytics platform, the modular structure of Express and the use of EJS templates make this process straightforward. Adding a new feature is as simple as creating a new Markdown file and a corresponding EJS template, enabling rapid development and easy customization. This makes the platform ideal for developers who want to scale or expand their site over time without worrying about technical debt.
|
||||
|
||||
A key principle of this platform is **separation of concerns**, which ensures that the content, logic, and presentation are kept distinct. Blog posts are stored as Markdown files, static assets like CSS and images are kept in their own directory, and the logic for handling routes and rendering views is managed in the Express app. This makes the platform highly maintainable, as changes to one part of the system don’t affect other parts. For instance, you can easily update the styling of the blog without changing the logic that handles blog posts or search functionality.
|
||||
|
||||
Furthermore, **performance and security** are built into the platform from the start. Node.js’s asynchronous, non-blocking architecture ensures that the platform can handle high levels of concurrency with minimal latency. Meanwhile, Express allows for easy integration of security features like **reCAPTCHA**, ensuring that spam submissions are minimized. The use of environment variables stored in a `.env` file means sensitive information, like email credentials and API keys, is kept secure and easily configurable. This approach not only enhances security but also simplifies the deployment process, as configurations can be adjusted without changing the codebase.
|
||||
|
||||
One of the standout features of this platform is its **search functionality**. Users can easily search for blog posts by title, with results rendered dynamically based on the query. This is made possible through the flexible routing capabilities of Express, combined with the simplicity of searching through Markdown filenames. The integration of search functionality elevates the user experience, providing quick access to relevant content while maintaining a responsive interface.
|
||||
|
||||
Finally, the **environmental customizations** enabled by the `.env` file make the platform incredibly versatile. The `.env` file stores crucial configuration details such as email server settings, CAPTCHA keys, and URLs, allowing these values to be updated without modifying the application’s source code. This separation of configuration and logic streamlines deployment and maintenance, especially when migrating the platform to different environments or adjusting for production and development needs. By externalizing configuration, the platform can be easily adapted to different hosting environments, whether it’s deployed on a local server, a cloud service, or a dedicated VPS.
|
||||
|
||||
In conclusion, this blog platform showcases how **Node.js**, **Express**, **EJS**, and **Markdown** can be combined to create a robust, feature-rich website that is highly adaptable to various content needs. From dynamic blog posts to customizable pages like "About Me," to integrated search functionality and secure contact forms, this platform provides a flexible and efficient solution for content creators, developers, and businesses alike. Its scalability, maintainability, and performance make it a perfect choice for anyone looking to build a modern, high-performance blog or content management system.
|
||||
@ -0,0 +1,306 @@
|
||||
<!-- lead -->
|
||||
Building the My-MC.link Control Panel: A Deep Dive into Its Development and Impact
|
||||
|
||||
The **My-MC.link Control Panel** is a custom-built, feature-rich dashboard designed to manage Minecraft servers with unparalleled ease and efficiency. By integrating seamlessly into the My-MC.link ecosystem, this control panel empowers users to monitor server performance, manage players, configure server properties, and handle mods, all within a sleek, modern interface. In this blog post, we’ll explore the technical intricacies of how the panel was coded, how it functions, and why developing a bespoke solution for My-MC.link is a game-changer for server administrators.
|
||||
|
||||
# Source: https://git.ssh.surf/hypermc/panel
|
||||
|
||||
### API Docs (Main Service Integration): https://info.my-mc.link/api/
|
||||
|
||||
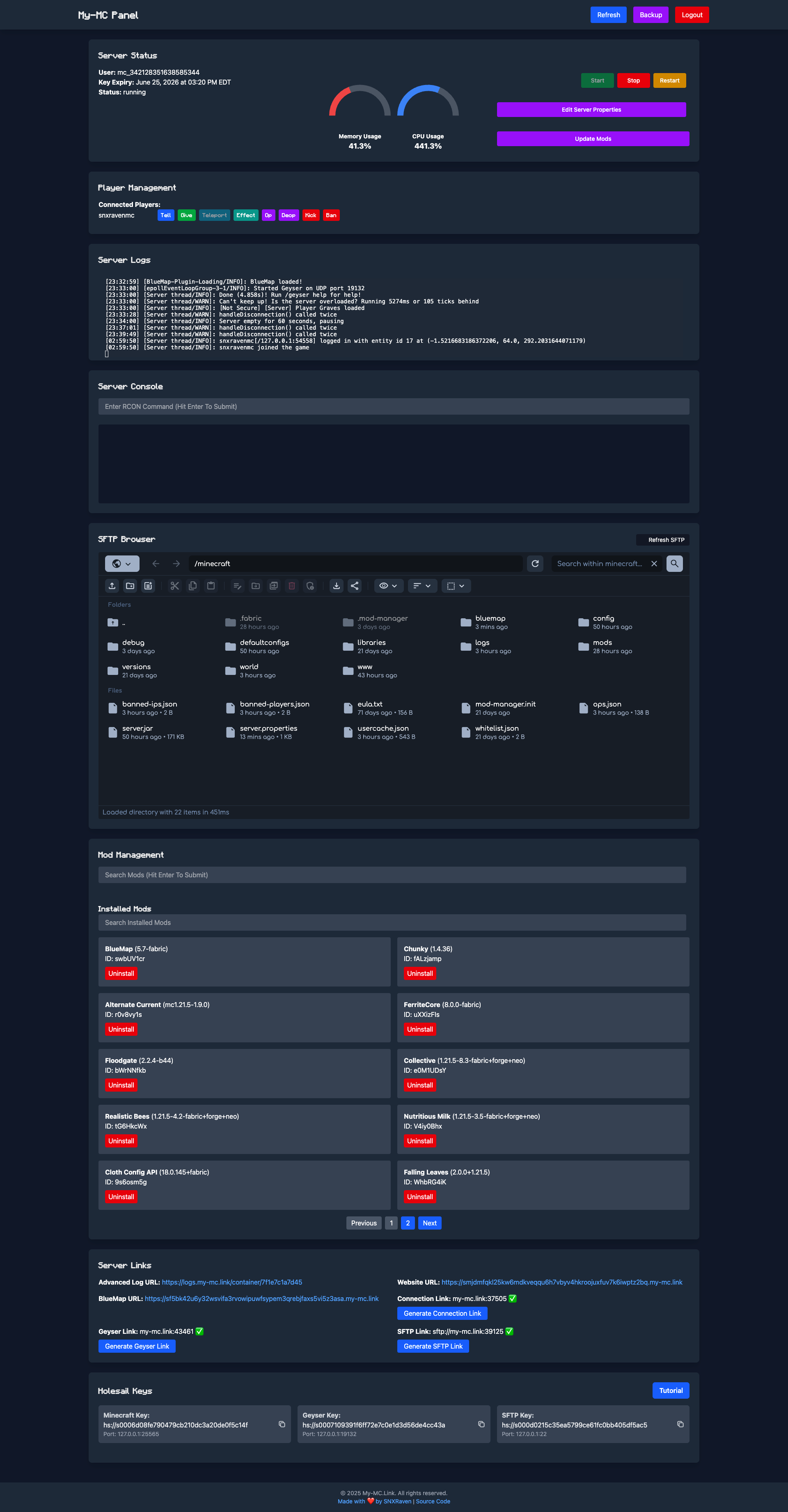
|
||||
|
||||
## Overview of the My-MC.link Control Panel
|
||||
|
||||
The My-MC.link Control Panel is a web-based application that provides a centralized interface for managing Minecraft servers hosted on the My-MC.link platform. Built using a modern tech stack, it leverages **Node.js**, **Express**, **WebSocket**, and **Docker** on the backend, paired with a responsive **HTML/CSS/JavaScript** frontend powered by libraries like **Chart.js** and **xterm.js**. The panel supports real-time server monitoring, player management, mod installation, SFTP file access, and automated backups, making it a powerful tool for both novice and experienced server administrators.
|
||||
|
||||
The decision to custom-code this panel was driven by the need for tight integration with My-MC.link’s infrastructure, ensuring optimal performance, security, and flexibility tailored to the platform’s unique requirements. Let’s break down the development process, key components, and why this custom solution stands out.
|
||||
|
||||
## Technical Architecture
|
||||
|
||||
### Backend: Node.js, Express, and WebSocket
|
||||
|
||||
The backend is built using **Node.js** with **Express** as the web framework, providing a robust foundation for handling HTTP requests and serving the frontend. The `server.js` file is the entry point, setting up an Express server with middleware like **CORS** for cross-origin requests, **helmet** for security headers, and **csurf** for CSRF protection. It also integrates a **WebSocketServer** (using the `ws` library) for real-time communication, enabling features like live server logs and status updates.
|
||||
|
||||
Key backend components include:
|
||||
|
||||
- **Docker Integration (`includes/docker.js`)**: The panel interacts with Docker containers via the `dockerode` library to manage Minecraft server instances. Functions like `getContainerStats`, `streamContainerLogs`, `readServerProperties`, `writeServerProperties`, `updateMods`, and `createBackup` provide comprehensive control over server operations, such as monitoring CPU/memory usage, streaming logs, and handling server configurations.
|
||||
|
||||
- **Authentication (`includes/auth.js`)**: Secure authentication is implemented using temporary login links generated via `generateLoginLink` and validated with `handleAutoLogin`. The system uses **HMAC-SHA256** for token generation, **rate-limiting** to prevent abuse, and **sanitize-html** to mitigate XSS risks. Environment variables ensure secure configuration, with validation for critical variables like `ADMIN_SECRET_KEY`.
|
||||
|
||||
- **WebSocket Handling (`includes/websocket.js`)**: The WebSocket module manages real-time communication, handling subscriptions to endpoints like `docker`, `docker-logs`, and `list-players`. It supports dynamic updates (e.g., server status, player lists) and static data (e.g., server links). The system uses a `clients` Map to track active WebSocket connections, ensuring efficient resource management and cleanup on disconnection.
|
||||
|
||||
- **API Requests (`includes/api.js`)**: The `apiRequest` function abstracts HTTP requests to external APIs, using `node-fetch` with custom headers for authentication. It handles errors gracefully, returning JSON responses with clear success/failure indicators.
|
||||
|
||||
- **Status Checks (`includes/status.js`)**: This module monitors server connectivity for Minecraft, Geyser, and SFTP services using external tools and socket connections. It ensures real-time status updates, such as whether the server is online or offline.
|
||||
|
||||
### Frontend: HTML, CSS, and JavaScript
|
||||
|
||||
The frontend, defined in `public/index.html` and `public/js/app.js`, is a single-page application (SPA) designed for responsiveness and interactivity. It uses **Tailwind CSS** for styling, **Chart.js** for visualizing server metrics (CPU/memory usage), and **xterm.js** for a terminal-like interface to display server logs. The JavaScript code manages WebSocket connections, UI updates, and user interactions.
|
||||
|
||||
Key frontend features include:
|
||||
|
||||
- **Real-Time Monitoring**: The panel displays CPU and memory usage via doughnut charts, updated in real-time through WebSocket messages. Server logs are streamed to a terminal interface, providing immediate feedback on server activity.
|
||||
|
||||
- **Player Management**: Users can view connected players, send messages, give items, apply effects, teleport players, and perform administrative actions (kick, ban, op, deop) with intuitive buttons and modals.
|
||||
|
||||
- **Mod Management**: The panel supports searching, installing, and uninstalling mods via a search interface and a paginated list of installed mods, leveraging the `/search`, `/install`, and `/uninstall` API endpoints.
|
||||
|
||||
- **SFTP Browser**: An iframe-based SFTP client allows file management without external tools, using a secure auto-connection mechanism.
|
||||
|
||||
- **Server Configuration**: Users can edit `server.properties` through a dynamic form, with filtered settings to prevent accidental changes to critical configurations.
|
||||
|
||||
### SFTP Integration
|
||||
|
||||
The SFTP Browser is a powerful web-based file management tool that enables seamless interaction with SFTP servers directly within the browser. Forked from [kaysting/sftp-browser](https://github.com/kaysting/sftp-browser), it provides a robust interface for navigating, uploading, downloading, and managing files on remote servers. We further enhance this tool with the following features: The backend leverages a temporary connection ID system via the `/auto-connection` endpoint to establish secure SFTP sessions without exposing sensitive credentials. The frontend, implemented in `public/js/app.js`, integrates with internal hostname entries to deliver a responsive, browser-based file explorer. Connection details are stored temporarily on the server (with a 12-hour expiration) and in the client’s `localStorage` for persistence across sessions, ensuring both security and usability.
|
||||
|
||||
#### Source: [git.ssh.surf/hypermc/sftp-browser](https://git.ssh.surf/hypermc/sftp-browser)
|
||||
|
||||
## How It Works
|
||||
|
||||
### Key Features
|
||||
- **Cross-Platform SFTP Connectivity**: Connect to SFTP servers hosted on any platform with support for password or private key authentication.
|
||||
- **Connection Management**: Import/export server connections and manage them via unique connection IDs, with auto-connection URLs (`/connect/:connectionId`) for credential-free access.
|
||||
- **File Operations**: Navigate directories, sort files, show/hide hidden files, and switch between list/tile views. Supports drag-and-drop uploads, multi-file downloads as zip, and cut/copy/paste functionality.
|
||||
- **File Editing and Viewing**: Edit text and Markdown files with syntax highlighting and live previews, and view images, videos, and audio files directly in the browser.
|
||||
- **Security Measures**: Temporary connection storage with a 12-hour expiration, duplicate connection prevention, and internal IP management for secure Docker container communication.
|
||||
- **Mobile Support**: Fully responsive UI for seamless use on mobile devices.
|
||||
- **API-Driven**: JSON-based API endpoints for all operations, with clear success/error responses and authentication headers for secure server communication.
|
||||
|
||||
### Authentication Flow
|
||||
|
||||
1. **Login Link Generation**:
|
||||
- On Page load, the panel initiates a connection by sending the users SFTP Details to the `/auto-connection` endpoint.
|
||||
- The backend validates the secret key, generates a secure token using HMAC-SHA256, and stores it in a `temporaryLinks` Map with an expiration time.
|
||||
- A unique `connectionId` is generated and returned with a URL in the format `https://sftp.my-mc.link/connect/:connectionId`.
|
||||
- The connect URL is then injected as an iFrame within the panel
|
||||
- An easy to use one-click button is provided to refresh the SFTP iFrames state if desired.
|
||||
|
||||
2. **Auto-Connection**:
|
||||
- When users access the `/connect/:connectionId` URL, the backend verifies the `connectionId` and retrieves the associated connection details (host, port, username, password/private key).
|
||||
- Connection details are stored temporarily on the server (12-hour expiration) and in the client’s `localStorage` to enable persistent sessions.
|
||||
- The client uses the stored API key to authenticate WebSocket connections for file operations.
|
||||
- Duplicate connections are prevented by clearing existing connections when a new `/connect/:connectionId` URL is accessed.
|
||||
|
||||
3. **Internal Container IP Management**:
|
||||
- The hostOS dynamically tracks internal Docker container IPs and dynamically updates the host node’s `/etc/hosts` file to map container hostnames to their internal IPs. Example:
|
||||
```
|
||||
# --- DOCKER CONTAINERS START ---
|
||||
172.18.0.4 mc_612395330851307520
|
||||
172.18.0.3 mc_132057503071600640
|
||||
172.18.0.2 mc_342128351638585344
|
||||
# --- DOCKER CONTAINERS END ---
|
||||
```
|
||||
- This allows secure internal SFTP connections without exposing external IPs, enhancing security by limiting unauthorized access.
|
||||
- Hostnames in `/etc/hosts` are used in stored credentials, supporting dynamic IP assignments within Docker.
|
||||
|
||||
This is done via a custom service within the Linux Host:
|
||||
|
||||
```bash
|
||||
#!/bin/bash
|
||||
|
||||
START_MARK="# --- DOCKER CONTAINERS START ---"
|
||||
END_MARK="# --- DOCKER CONTAINERS END ---"
|
||||
HOSTS_FILE="/etc/hosts"
|
||||
TMP_FILE="/tmp/docker-hosts.tmp"
|
||||
|
||||
# Root check
|
||||
if [ "$(id -u)" -ne 0 ]; then
|
||||
echo "This script must be run as root."
|
||||
exit 1
|
||||
fi
|
||||
|
||||
# Collect Docker container IP/name pairs
|
||||
docker ps -q | while read -r cid; do
|
||||
name=$(docker inspect --format '{{.Name}}' "$cid" | sed 's#^/##')
|
||||
ip=$(docker inspect -f '{{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}' "$cid")
|
||||
if [ -n "$ip" ] && [ -n "$name" ]; then
|
||||
echo "$ip $name"
|
||||
fi
|
||||
done > "$TMP_FILE"
|
||||
|
||||
# If no containers are running, we still want an empty block
|
||||
[ ! -s "$TMP_FILE" ] && echo "" > "$TMP_FILE"
|
||||
|
||||
# Create a new version of the hosts file
|
||||
awk -v start="$START_MARK" -v end="$END_MARK" '
|
||||
BEGIN { inblock = 0 }
|
||||
$0 == start { inblock = 1; print start; while ((getline line < "/tmp/docker-hosts.tmp") > 0) print line; print end; skip = 1; next }
|
||||
$0 == end { inblock = 0; skip = 1; next }
|
||||
skip == 1 && $0 != end { next }
|
||||
{ print }
|
||||
' "$HOSTS_FILE" > "${HOSTS_FILE}.new"
|
||||
|
||||
# If no start marker found, append block to the end
|
||||
if ! grep -qF "$START_MARK" "$HOSTS_FILE"; then
|
||||
echo "$START_MARK" >> "${HOSTS_FILE}.new"
|
||||
cat "$TMP_FILE" >> "${HOSTS_FILE}.new"
|
||||
echo "$END_MARK" >> "${HOSTS_FILE}.new"
|
||||
fi
|
||||
|
||||
# Move new file into place
|
||||
mv "${HOSTS_FILE}.new" "$HOSTS_FILE"
|
||||
rm -f "$TMP_FILE"
|
||||
```
|
||||
|
||||
4. **Optional External SFTP Access**:
|
||||
- Users can start a free Jump Host SFTP Port for external access using clients like FileZilla or WinSCP, providing flexibility to the users.
|
||||
|
||||
### Security Measures
|
||||
- **Temporary Connection Storage**: Connection details are stored server-side for only 12 hours, reducing the risk of unauthorized access.
|
||||
- **Secure Token Generation**: HMAC-SHA256 tokens ensure login links are tamper-proof and time-limited.
|
||||
- **Client-Side Security**: Credentials are stored in `localStorage` only for the duration of the session, with automatic cleanup on new connections.
|
||||
|
||||
### My-MC.Link Real-Time Updates
|
||||
|
||||
The WebSocket connection is the backbone of the panel’s real-time capabilities.
|
||||
|
||||
Upon connecting, the client subscribes to multiple endpoints (`docker`, `docker-logs`, `list-players`, etc.).
|
||||
|
||||
The backend pushes updates for:
|
||||
|
||||
- **Server Metrics**: CPU and memory usage are polled every second and sent to the client, updating the Chart.js doughnut charts.
|
||||
- **Logs**: Docker container logs are streamed to the xterm.js terminal, with cleanup to remove timestamps and color codes for readability.
|
||||
- **Player Lists**: The `/list-players` endpoint provides real-time updates on connected players, enabling dynamic management actions.
|
||||
- **Status Checks**: The panel monitors Minecraft, Geyser, and SFTP connectivity, displaying status icons (✅/❌) to indicate online/offline states.
|
||||
|
||||
### Docker Integration
|
||||
|
||||
The panel interacts with Docker containers to manage Minecraft servers.
|
||||
|
||||
Each user is associated with a specific container (named after their username), allowing the panel to:
|
||||
|
||||
- Retrieve real-time stats (CPU/memory usage) using `getContainerStats`.
|
||||
- Stream logs with `streamContainerLogs`, handling reconnection if the container restarts.
|
||||
- Read and write `server.properties` using `readServerProperties` and `writeServerProperties`.
|
||||
- Update mods with `updateMods`, executing a `mod-manager update` command in the container.
|
||||
- Create backups with `createBackup`, generating a download URL for the backup file.
|
||||
|
||||
### Mod Management
|
||||
|
||||
The Mod Management system integrates with an external CLI utility—**mod-manager**—to provide streamlined control over mods on Fabric Minecraft Servers. This system interfaces with Modrinth and Curseforge APIs to support installing, updating, and migrating mods. This tool integrates with the panel via the built in docker integration.
|
||||
|
||||
## Source: https://git.ssh.surf/snxraven/mod-manager
|
||||
|
||||
#### Frontend Panel Behavior
|
||||
|
||||
* **Search Interface**: Users can search for mods with debounced input, providing a smooth experience.
|
||||
* **Pagination**: Both search results and installed mods are paginated to maintain performance and usability.
|
||||
* **Action Guarding**: Mod-related operations are only allowed on running containers to ensure stability.
|
||||
|
||||
#### Backend Functionality
|
||||
|
||||
* Validates container state before proceeding with install, uninstall, update, or migration commands.
|
||||
* Interacts with `mod-manager`, a local CLI utility installed at `/home/mc/minecraft/mod-manager`.
|
||||
|
||||
### About `mod-manager`
|
||||
|
||||
A Node.js- and Shell-based CLI tool for managing Fabric Minecraft Server mods with package-manager-like features.
|
||||
|
||||
#### 🔧 Key Features
|
||||
|
||||
* Install mods from **Modrinth** and **Curseforge**
|
||||
* Uninstall installed mods
|
||||
* Update mods with a single command
|
||||
* Migrate mods to a new Minecraft version
|
||||
* Mark mods as essential (prevent unintentional removal)
|
||||
|
||||
|
||||
### 🧪 Usage Examples
|
||||
|
||||
```bash
|
||||
# Initialize mod-manager
|
||||
$ mod-manager init
|
||||
? What Minecraft version is your server running? 1.19.1
|
||||
✔ Successfully initialised Mod Manager!
|
||||
|
||||
# Install a mod (e.g., Lithium)
|
||||
$ mod-manager install lithium
|
||||
✔ Successfully installed Lithium
|
||||
|
||||
# List installed mods
|
||||
$ mod-manager list
|
||||
Name | Id | File Name | Version | Source | Essential | Dependencies
|
||||
-------------------------------------------------------------------------------------------------------------
|
||||
Lithium | gvQqBUqZ | lithium-fabric-mc1.19.2-0.8.3.jar | mc1.19.2-0.8.3 | Modrinth | false |
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
### 🖥️ Commands
|
||||
|
||||
```bash
|
||||
Usage: mod-manager [options] [command]
|
||||
|
||||
A package (mod) manager for Fabric Minecraft Servers
|
||||
|
||||
Options:
|
||||
-v, --version Reports the server's Minecraft version
|
||||
-h, --help Displays help
|
||||
|
||||
Commands:
|
||||
init Initializes mod-manager
|
||||
install [options] <mods...> Installs one or more mods
|
||||
list Lists all installed mods
|
||||
uninstall <mods...> Removes one or more mods
|
||||
essential <mods...> Marks mods as essential or not
|
||||
update Updates all outdated mods
|
||||
migrate-possible [options] [version] Checks if migration is possible to a given Minecraft version
|
||||
migrate [options] [version] Migrates all mods to a target Minecraft version
|
||||
help [command] Help for a specific command
|
||||
```
|
||||
|
||||
## Why Custom Coding Matters
|
||||
|
||||
Building the My-MC.link Control Panel from scratch offers several advantages over using off-the-shelf solutions:
|
||||
|
||||
1. **Tailored Integration**: The panel is designed specifically for My-MC.link’s infrastructure, ensuring seamless interaction with Docker containers, custom APIs, and the platform’s authentication system. This eliminates compatibility issues and optimizes performance.
|
||||
|
||||
2. **Security First**: Custom coding allowed us to implement robust security measures, including HMAC-based token generation, rate-limiting, CSRF protection, and CSP with nonces. These features protect against common web vulnerabilities and ensure user data safety.
|
||||
|
||||
3. **Real-Time Capabilities**: The WebSocket-driven architecture enables real-time updates for server metrics, logs, and player status, providing a dynamic user experience that generic panels often lack.
|
||||
|
||||
4. **Feature Flexibility**: The panel supports unique features like the SFTP browser, mod management, and automated backups, tailored to the needs of Minecraft server administrators. Custom development allowed us to prioritize these features and integrate them seamlessly.
|
||||
|
||||
5. **Scalability and Maintenance**: By owning the codebase, the My-MC.link team can easily extend the panel with new features, optimize performance, and address issues without relying on third-party vendors. The open-source nature (available at `https://git.ssh.surf/hypermc/panel`) encourages community contributions and transparency.
|
||||
|
||||
6. **User Experience**: The frontend is crafted with a focus on usability, featuring a responsive design, intuitive modals, and real-time feedback. Libraries like Tailwind CSS and Chart.js enhance the visual appeal and functionality, making server management accessible to all users.
|
||||
|
||||
## Challenges and Solutions
|
||||
|
||||
### Challenge: Real-Time Log Streaming
|
||||
|
||||
Streaming Docker container logs in real-time while handling container restarts and connection drops was complex. The `streamContainerLogs` function needed to manage log streams efficiently and reconnect automatically.
|
||||
|
||||
**Solution**: We implemented a robust streaming mechanism in `includes/docker.js`, using Docker’s `logs` API with `follow: true`. A monitoring interval checks container status and restarts the stream if necessary. The frontend uses `xterm.js` to display logs cleanly, with automatic scrolling to keep the latest logs visible.
|
||||
|
||||
### Challenge: Secure Authentication
|
||||
|
||||
Ensuring secure authentication without storing sensitive data on the client side was critical. Temporary login links needed to be both secure and user-friendly.
|
||||
|
||||
**Solution**: The `generateLoginLink` and `handleAutoLogin` functions use HMAC-SHA256 for token generation, with IP and user-agent verification to prevent unauthorized access. Temporary links expire after a configurable period, and credentials are stored securely in `localStorage` only after validation.
|
||||
|
||||
### Challenge: SFTP Integration
|
||||
|
||||
Providing a browser-based SFTP client without exposing credentials or requiring external software was a significant hurdle.
|
||||
|
||||
**Solution**: The auto-connection endpoint (`/auto-connection`) generates temporary connection IDs, and the frontend integrates with an internal SFTP service per container. Credentials are transmitted securely via POST requests, and the iframe-based client ensures a seamless user experience.
|
||||
|
||||
### Challenge: Resource Management
|
||||
|
||||
Managing multiple WebSocket connections and intervals for real-time updates could lead to resource leaks if not handled properly.
|
||||
|
||||
**Solution**: The `clients` Map tracks active connections, and all intervals (e.g., for Docker stats, status checks) are cleared on connection close. The backend also implements cleanup for temporary links and log streams, ensuring efficient resource usage.
|
||||
|
||||
## Impact on the My-MC.link Ecosystem
|
||||
|
||||
The custom-coded control panel has transformed the My-MC.link ecosystem by:
|
||||
|
||||
- **Simplifying Server Management**: Administrators can monitor and control their servers from a single interface, reducing the need for multiple tools.
|
||||
- **Enhancing Accessibility**: The browser-based SFTP client and mod management system make advanced server administration accessible to users without technical expertise.
|
||||
- **Improving Reliability**: Real-time monitoring and easy to trigger backups ensure servers remain operational and data is protected.
|
||||
- **Fostering Community Engagement**: The open-source codebase invites contributions, fostering a community-driven approach to feature development.
|
||||
- **Setting a Standard**: The panel’s sleek design and robust functionality set a new standard for Minecraft server management, differentiating My-MC.link from competitors.
|
||||
|
||||
## My thoughts
|
||||
|
||||
The My-MC.link Control Panel is a testament to the power of custom development. By building a tailored solution, the team has created a robust, secure, and user-friendly platform that enhances the Minecraft server management experience. Its seamless integration with Docker, real-time WebSocket updates, and innovative features like the SFTP browser make it a standout in the Minecraft hosting ecosystem. As an open-source project, it invites collaboration and continuous improvement, ensuring it remains a cornerstone of My-MC.link’s offerings. Whether you’re a casual server owner or a seasoned administrator, the My-MC.link Control Panel is an indispensable tool for managing your Minecraft world.
|
||||
303
markdown/Creating a Peer to Peer Audio Streaming Service.md
Normal file
@ -0,0 +1,303 @@
|
||||
<!-- lead -->
|
||||
A Deep Dive into Live Streaming and Sharing Audio Data
|
||||
|
||||
|
||||
|
||||
Live audio streaming is a powerful tool for content delivery, communication, and entertainment. From podcasts to live events, the ability to stream audio across the globe in real-time is both convenient and widely utilized. In this blog post, we're going to explore an innovative way to stream audio using peer-to-peer (P2P) technology, leveraging the power of the Hyperswarm network to share audio data with connected peers in real time.
|
||||
|
||||
We’ll dissect the code, which integrates various Node.js libraries such as Hyperswarm, `youtube-audio-stream`, and `Speaker`. These components, when combined, enable a fully functioning P2P audio streaming solution. By the end of this post, you'll have a comprehensive understanding of how this code works and the fundamental building blocks for creating your own live streaming service without relying on traditional servers.
|
||||
|
||||
# Source
|
||||
|
||||
## https://git.ssh.surf/snxraven/hypertube
|
||||
|
||||
### The Concept: Peer-to-Peer Audio Streaming
|
||||
|
||||
The traditional approach to live streaming audio involves a server that transmits data to clients (listeners). This centralized model works well, but it can be costly and have single points of failure. With P2P streaming, instead of having a single server, each peer (user) in the network can act as both a client and a server, sharing the workload of streaming the audio.
|
||||
|
||||
The benefits of a P2P system include:
|
||||
- **Decentralization:** No central server means there is no single point of failure.
|
||||
- **Scalability:** As more peers join, the network can handle more load.
|
||||
- **Cost Efficiency:** By eliminating the need for dedicated servers, operational costs are reduced.
|
||||
|
||||
Let’s break down how the code enables live audio streaming through P2P, starting from the top.
|
||||
|
||||
### Setting Up Dependencies
|
||||
|
||||
The code starts by requiring several key dependencies that allow us to implement the core functionality of the streaming system. These are the libraries responsible for handling audio data, network connections, and cryptographic operations:
|
||||
|
||||
```js
|
||||
const fs = require('fs');
|
||||
const b4a = require('b4a');
|
||||
const Hyperswarm = require('hyperswarm');
|
||||
const gracefulGoodbye = require('graceful-goodbye');
|
||||
const crypto = require('hypercore-crypto');
|
||||
```
|
||||
|
||||
- **`fs`** allows file system interaction.
|
||||
- **`b4a`** is a binary and array buffer utility for encoding/decoding data.
|
||||
- **`Hyperswarm`** is a peer-to-peer networking library.
|
||||
- **`gracefulGoodbye`** ensures that the swarm is destroyed correctly when the process exits.
|
||||
- **`crypto`** provides cryptographic functions to generate random public keys.
|
||||
|
||||
### Randomizing Usernames and Setting Up Audio Components
|
||||
|
||||
To make the experience dynamic and personalized, the code generates a random username for each user:
|
||||
|
||||
```js
|
||||
let rand = Math.floor(Math.random() * 99999).toString();
|
||||
let USERNAME = "annon" + rand;
|
||||
```
|
||||
|
||||
Next, we set up audio streaming using `youtube-audio-stream` to fetch and decode the audio from a YouTube URL, and the `Speaker` library to play it locally.
|
||||
|
||||
```js
|
||||
const stream = require('youtube-audio-stream');
|
||||
const decoder = require('@suldashi/lame').Decoder;
|
||||
const Speaker = require('speaker');
|
||||
|
||||
let audioPlayer = new Speaker({
|
||||
channels: 2,
|
||||
bitDepth: 16,
|
||||
sampleRate: 44100,
|
||||
});
|
||||
```
|
||||
|
||||
- **`youtube-audio-stream`**: Streams audio directly from YouTube videos.
|
||||
- **`lame.Decoder`**: Decodes MP3 streams into PCM audio data.
|
||||
- **`Speaker`**: Sends PCM audio data to the speakers.
|
||||
|
||||
### Streaming Audio to Peers
|
||||
|
||||
The central function in this system is `startStream(URL)`, which handles streaming the audio data from a specified YouTube URL and broadcasting it to all connected peers in the Hyperswarm network:
|
||||
|
||||
```js
|
||||
function startStream(URL) {
|
||||
const audioStream = stream(URL).pipe(decoder());
|
||||
|
||||
audioStream.on('data', data => {
|
||||
for (const conn of conns) {
|
||||
conn.write(data);
|
||||
}
|
||||
});
|
||||
|
||||
if (!audioPlayer.writable) {
|
||||
audioPlayer = new Speaker({
|
||||
channels: 2,
|
||||
bitDepth: 16,
|
||||
sampleRate: 44100,
|
||||
});
|
||||
audioStream.pipe(audioPlayer);
|
||||
isPlaying = true;
|
||||
} else {
|
||||
audioStream.pipe(audioPlayer);
|
||||
isPlaying = true;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
- The **YouTube audio** is streamed, decoded, and then piped to both the connected peers and the local speaker.
|
||||
- The **`audioStream.on('data')`** listener pushes the audio data to every connected peer via the `conn.write(data)` function.
|
||||
|
||||
### Handling the Hyperswarm Network
|
||||
|
||||
The P2P backbone of the system is powered by Hyperswarm. Each peer connects to a "swarm" (a decentralized group of peers), where they can exchange audio data:
|
||||
|
||||
```js
|
||||
const swarm = new Hyperswarm();
|
||||
gracefulGoodbye(() => swarm.destroy());
|
||||
```
|
||||
|
||||
Peers are identified using public keys, and connections are managed through the following code block:
|
||||
|
||||
```js
|
||||
swarm.on('connection', conn => {
|
||||
const name = b4a.toString(conn.remotePublicKey, 'hex');
|
||||
console.log(`* got a connection from ${name} (${USERNAME}) *`);
|
||||
|
||||
if (isPlaying) {
|
||||
startStream();
|
||||
}
|
||||
|
||||
conns.push(conn);
|
||||
conn.once('close', () => conns.splice(conns.indexOf(conn), 1));
|
||||
conn.on('data', data => {
|
||||
if (data.length === 0) {
|
||||
for (const conn of conns) {
|
||||
conn.write(`Stopping on all Peers`);
|
||||
}
|
||||
audioPlayer.end();
|
||||
isPlaying = false;
|
||||
} else {
|
||||
try {
|
||||
if (!audioPlayer.writable) {
|
||||
audioPlayer = new Speaker({
|
||||
channels: 2,
|
||||
bitDepth: 16,
|
||||
sampleRate: 44100,
|
||||
});
|
||||
audioStream.pipe(audioPlayer);
|
||||
isPlaying = true;
|
||||
} else {
|
||||
audioPlayer.write(data);
|
||||
}
|
||||
} catch (err) {
|
||||
if (err.code === "ERR_STREAM_WRITE_AFTER_END") {
|
||||
console.log("The stream has already ended, cannot write data.");
|
||||
} else {
|
||||
throw err;
|
||||
}
|
||||
}
|
||||
}
|
||||
});
|
||||
});
|
||||
```
|
||||
|
||||
Each connection is a two-way channel, where peers can receive and transmit audio data. If the stream is already playing, it starts streaming to new connections immediately. The code also ensures that when a peer disconnects, the connection is removed from the list.
|
||||
|
||||
### Streaming Control: Play and Stop
|
||||
|
||||
Control over the stream is achieved using commands entered by the user in the terminal. The code listens for two primary commands: `!play` and `!stop`.
|
||||
|
||||
- **`!play`**: Starts the stream from the given URL and broadcasts it to all peers.
|
||||
- **`!stop`**: Stops the current stream and notifies all peers to stop as well.
|
||||
|
||||
```js
|
||||
rl.on('line', input => {
|
||||
if (input.startsWith('!play')) {
|
||||
let dataInfo = input.split(" ");
|
||||
let URL = dataInfo[1];
|
||||
startStream(URL);
|
||||
}
|
||||
|
||||
if (input === '!stop') {
|
||||
if (isPlaying) {
|
||||
audioPlayer.end();
|
||||
stopStream();
|
||||
audioPlayer = new Speaker({
|
||||
channels: 2,
|
||||
bitDepth: 16,
|
||||
sampleRate: 44100,
|
||||
});
|
||||
} else {
|
||||
console.log("The stream is already stopped.");
|
||||
}
|
||||
}
|
||||
});
|
||||
```
|
||||
|
||||
### Joining a Topic and Connecting Peers
|
||||
|
||||
Peers join the same "topic" to connect and share data. A unique topic is generated for each session, and peers can join by sharing the topic key:
|
||||
|
||||
```js
|
||||
const topic = process.argv[2] ? b4a.from(process.argv[2], 'hex') : crypto.randomBytes(32);
|
||||
const discovery = swarm.join(topic, { client: true, server: true });
|
||||
|
||||
discovery.flushed().then(() => {
|
||||
console.log(`joined topic: ${b4a.toString(topic, 'hex')}`);
|
||||
console.log("(Share this key to others so they may join)");
|
||||
console.log("To Play a youtube link, use !play LINKHERE to stop !stop");
|
||||
console.log("All commands are global to all peers");
|
||||
});
|
||||
```
|
||||
|
||||
### Wrapping Up
|
||||
|
||||
This P2P audio streaming code provides a powerful way to decentralize live audio broadcasting. By leveraging Hyperswarm for peer-to-peer connections, the system eliminates the need for a central server, making it resilient, scalable, and cost-effective. Users can easily stream YouTube audio to any number of peers in the network, and each peer can share the audio data with others.
|
||||
|
||||
### This is Just the Beginning: Expanding Audio Sources and Use Cases
|
||||
|
||||
The beauty of this system lies in its flexibility—while the current implementation streams audio from YouTube, this concept can easily be extended to stream audio from a variety of sources. Each source could serve different purposes, opening up a wealth of use cases across industries. Below, we explore some of the diverse audio sources that could be integrated into the system, along with potential functions and real-world applications.
|
||||
|
||||
|
||||
|
||||
#### 1. **Streaming from YouTube and Other Online Media Platforms**
|
||||
|
||||
As the code currently does, streaming audio from YouTube is a simple yet effective way to broadcast any audio content that is hosted online. This could be extended to other platforms, such as Vimeo, SoundCloud, or even custom URLs from media servers.
|
||||
|
||||
**Use Cases**:
|
||||
- **Live Podcasts**: Hosts could broadcast episodes directly from platforms like YouTube or SoundCloud.
|
||||
- **Music Streaming**: Users could share their favorite tracks or playlists, turning the P2P network into a decentralized music sharing platform.
|
||||
- **Educational Content**: Stream audio from educational videos or lectures available on platforms like YouTube, providing a collaborative learning environment for students or study groups.
|
||||
|
||||
|
||||
|
||||
#### 2. **Microphone Input (Live Audio)**
|
||||
|
||||
Another powerful feature would be to integrate real-time audio streaming from a user’s microphone. This would allow for live, dynamic content creation, such as broadcasts, live commentary, or even interactive conversations.
|
||||
|
||||
**Use Cases**:
|
||||
- **Live DJ Sets**: Musicians or DJs could use the platform to broadcast live sets or performances, where listeners across the globe tune in without needing a central server.
|
||||
- **Live Q&A Sessions or Webinars**: Professionals could host live Q&A sessions or webinars where attendees can join the audio stream to listen, ask questions, or participate.
|
||||
- **Community Radio**: Users could create their own community-based radio stations, transmitting live shows to peers.
|
||||
|
||||
|
||||
|
||||
#### 3. **Local Audio Files**
|
||||
|
||||
Instead of streaming from an online platform, the system could be expanded to stream locally stored audio files (e.g., MP3, WAV). This would allow users to share personal audio collections, playlists, or even previously recorded broadcasts with peers.
|
||||
|
||||
**Use Cases**:
|
||||
- **Personal Music Sharing**: Users could stream their own music collection to their peers, turning the platform into a decentralized version of services like Spotify.
|
||||
- **Audiobook Sharing**: Users could broadcast audiobooks stored on their local devices, ideal for creating a P2P audiobook club or study group.
|
||||
- **Custom Soundtracks**: Independent artists could share their work directly with listeners, bypassing traditional streaming platforms and maintaining control over distribution.
|
||||
|
||||
|
||||
|
||||
#### 4. **Radio Station Integration**
|
||||
|
||||
Incorporating traditional radio station streams could transform the P2P system into a global platform for sharing and redistributing radio content. Many radio stations already stream their broadcasts online, which can be piped into the P2P network for redistribution among peers.
|
||||
|
||||
**Use Cases**:
|
||||
- **Global Access to Local Radio**: Users can stream local radio stations from their country and allow peers worldwide to listen in, bringing localized content to a global audience.
|
||||
- **Talk Shows and News Broadcasts**: Political talk shows, news broadcasts, or even live sports commentary can be streamed and shared globally, giving access to a wider range of content.
|
||||
|
||||
|
||||
|
||||
#### 5. **Audio from Streaming APIs**
|
||||
|
||||
Streaming APIs such as Spotify’s Web API, Apple Music’s API, or even real-time data from live event platforms could be utilized to fetch and stream audio dynamically based on user input or pre-configured playlists.
|
||||
|
||||
**Use Cases**:
|
||||
- **Dynamic Playlists**: The system could automatically stream music based on user-defined parameters, pulling tracks from services like Spotify and distributing them to peers.
|
||||
- **Live Sports or Event Commentary**: Audio streams from live events could be captured through an API and shared in real-time, allowing users to tune in and listen to live commentary or event coverage.
|
||||
|
||||
|
||||
|
||||
#### 6. **Live Audio Feeds (Surveillance, Public Announcements)**
|
||||
|
||||
Another potential application is integrating live audio feeds from different environments or systems. This could include live surveillance audio for security purposes or public announcement systems for large events.
|
||||
|
||||
**Use Cases**:
|
||||
- **Security Surveillance**: In a security-focused environment, audio feeds from various locations could be streamed to connected peers, allowing real-time monitoring.
|
||||
- **Event PA Systems**: Public announcement systems at large events (conferences, music festivals, etc.) could stream live audio to all attendees via P2P technology, ensuring seamless information distribution.
|
||||
|
||||
|
||||
|
||||
#### 7. **VoIP (Voice over IP)**
|
||||
|
||||
By integrating VoIP protocols, the system could facilitate real-time peer-to-peer voice communication, similar to services like Skype or Discord, but with the added benefit of decentralized infrastructure.
|
||||
|
||||
**Use Cases**:
|
||||
- **Group Voice Chat**: Peers could communicate in real-time using voice chat without relying on centralized servers, ideal for gaming, virtual meetups, or team collaboration.
|
||||
- **Decentralized Call Center**: Businesses could set up a decentralized call center where customer service representatives communicate with customers via P2P VoIP, reducing server costs and improving privacy.
|
||||
|
||||
|
||||
|
||||
### Advantages of Decentralizing Audio Streaming
|
||||
|
||||
The decentralized nature of this P2P audio streaming system offers several key advantages:
|
||||
|
||||
- **Cost Efficiency**: No need for expensive server infrastructure. Each peer contributes to the network, sharing bandwidth and resources.
|
||||
- **Scalability**: The system grows organically as more peers join. Each new peer helps distribute the load of streaming audio, allowing for near-limitless scalability.
|
||||
- **Resilience**: Without a central server, there is no single point of failure. The system remains operational even if some peers disconnect or fail.
|
||||
- **Privacy**: Since the audio data is shared directly between peers, it bypasses traditional content distribution networks, giving users more control over their data and improving privacy.
|
||||
|
||||
|
||||
|
||||
### Final Thoughts A Flexible and Expandable System
|
||||
|
||||
This P2P audio streaming system, though initially designed for streaming YouTube audio, is a highly flexible framework that can be adapted to stream from various sources. Whether it's live broadcasts from a microphone, local audio files, radio streams, or VoIP, the concept can evolve to meet different needs. The potential use cases range from entertainment (music sharing and live DJ sets) to education (webinars, podcasts) and even security (surveillance audio feeds).
|
||||
|
||||
By expanding the types of audio sources supported and integrating new functionalities, this P2P framework can become a robust, decentralized platform for streaming and sharing audio data in ways that traditional, centralized systems cannot match. Whether you're a developer, artist, or enthusiast, the opportunities are endless, making this system a powerful tool for real-time, decentralized communication.
|
||||
248
markdown/Creating a User Installable AI Bot for Discord.md
Normal file
@ -0,0 +1,248 @@
|
||||
## Deep Dive into RayAI Chat Bot User-Installable Version
|
||||
<!-- lead -->
|
||||
Enabling users to use RayAI within any Channel on Discord.
|
||||
|
||||
This deep dive will explain how I built a user-installable version of the RayAI Chat Bot, highlighting key aspects such as the bot’s architecture, command handling, user privacy settings, and interaction with APIs. The bot integrates with Discord using its Slash Commands interface and makes use of Axios to send requests to a backend service. Below is a detailed walkthrough of the components that make this bot user-installable and functional.
|
||||
|
||||
# Source:
|
||||
|
||||
## https://git.ssh.surf/snxraven/rayai/src/branch/main/bot/installableApp-groq.js
|
||||
|
||||
|
||||
### Project Structure and Dependencies
|
||||
|
||||
Before diving into specific sections of the code, here's an overview of the main components and dependencies used:
|
||||
|
||||
```javascript
|
||||
const { Client, GatewayIntentBits, REST, Routes, EmbedBuilder, SlashCommandBuilder } = require('discord.js');
|
||||
const axios = require('axios');
|
||||
const he = require('he');
|
||||
const fs = require('fs');
|
||||
require('dotenv').config();
|
||||
const { userResetMessages } = require('./assets/messages.js');
|
||||
```
|
||||
|
||||
- **Discord.js**: Provides the essential framework to interact with Discord. Key classes such as `Client`, `GatewayIntentBits`, `REST`, `Routes`, and `EmbedBuilder` manage communication between the bot and Discord's API.
|
||||
- **Axios**: Used to send HTTP requests to external services, particularly the RayAI backend, handling operations like sending user messages and resetting conversations.
|
||||
- **`he`**: A library for encoding HTML entities, ensuring that user inputs are safely transmitted over HTTP.
|
||||
- **File System (fs)**: Utilized to store and retrieve user privacy settings, allowing the bot to persist data between sessions.
|
||||
- **dotenv**: Manages sensitive information like tokens and API paths by loading environment variables from a `.env` file.
|
||||
|
||||
### Discord Client Initialization
|
||||
|
||||
The bot is instantiated using the `Client` class, specifically configured to only handle events related to guilds (`GatewayIntentBits.Guilds`). This limits the bot's scope to only manage messages and interactions within servers:
|
||||
|
||||
```javascript
|
||||
const client = new Client({
|
||||
intents: [GatewayIntentBits.Guilds]
|
||||
});
|
||||
```
|
||||
|
||||
### Managing User Privacy Settings
|
||||
|
||||
The bot includes a privacy feature where users can toggle between ephemeral (private) and standard (public) responses. This is achieved through the `userPrivacySettings.json` file, which stores these preferences:
|
||||
|
||||
```javascript
|
||||
// Load or initialize the user privacy settings
|
||||
const userPrivacyFilePath = './userPrivacySettings.json';
|
||||
let userPrivacySettings = {};
|
||||
if (fs.existsSync(userPrivacyFilePath)) {
|
||||
userPrivacySettings = JSON.parse(fs.readFileSync(userPrivacyFilePath));
|
||||
}
|
||||
|
||||
// Save the user privacy settings
|
||||
function saveUserPrivacySettings() {
|
||||
fs.writeFileSync(userPrivacyFilePath, JSON.stringify(userPrivacySettings, null, 2));
|
||||
}
|
||||
```
|
||||
|
||||
The privacy settings are initialized by checking if the `userPrivacySettings.json` file exists. If it does, the bot loads the settings into memory; otherwise, a new file is created. The `saveUserPrivacySettings()` function is used to persist updates when a user toggles their privacy settings.
|
||||
|
||||
### Slash Command Registration with Extras
|
||||
|
||||
The bot supports four commands:
|
||||
|
||||
- `/reset`: Resets the current conversation with the AI.
|
||||
- `/restartcore`: Restarts the core service.
|
||||
- `/chat`: Sends a user message to the AI.
|
||||
- `/privacy`: Toggles between ephemeral (private) and standard (public) responses.
|
||||
|
||||
The commands are defined using `SlashCommandBuilder` and registered with Discord using the REST API:
|
||||
|
||||
```javascript
|
||||
const commands = [
|
||||
new SlashCommandBuilder().setName('reset').setDescription('Reset the conversation'),
|
||||
new SlashCommandBuilder().setName('restartcore').setDescription('Restart the core service'),
|
||||
new SlashCommandBuilder().setName('chat').setDescription('Send a chat message')
|
||||
.addStringOption(option =>
|
||||
option.setName('message')
|
||||
.setDescription('Message to send')
|
||||
.setRequired(true)),
|
||||
new SlashCommandBuilder().setName('privacy').setDescription('Toggle between ephemeral and standard responses')
|
||||
].map(command => {
|
||||
const commandJSON = command.toJSON();
|
||||
|
||||
const extras = {
|
||||
"integration_types": [0, 1], // 0 for guild, 1 for user
|
||||
"contexts": [0, 1, 2] // 0 for guild, 1 for app DMs, 2 for GDMs and other DMs
|
||||
};
|
||||
|
||||
Object.keys(extras).forEach(key => commandJSON[key] = extras[key]);
|
||||
|
||||
return commandJSON;
|
||||
});
|
||||
|
||||
// Register commands with Discord
|
||||
const rest = new REST({ version: '10' }).setToken(process.env.THE_TOKEN_2);
|
||||
|
||||
client.once('ready', async () => {
|
||||
try {
|
||||
console.log(`Logged in as ${client.user.tag}!`);
|
||||
await rest.put(Routes.applicationCommands(process.env.DISCORD_CLIENT_ID), { body: commands });
|
||||
console.log('Successfully registered application commands with extras.');
|
||||
} catch (error) {
|
||||
console.error('Error registering commands: ', error);
|
||||
}
|
||||
});
|
||||
```
|
||||
|
||||
The bot registers the commands upon startup using the `REST.put()` method. Note that each command includes extra metadata for `integration_types` (whether the command is for guild or user contexts) and `contexts` (indicating where the command applies: guilds, direct messages, etc.).
|
||||
|
||||
### Handling User Interactions
|
||||
|
||||
Each command has its respective handler, triggered when a user interacts with the bot:
|
||||
|
||||
```javascript
|
||||
client.on('interactionCreate', async interaction => {
|
||||
if (!interaction.isCommand()) return;
|
||||
|
||||
const { commandName, options } = interaction;
|
||||
|
||||
if (commandName === 'reset') {
|
||||
return await resetConversation(interaction);
|
||||
} else if (commandName === 'restartcore') {
|
||||
await restartCore(interaction);
|
||||
} else if (commandName === 'chat') {
|
||||
const content = options.getString('message');
|
||||
await handleUserMessage(interaction, content);
|
||||
} else if (commandName === 'privacy') {
|
||||
await togglePrivacy(interaction);
|
||||
}
|
||||
});
|
||||
```
|
||||
|
||||
Each interaction is checked for its command name, and the corresponding function is invoked:
|
||||
|
||||
- **`resetConversation()`**: Sends a POST request to the RayAI backend to reset the current conversation.
|
||||
- **`restartCore()`**: Sends a POST request to restart the core service.
|
||||
- **`handleUserMessage()`**: Sends the user's message to the backend for processing, encodes it using `he.encode()` for safety, and handles the bot's typing indicators and replies.
|
||||
- **`togglePrivacy()`**: Toggles the user's privacy setting between ephemeral and standard responses, storing this preference for future use.
|
||||
|
||||
### Privacy Toggle
|
||||
|
||||
The `/privacy` command allows users to control whether their responses are private or visible to everyone:
|
||||
|
||||
```javascript
|
||||
async function togglePrivacy(interaction) {
|
||||
const userId = interaction.user.id;
|
||||
const currentSetting = userPrivacySettings[userId] || false;
|
||||
userPrivacySettings[userId] = !currentSetting; // Toggle the setting
|
||||
saveUserPrivacySettings();
|
||||
|
||||
const message = userPrivacySettings[userId]
|
||||
? 'Your responses are now set to ephemeral (visible only to you).'
|
||||
: 'Your responses are now standard (visible to everyone).';
|
||||
await interaction.reply({ content: message, ephemeral: true });
|
||||
}
|
||||
```
|
||||
|
||||
This function checks the current privacy setting for the user, toggles it, and saves the updated setting. A response is then sent to the user, confirming the new privacy mode.
|
||||
|
||||
### Sending Long Messages
|
||||
|
||||
The bot can handle large responses from the AI by splitting them into chunks and sending them in sequence:
|
||||
|
||||
```javascript
|
||||
async function sendLongMessage(interaction, responseText) {
|
||||
const limit = 8096;
|
||||
|
||||
if (responseText.length > limit) {
|
||||
const lines = responseText.split('\n');
|
||||
const chunks = [];
|
||||
let currentChunk = '';
|
||||
|
||||
for (const line of lines) {
|
||||
if (currentChunk.length + line.length > limit) {
|
||||
chunks.push(currentChunk);
|
||||
currentChunk = '';
|
||||
}
|
||||
currentChunk += line + '\n';
|
||||
}
|
||||
|
||||
if (currentChunk.trim() !== '') {
|
||||
chunks.push(currentChunk.trim());
|
||||
}
|
||||
|
||||
if (chunks.length >= 80) return await interaction.reply({ content: "Response chunks too large. Try again", ephemeral: isEphemeral(interaction.user.id) });
|
||||
|
||||
for (let i = 0; i < chunks.length; i++) {
|
||||
const chunk = chunks[i];
|
||||
const embed = new EmbedBuilder()
|
||||
.setDescription(chunk)
|
||||
.setColor("#3498DB")
|
||||
.setTimestamp();
|
||||
|
||||
setTimeout(() => {
|
||||
interaction.followUp({
|
||||
embeds: [embed],
|
||||
ephemeral: isEphemeral(interaction.user.id)
|
||||
});
|
||||
}, i * (process.env.OVERFLOW_DELAY || 3) * 1000);
|
||||
}
|
||||
} else {
|
||||
const embed = new EmbedBuilder()
|
||||
.setDescription(responseText)
|
||||
.setColor("#3498DB")
|
||||
.setTimestamp();
|
||||
|
||||
interaction.editReply({
|
||||
embeds: [embed],
|
||||
ephemeral: isEphemeral(interaction.user.id)
|
||||
});
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
This function ensures that responses longer than Discord's character limit are split and delivered to the user in manageable chunks. Each chunk is sent with a delay to avoid overwhelming the bot or Discord API.
|
||||
|
||||
### The results
|
||||
|
||||
The RayAI Chat Bot is a robust, user-centric Discord bot designed to provide seamless interaction with an AI backend, featuring rich customization options for user preferences and flexible handling of both short and long messages. This project exemplifies how powerful a user-installable bot can be when built with attention to detail and user experience.
|
||||
|
||||
#### Key Aspects of the Project:
|
||||
|
||||
1. **Slash Command Integration**:
|
||||
The bot leverages Discord's Slash Command API to create an intuitive, user-friendly interface where commands are easy to use and comprehend. The choice of commands—such as `/reset`, `/restartcore`, and `/chat`—ensures that the user has full control over interactions with the AI service. By dynamically registering these commands using Discord’s REST API, the bot can be installed and updated without manual intervention, adding to its user-friendly nature.
|
||||
|
||||
2. **User Privacy Customization**:
|
||||
The integration of a privacy toggle function demonstrates the bot’s emphasis on user autonomy and personalization. Users can easily switch between public and private message responses via the `/privacy` command, with the bot persisting these settings across sessions using a JSON file. This feature enhances trust and usability, making the bot suitable for varied contexts where privacy may be a concern.
|
||||
|
||||
3. **Interaction with External APIs**:
|
||||
The bot’s communication with the AI backend is elegantly handled through Axios, enabling the bot to send user inputs securely and receive intelligent responses. The careful encoding of user messages via `he.encode()` mitigates security risks, such as cross-site scripting (XSS) or injection attacks, ensuring that the bot operates safely even when interacting with untrusted input.
|
||||
|
||||
4. **Handling Long Messages**:
|
||||
The long-message handling functionality solves a common challenge when integrating chatbots into platforms like Discord, which has strict message limits. By intelligently splitting long AI responses into manageable chunks and sending them sequentially, the bot maintains the fluidity of conversation while respecting Discord’s limitations. This ensures that users receive complete responses without abrupt truncation, even when dealing with complex or detailed queries.
|
||||
|
||||
5. **Automatic Command Registration with Extras**:
|
||||
The ability to dynamically register commands at startup using the Discord REST API eliminates the need for pre-configuration, making the bot easy to install and update. Additionally, by adding custom `integration_types` and `contexts` to the command registration, the bot can function across various Discord environments (guilds, DMs, etc.), extending its versatility and appeal to a broader user base.
|
||||
|
||||
6. **Resilient Error Handling**:
|
||||
The bot is built with robust error handling, particularly in scenarios where the AI backend may be busy or encounter rate limits. The user is promptly notified if the service is unavailable, and fallback mechanisms ensure that the user experience remains smooth, even in the face of external service issues. This kind of resilience is crucial for any production-grade bot, minimizing downtime and ensuring reliability.
|
||||
|
||||
7. **User-Installable Design**:
|
||||
A key highlight of this project is the bot's user-installable nature. By storing configuration details like tokens and API paths in environment variables and using simple file-based storage for privacy settings, the bot is easy to configure and deploy in any environment. The ability for users to install and manage the bot themselves adds to its flexibility, making it accessible to a wide range of users, from individuals to server administrators looking for a custom chatbot solution.
|
||||
|
||||
|
||||
The RayAI Chat Bot showcases the power of combining modern web technologies like Discord.js, Axios, and file-based storage to create a sophisticated, user-installable chatbot. Its thoughtful features—ranging from user privacy customization to efficient message handling—make it a highly functional tool that serves both casual and professional needs.
|
||||
|
||||
This bot is not just a technical achievement but also a product of careful consideration of user needs, focusing on ease of installation, flexibility, and resilience. Whether you're managing a Discord server, interacting with AI, or looking for a chatbot solution that’s easy to deploy and scale, the RayAI Chat Bot sets a high standard for future projects in this domain.
|
||||
256
markdown/Creating a User Installable Version of My-MC.Link.md
Normal file
@ -0,0 +1,256 @@
|
||||
<!-- lead -->
|
||||
Enabling users to use My-MC.Link within any Channel on Discord.
|
||||
|
||||
The My-MC.Link Discord bot offers a comprehensive and user-friendly interface for Minecraft server management, enabling users to control server operations from any Discord server. This deep dive explores the technical aspects of the bot, including its architecture, command handling, token management, API integration, and the strategies employed to deliver seamless user interactions. By combining Discord’s API with the powerful features of the My-MC.Link service, this bot provides an extensive range of server functionalities in a highly accessible and easily deployable format.
|
||||
|
||||
### Project Structure and Key Dependencies
|
||||
|
||||
The bot leverages several essential libraries and APIs to deliver its functionality:
|
||||
|
||||
```javascript
|
||||
import { Client, GatewayIntentBits, SlashCommandBuilder, REST, Routes, EmbedBuilder } from 'discord.js';
|
||||
import jsonfile from 'jsonfile';
|
||||
import MyMCLib from 'mymc-lib';
|
||||
import unirest from 'unirest';
|
||||
import { readFileSync } from 'fs';
|
||||
import cmd from 'cmd-promise';
|
||||
```
|
||||
|
||||
# Source
|
||||
|
||||
## https://git.ssh.surf/hypermc/hypermc-api-user-install-bot
|
||||
|
||||
#### Breakdown of Key Dependencies:
|
||||
|
||||
- **Discord.js**: This is the backbone of the bot, providing classes like `Client`, `SlashCommandBuilder`, `REST`, and `EmbedBuilder`. These components enable interaction with Discord's API, handling everything from registering commands to managing user interactions and generating rich embeds for responses.
|
||||
|
||||
- **jsonfile**: This package manages reading and writing user-specific tokens in JSON format. Storing tokens in a file allows the bot to persist authentication information between sessions, making it unnecessary for users to re-authenticate repeatedly.
|
||||
|
||||
- **MyMCLib**: A custom library that acts as a wrapper around the My-MC.Link API, simplifying the process of interacting with the service’s various endpoints, such as starting or stopping servers, fetching logs, and managing mods.
|
||||
|
||||
- **unirest**: Used to make HTTP requests to the My-MC.Link API, specifically to handle token generation and validation.
|
||||
|
||||
- **cmd-promise**: A library that facilitates the execution of shell commands in a promise-based format, used for running server checks and other operational commands, ensuring that server status can be verified before certain actions are performed.
|
||||
|
||||
### Discord Client Initialization
|
||||
|
||||
The bot initializes the Discord client with a focus on `Guilds`, which makes it a server-centric bot that exclusively handles commands and interactions within Discord servers (as opposed to direct messages):
|
||||
|
||||
```javascript
|
||||
const client = new Client({ intents: [GatewayIntentBits.Guilds] });
|
||||
```
|
||||
|
||||
By limiting the bot’s scope to `Guilds`, it ensures that the bot can manage interactions specific to Minecraft server administration in a controlled environment, reducing unnecessary overhead from other Discord intents.
|
||||
|
||||
### Token Management and API Authentication
|
||||
|
||||
#### Loading and Saving Tokens
|
||||
|
||||
One of the most critical aspects of the bot’s design is token management, which authenticates user interactions with the My-MC.Link API. The bot stores tokens in a JSON file (`tokens.json`) and retrieves or refreshes these tokens as necessary.
|
||||
|
||||
**Token Loading**:
|
||||
```javascript
|
||||
function loadTokens() {
|
||||
try {
|
||||
return jsonfile.readFileSync(tokensFile);
|
||||
} catch (error) {
|
||||
console.error('Error reading tokens file:', error);
|
||||
return {};
|
||||
}
|
||||
}
|
||||
```
|
||||
The `loadTokens()` function reads the `tokens.json` file and returns an object containing user tokens. If the file cannot be read (e.g., it doesn’t exist or has been corrupted), an empty object is returned, and the bot can request a new token.
|
||||
|
||||
**Token Saving**:
|
||||
```javascript
|
||||
function saveTokens(tokens) {
|
||||
jsonfile.writeFileSync(tokensFile, tokens, { spaces: 2 });
|
||||
}
|
||||
```
|
||||
The `saveTokens()` function writes the token data back to the `tokens.json` file, ensuring that any new or refreshed tokens are persisted for future use.
|
||||
|
||||
#### Automatic Token Retrieval
|
||||
|
||||
If a user doesn’t have a valid token or their token has expired, the bot automatically requests a new one from the My-MC.Link service using the `fetchAndSaveToken()` function:
|
||||
|
||||
```javascript
|
||||
async function fetchAndSaveToken(userId, interaction) {
|
||||
return unirest
|
||||
.post(config.endpoint.toString())
|
||||
.headers({ 'Accept': 'application/json', 'Content-Type': 'application/json' })
|
||||
.send({ "username": `mc_${userId}`, "password": config.password.toString()})
|
||||
.then((tokenInfo) => {
|
||||
const tokens = loadTokens();
|
||||
tokens[userId] = tokenInfo.body.token; // Save the new token
|
||||
saveTokens(tokens);
|
||||
return tokenInfo.body.token;
|
||||
})
|
||||
.catch((error) => {
|
||||
console.error('Error fetching token:', error);
|
||||
sendSexyEmbed("Error", "An error occurred while fetching your API token.", interaction);
|
||||
throw error;
|
||||
});
|
||||
}
|
||||
```
|
||||
|
||||
This function performs several key steps:
|
||||
1. It makes a POST request to the My-MC.Link API, sending the user’s credentials to request a new token.
|
||||
2. On success, it loads the existing tokens, updates the token for the user, and saves the updated tokens to the `tokens.json` file.
|
||||
3. If there’s an error (e.g., the API is down or the request fails), it logs the error and provides feedback to the user via a rich embed.
|
||||
|
||||
#### Token Re-Validation and Re-Fetching
|
||||
|
||||
Once a token is stored, the bot checks its validity and, if necessary, automatically fetches a new token when making API calls:
|
||||
|
||||
```javascript
|
||||
async function getToken(userId, interaction) {
|
||||
const tokens = loadTokens();
|
||||
if (!tokens[userId]) {
|
||||
return await fetchAndSaveToken(userId, interaction);
|
||||
}
|
||||
return tokens[userId];
|
||||
}
|
||||
|
||||
async function handleApiCall(apiCall, userId, interaction) {
|
||||
try {
|
||||
return await apiCall();
|
||||
} catch (error) {
|
||||
console.error('Token error, re-fetching token...');
|
||||
await fetchAndSaveToken(userId, interaction);
|
||||
return await apiCall();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Here’s what happens:
|
||||
1. **getToken**: This function checks if a token exists for the user in `tokens.json`. If no token is found, it calls `fetchAndSaveToken()` to retrieve and save a new one.
|
||||
2. **handleApiCall**: Wraps any API call to handle invalid tokens by retrying the request after fetching a new token. If a token has expired or there is any issue with authentication, the bot fetches a fresh token and retries the request.
|
||||
|
||||
### Command Registration with Discord
|
||||
|
||||
The bot uses Discord’s `SlashCommandBuilder` to define a series of commands that allow users to interact with their Minecraft servers. These commands are registered with Discord using the REST API:
|
||||
|
||||
```javascript
|
||||
const commands = [
|
||||
new SlashCommandBuilder().setName('server-stats').setDescription('Get the server statistics'),
|
||||
new SlashCommandBuilder().setName('server-log').setDescription('Get the server log'),
|
||||
new SlashCommandBuilder().setName('start-server').setDescription('Start the Minecraft server'),
|
||||
new SlashCommandBuilder().setName('stop-server').setDescription('Stop the Minecraft server'),
|
||||
new SlashCommandBuilder().setName('restart-server').setDescription('Restart the Minecraft server'),
|
||||
// Additional commands...
|
||||
];
|
||||
|
||||
// Register commands with Discord
|
||||
const rest = new REST({ version: '10' }).setToken(config.token);
|
||||
(async () => {
|
||||
try {
|
||||
console.log('Started refreshing application (/) commands.');
|
||||
await rest.put(Routes.applicationCommands(config.clientId), { body: JSONCommands });
|
||||
console.log('Successfully reloaded application (/) commands.');
|
||||
} catch (error) {
|
||||
console.error(error);
|
||||
}
|
||||
})();
|
||||
```
|
||||
|
||||
Each command is defined with a name and description using `SlashCommandBuilder`, which simplifies the process of adding new commands. These commands are then registered with Discord's API, ensuring they are available for use within the server.
|
||||
|
||||
### Handling User Interactions
|
||||
|
||||
When users invoke commands, the bot listens for interaction events and routes the request to the appropriate function based on the command name:
|
||||
|
||||
```javascript
|
||||
client.on('interactionCreate', async interaction => {
|
||||
if (!interaction.isCommand()) return;
|
||||
|
||||
const userId = interaction.user.id;
|
||||
const apiToken = await getToken(userId, interaction);
|
||||
const MyMC = new MyMCLib(apiToken);
|
||||
|
||||
switch (interaction.commandName) {
|
||||
case 'server-stats':
|
||||
const stats = await handleApiCall(() => MyMC.getStats(), userId, interaction);
|
||||
handleResponse(stats, interaction);
|
||||
break;
|
||||
|
||||
case 'start-server':
|
||||
const startResult = await handleApiCall(() => MyMC.startServer(), userId, interaction);
|
||||
handleResponse(startResult, interaction);
|
||||
break;
|
||||
|
||||
case 'stop-server':
|
||||
const stopResult = await handleApiCall(() => MyMC.stopServer(), userId, interaction);
|
||||
handleResponse(stopResult, interaction);
|
||||
break;
|
||||
|
||||
// Other commands...
|
||||
}
|
||||
});
|
||||
```
|
||||
|
||||
Each command is mapped to an API call using the `MyMCLib` library. The bot interacts with the Minecraft server via authenticated requests, and responses are processed and displayed back to the user.
|
||||
|
||||
### Sending Responses and Embeds
|
||||
|
||||
One of the standout features of this bot is its use of rich embeds for displaying information to users. These embeds provide a visually appealing way to present data such as server statistics, logs, or mod information.
|
||||
|
||||
#### Simple Embeds
|
||||
|
||||
For single-field responses, the bot sends a simple embed with a title and description:
|
||||
|
||||
```javascript
|
||||
function sendSexyEmbed(title, description, interaction, ephemeral = false) {
|
||||
const embed = new EmbedBuilder()
|
||||
.setColor("#3498DB")
|
||||
.setTitle(title)
|
||||
.setDescription(description)
|
||||
.setTimestamp()
|
||||
.setFooter({
|
||||
text: `Requested by ${interaction.user.username}`,
|
||||
iconURL: `${interaction.user.displayAvatarURL()}`
|
||||
});
|
||||
interaction
|
||||
|
||||
.reply({
|
||||
embeds: [embed],
|
||||
ephemeral: ephemeral
|
||||
});
|
||||
}
|
||||
```
|
||||
|
||||
This function ensures that every response is styled with consistent colors, timestamps, and user information.
|
||||
|
||||
#### Complex Embeds with Multiple Fields
|
||||
|
||||
For more complex responses (such as server stats or mod lists), the bot generates an embed with multiple fields:
|
||||
|
||||
```javascript
|
||||
function sendSexyEmbedWithFields(title, description, fields, interaction, ephemeral = false) {
|
||||
const embed = new EmbedBuilder()
|
||||
.setColor("#3498DB")
|
||||
.setTitle(title)
|
||||
.setDescription(description !== "N/A" ? description : undefined)
|
||||
.addFields(fields)
|
||||
.setTimestamp()
|
||||
.setFooter({
|
||||
text: `Requested by ${interaction.user.username}`,
|
||||
iconURL: `${interaction.user.displayAvatarURL()}`
|
||||
});
|
||||
interaction.reply({
|
||||
embeds: [embed],
|
||||
ephemeral: ephemeral
|
||||
});
|
||||
}
|
||||
```
|
||||
|
||||
This method allows the bot to handle more detailed responses, such as server resource usage, mod lists, and player data.
|
||||
|
||||
### Error Handling and Resilience
|
||||
|
||||
A critical aspect of the bot’s design is its resilience in the face of errors, particularly around token validation and API requests. The bot gracefully handles errors by attempting to fetch a new token and retrying the request. Additionally, the bot provides users with feedback through embeds when something goes wrong, keeping them informed without the need for manual intervention.
|
||||
|
||||
### Final Thoughts: A Comprehensive Minecraft Server Management Bot
|
||||
|
||||
The My-MC.Link Discord bot is a sophisticated and powerful tool for Minecraft server management, offering a seamless integration with Discord that enables users to perform server tasks through a familiar interface. Its use of modern technologies such as `discord.js`, `MyMCLib`, and JSON-based token management ensures that the bot is both scalable and user-friendly. The automatic token handling, rich embeds, and wide range of server management commands make the bot an invaluable tool for any My-MC.Link user.
|
||||
|
||||
From a technical standpoint, the bot demonstrates how effective integration of Discord with external services can lead to a highly functional and interactive user experience. With the ability to automate token management, handle complex API interactions, and deliver visually appealing feedback, this bot sets a high standard for user-installable applications within the Discord ecosystem.
|
||||
@ -0,0 +1,419 @@
|
||||
<!-- lead -->
|
||||
Breaking Boundaries with a Decentralized, Firewall-Resistant Peer-to-Peer DNS System in Node.js
|
||||
|
||||
DNS is an essential service that translates human-readable domain names into IP addresses. However, it’s currently governed by centralized authorities, requiring domain registration and payments for top-level domains (TLDs). This blog post dives into a revolutionary DNS system implemented in Node.js that leverages peer-to-peer (P2P) networking and UDP hole-punching to create a decentralized, firewall-resistant DNS. This system removes the need for traditional registries and provides users with complete control over their TLDs.
|
||||
|
||||
```bash
|
||||
[DEBUG 2024-10-14T21:04:20.875Z] Public DNS returned records for www.google.com
|
||||
[DEBUG 2024-10-14T21:04:28.465Z] DNS query received: Domain = example.tld, Type = A
|
||||
Virtual interface dummy2 created with CIDR 192.168.100.2.
|
||||
[DEBUG 2024-10-14T21:04:28.527Z] Assigned virtual interface IP: 192.168.100.2 for domain: example.tld
|
||||
[DEBUG 2024-10-14T21:04:28.528Z] Starting Holesail client for domain: example.tld, hash: 8a5b90945f8fbd5d1b620be3c888a47aaae20706a7f140be4bfa0df9e0dbcf38, IP: 192.168.100.2, Port: 80
|
||||
```
|
||||
|
||||
[](https://git.ssh.surf/snxraven/p2ns/raw/branch/main/images/sc.webp)
|
||||
|
||||
# Source:
|
||||
|
||||
## https://git.ssh.surf/snxraven/p2ns
|
||||
|
||||
### The Beginnings
|
||||
|
||||
This P2P DNS system represents a conceptual breakthrough in how DNS can operate. However, it's essential to recognize that the current code is a **proof of concept** and not yet fully equipped for large-scale or production use. As with any pioneering technology, there are significant challenges to address and features to refine.
|
||||
|
||||
One of the primary areas that require attention is **ensuring unique TLD registration across peers**. Currently, the system allows any peer to add a TLD and associated hash to the `dnsCore`, but without a centralized authority or a consensus mechanism, there’s nothing preventing multiple users from registering the same TLD. This can lead to conflicts where different peers assign different IPs or hashes to the same TLD, creating ambiguity and potential security risks.
|
||||
|
||||
Another issue is **data integrity and synchronization**. In decentralized systems, especially those that operate asynchronously like this one, there’s always a chance that data may go out of sync. If peers don’t replicate updates promptly, they might serve outdated or conflicting DNS records. A more robust method for maintaining consistency, perhaps through periodic verification or consensus models, would enhance reliability.
|
||||
|
||||
**Network resilience and performance** also pose challenges. Although Hyperswarm facilitates P2P connectivity, peer connections can be unpredictable, particularly in large, dispersed networks. Connection stability might vary based on network conditions, and without an efficient way to verify peer connectivity, the user experience could degrade over time.
|
||||
|
||||
### Potential Issues to Address
|
||||
|
||||
Other challenges that might arise in the development of a fully functional P2P DNS system include:
|
||||
|
||||
- **Security and Authentication**: Without a centralized verification process, it’s difficult to authenticate peers and ensure only authorized peers participate in a private DNS network. A secure authentication layer or peer verification process would be necessary to prevent unauthorized access.
|
||||
|
||||
- **Redundancy and Conflict Resolution**: In cases where the same TLD exists with different hashes, a conflict-resolution mechanism would be necessary to determine which entry is legitimate. This might involve a voting system or trust-based model where peers agree on the correct record.
|
||||
|
||||
- **Network Performance Overhead**: As the network grows, synchronizing large amounts of data could impact performance, especially for peers with limited bandwidth. Optimizations around data storage, compression, and bandwidth management would be needed to handle network scalability.
|
||||
|
||||
- **Handling Malicious Peers**: In a decentralized network, there’s always the risk of malicious actors attempting to flood the network with junk records or hijacking TLDs. Implementing trust models, perhaps reputation-based or verified peers, could mitigate this risk.
|
||||
|
||||
The current code lays the foundation for a decentralized DNS system that could, in time, replace the need for centralized registries. However, for it to become a robust, production-ready solution, these challenges must be overcome through further research, testing, and community collaboration. As this concept evolves, it has the potential to redefine digital identity, providing a truly autonomous DNS model that’s both resilient and accessible.
|
||||
|
||||
## The Concept: Decentralized DNS with UDP Hole-Punching
|
||||
|
||||
At the heart of this system is the integration of decentralized technologies with resilient connection strategies, primarily UDP hole-punching. This P2P DNS uses Holesail for tunneling and Hyperswarm for establishing peer connections, creating seamless communication between peers across diverse network environments.
|
||||
|
||||
Handling DNS requests through a decentralized P2P framework fundamentally alters the dynamics of DNS:
|
||||
- Centralized DNS servers are no longer required.
|
||||
- Domain registries become irrelevant, as the system allows for self-created TLDs.
|
||||
- Domain purchases and the limitations of traditional TLD structures are eliminated.
|
||||
|
||||
This system redefines DNS, empowering individuals and organizations alike to bypass conventional limitations and establish their own namespaces and domains without dependence on outside entities.
|
||||
|
||||
## Technical Ramifications of a Decentralized DNS System
|
||||
|
||||
Enhanced resilience and uptime come from distributing DNS records across multiple peers. Traditional DNS relies on centralized servers, meaning if one server goes down or is compromised, access for large numbers of users is affected. With a decentralized model, records are distributed across many peers, creating a self-healing, resilient network with no single point of failure. An attack on one peer or group of peers has little to no effect on the network as a whole. By decentralizing the DNS infrastructure, uptime is maximized even if some peers are offline, as remaining peers continue serving the DNS records without interruption.
|
||||
|
||||
UDP hole-punching is a critical feature enabling P2P DNS to function effectively across restrictive networks. Firewalls, NATs, and CGNAT configurations—often found in mobile networks (4G, 5G) and satellite Internet (like Starlink)—typically prevent or limit incoming connections. UDP hole-punching establishes a direct link between peers by creating connection paths through intermediaries, allowing traffic to flow regardless of network restrictions. This makes the system an ideal DNS solution for users in restrictive environments where traditional DNS services may be blocked or monitored. The increased accessibility enables users on restricted networks to participate freely in the DNS network without needing VPNs or additional circumvention tools.
|
||||
|
||||
Local IP assignment offers streamlined peer-to-peer interaction, with IPs dynamically assigned to each domain in the range `192.168.100.x`. Each domain is mapped to a virtual interface within the system’s subnet, leveraging local addresses like `127.0.0.1`. This approach enhances security by isolating domain traffic within the network, preventing direct IP exposure to external sources. Local traffic stays secure and private, and DNS requests are automatically handled within the network, making the system easier to use for both technical and non-technical users.
|
||||
|
||||
## Security and Privacy Implications
|
||||
|
||||
This decentralized DNS model also opens up new possibilities for security and privacy. Unlike traditional DNS, which often involves ISP-based logging, centralized tracking, and even DNS hijacking, a P2P DNS creates a privacy-centric, user-controlled environment.
|
||||
|
||||
Privacy becomes inherent in this model as users retain control over DNS queries, shielding themselves from ISP surveillance and bypassing centralized logging. DNS queries remain private and inaccessible to third-party trackers, thanks to Holesail’s encrypted, peer-to-peer tunneling. Traffic stays encrypted and direct between peers, making it far less vulnerable to interception or manipulation compared to conventional DNS systems.
|
||||
|
||||
Eliminating the need for domain ownership removes the barriers associated with central registries and domain purchasing. No longer bound by regulatory bodies or commercial interests, users can register their own TLDs and subdomains on demand, within the P2P DNS network. This opens up vast possibilities, from small-scale personal projects to enterprise-level applications, without the need to purchase domain names or navigate the policies of registries.
|
||||
|
||||
The structure of this DNS system brings freedom back into the hands of the user, allowing self-regulated control over DNS queries and reducing reliance on ISPs or DNS providers. Users can establish TLDs for internal use, private communication, and personal networks, expanding traditional DNS concepts into a private or exclusive P2P namespace.
|
||||
|
||||
## Use Cases: How the P2P DNS System Can Be Applied
|
||||
|
||||
This system has applications that extend beyond the technical enthusiast community, with potential to transform enterprise, IoT, and digital rights domains.
|
||||
|
||||
In the enterprise sector, organizations often need internal DNS solutions that don’t rely on public infrastructure. This P2P DNS system allows businesses to set up secure, firewall-resistant internal DNS namespaces without involving third-party registries or external providers. Not only does this reduce costs, but it also provides a high level of control and customization for internal domains, from resource isolation to custom TLD configurations.
|
||||
|
||||
For IoT ecosystems, which consist of numerous connected devices often spread across restricted networks, a decentralized DNS provides an efficient, scalable solution for addressing devices without public IPs. Devices can be registered and managed within a private P2P DNS, accessible through firewall-resistant connections that work even in highly restrictive environments.
|
||||
|
||||
Digital rights and censorship-resistant internet advocates stand to benefit greatly from decentralized DNS. Traditional DNS servers can be targeted for censorship, either by disabling access to certain domains or by redirecting users to unwanted sites. With P2P DNS, censorship becomes practically impossible, as there is no single server to target or manipulate. This system empowers users to create and distribute content without the threat of government or corporate suppression.
|
||||
|
||||
## How This System Redefines Freedom in the DNS Landscape
|
||||
|
||||
Beyond the technical benefits, the freedom this system provides to global users is unparalleled. Removing the requirement to purchase or register domains is not just a cost-saving measure—it’s a liberation of identity and accessibility in the digital world. This system enables everyone, from independent users to small organizations, to create their own namespaces without restrictions. In essence, anyone can launch a TLD or subdomain network, using their preferred naming structures with no oversight.
|
||||
|
||||
By establishing a framework where domain registries are optional rather than mandatory, this system bypasses the regulatory and economic gatekeepers traditionally associated with the DNS. It provides a level of freedom that is particularly empowering for communities in restrictive environments, enabling access to an open DNS system that operates independently of conventional controls.
|
||||
|
||||
With this P2P DNS system, the ability to create and maintain digital identities is democratized. Users around the world can reclaim control over their namespaces, creating a more open, resilient, and censorship-resistant Internet. This redefines what it means to have access to the digital world, with a new level of autonomy and security, all powered by decentralized technology.
|
||||
|
||||
## Code Walkthrough: Peer Discovery, DNS, and HTTP Proxying in a P2P Network
|
||||
|
||||
This implementation involves components for peer discovery, DNS resolution, virtual networking, and HTTP proxying, integrating `Hyperswarm` and `Corestore` to achieve a decentralized DNS system. Here's an in-depth analysis:
|
||||
|
||||
### Loading Environment Variables and Dependencies
|
||||
|
||||
The code initializes environment variables with `dotenv`, allowing flexibility in configuring settings like `masterNetworkDiscoveryKey`. This key enables peers to create isolated networks, ensuring only peers with the matching key can discover each other.
|
||||
|
||||
Dependencies:
|
||||
- **`exec`** for executing shell commands.
|
||||
- **`dgram`** for UDP socket communication, essential for DNS operations.
|
||||
- **`dns-packet`** to handle DNS packet creation and decoding.
|
||||
- **`HolesailClient`** to manage P2P tunneling, essential for connecting domains over a decentralized network.
|
||||
- **`Corestore`** for distributed storage, managing and syncing domain records among peers.
|
||||
- **`Hyperswarm`** for peer discovery and creating P2P connections.
|
||||
- **`http`** to handle HTTP requests.
|
||||
- **`crypto`** to manage hashing for secure key generation and identification.
|
||||
|
||||
```javascript
|
||||
require('dotenv').config();
|
||||
const { exec } = require('child_process');
|
||||
const dgram = require('dgram');
|
||||
const dnsPacket = require('dns-packet');
|
||||
const HolesailClient = require('holesail-client');
|
||||
const Corestore = require('corestore');
|
||||
const Hyperswarm = require('hyperswarm');
|
||||
const http = require('http');
|
||||
const { createHash } = require('crypto');
|
||||
const net = require('net');
|
||||
```
|
||||
|
||||
### Corestore and Hyperswarm Configuration
|
||||
|
||||
Here, `Corestore` and `Hyperswarm` are set up to manage decentralized DNS entries and establish peer-to-peer connections, respectively.
|
||||
|
||||
1. **Corestore** serves as a distributed key-value store that allows DNS records to be synchronized across peers.
|
||||
2. **Hyperswarm** is initialized for P2P discovery, using a unique topic derived from `masterNetworkDiscoveryKey` or `dnsCore.discoveryKey`. Only peers with matching topics can join the same swarm, allowing for secure data replication.
|
||||
|
||||
```javascript
|
||||
const store = new Corestore('./my-storage');
|
||||
const swarm = new Hyperswarm();
|
||||
const masterNetworkDiscoveryKey = process.env.masterNetworkDiscoveryKey
|
||||
? Buffer.from(process.env.masterNetworkDiscoveryKey, 'hex')
|
||||
: null;
|
||||
const dnsCore = store.get({ name: 'dns-core' });
|
||||
```
|
||||
|
||||
### Virtual Network Interfaces for Domain Isolation
|
||||
|
||||
Domains are mapped to unique local IP addresses within the `192.168.100.x` subnet. This setup isolates each domain by assigning a virtual network interface for each, thus preventing conflict across domains.
|
||||
|
||||
- **`removeExistingInterface`**: Removes any existing virtual interface to avoid conflicts.
|
||||
- **`createVirtualInterface`**: Uses `ifconfig` to create a local network alias, ensuring each domain has a dedicated IP.
|
||||
- **`createInterfaceForDomain`**: Manages the IP assignment, incrementing the `currentIP` for each new domain.
|
||||
|
||||
```javascript
|
||||
async function createVirtualInterface(subnetName, subnetCIDR) {
|
||||
await removeExistingInterface(subnetName);
|
||||
return new Promise((resolve, reject) => {
|
||||
exec(`sudo ifconfig ${subnetName} alias ${subnetCIDR}`, (err, stdout, stderr) => {
|
||||
if (err) {
|
||||
console.error(`Error creating virtual interface ${subnetName}:`, stderr);
|
||||
reject(`Error creating virtual interface ${subnetName}: ${stderr}`);
|
||||
} else {
|
||||
console.log(`Virtual interface ${subnetName} created with CIDR ${subnetCIDR}.`);
|
||||
resolve(subnetCIDR);
|
||||
}
|
||||
});
|
||||
});
|
||||
}
|
||||
```
|
||||
|
||||
### DNS Server and Query Handling
|
||||
|
||||
The DNS server listens on UDP port 53, decoding and responding to DNS requests. It checks if a domain exists in the P2P DNS core, using fallback mechanisms if needed.
|
||||
|
||||
- **`fetchP2PRecord`**: Retrieves the domain’s hash from the P2P DNS core.
|
||||
- **`checkPublicDNS`**: Resolves domains outside the P2P network by querying Cloudflare’s 1.1.1.1 DNS server.
|
||||
- **DNS Response Logic**: If the domain exists in P2P DNS, it responds with the locally mapped IP; otherwise, it uses the public DNS result.
|
||||
|
||||
```javascript
|
||||
dnsServer.on('message', async (msg, rinfo) => {
|
||||
const query = dnsPacket.decode(msg);
|
||||
const domain = query.questions[0].name;
|
||||
const p2pRecord = await fetchP2PRecord(domain);
|
||||
const publicDNSRecords = await checkPublicDNS(domain);
|
||||
|
||||
if (p2pRecord) {
|
||||
const localIP = await createInterfaceForDomain(domain);
|
||||
startHolesailClient(domain, p2pRecord.hash, localIP, 80);
|
||||
sendDNSResponse(dnsServer, query, rinfo, localIP);
|
||||
} else if (publicDNSRecords) {
|
||||
sendDNSResponse(dnsServer, query, rinfo, publicDNSRecords);
|
||||
}
|
||||
});
|
||||
```
|
||||
|
||||
### Holesail Client for Decentralized Tunneling and Connection Management
|
||||
|
||||
In this implementation, the **Holesail client** is central to achieving decentralized, peer-to-peer (P2P) tunneling, which allows domains to be accessible across peers without relying on a traditional DNS infrastructure. Holesail is a critical component, acting as a secure bridge for domain-specific connections.
|
||||
|
||||
Here's a breakdown of how Holesail functions within this system:
|
||||
|
||||
#### Purpose of Holesail in P2P Networking
|
||||
|
||||
The Holesail client facilitates direct communication between peers, bypassing the need for centralized servers by creating tunnels that connect domains across the network. Each domain entry has a unique hash, which Holesail uses to establish a tunnel. This unique hash acts as an identifier for each domain in the P2P network, ensuring traffic is routed accurately.
|
||||
|
||||
#### Key Functions and Features of Holesail
|
||||
|
||||
1. **Starting Tunnels for P2P Domains**:
|
||||
Holesail uses the domain’s `hash` (generated or retrieved from the P2P DNS core) as an anchor point for the tunnel connection. By associating the domain hash with a unique local IP and port, the Holesail client can reroute incoming requests to the correct peer over the network.
|
||||
|
||||
2. **Automatic Connection Monitoring and Restarting**:
|
||||
Connections in a P2P network can be less stable than in traditional networking. Holesail monitors each tunnel’s status and automatically restarts connections if they become unresponsive. This feature is implemented through a responsive check on each domain’s port. If Holesail detects an issue, it recreates the interface for the domain and starts a new tunnel connection, ensuring continuity of service.
|
||||
|
||||
3. **Connection Reusability**:
|
||||
To optimize resources, Holesail reuses existing connections when possible. Each active connection is stored in the `activeConnections` object, which allows the client to check if a tunnel for a given domain is already active. If a tunnel is found, Holesail reuses it instead of initiating a new one, improving efficiency and reducing resource usage.
|
||||
|
||||
4. **Connection Lifecycle Management**:
|
||||
Each Holesail connection has a lifecycle. To prevent stale or unresponsive connections from lingering, the client uses a timeout mechanism to automatically destroy and remove the tunnel from `activeConnections` after five minutes (300,000 ms). This cleanup process helps conserve resources and ensures only necessary connections remain active.
|
||||
|
||||
5. **Integration with Virtual Interface Management**:
|
||||
When a new connection is needed for a domain, Holesail works alongside the `createInterfaceForDomain` function, which assigns a unique local IP to each domain. This allows domains to be isolated within the local network and ensures that each has a dedicated path through which Holesail can route traffic. By maintaining the virtual interface alongside the tunnel, Holesail manages traffic seamlessly across peers.
|
||||
|
||||
#### Code Example of Holesail Connection Management
|
||||
|
||||
Here's how Holesail is used to start and manage a P2P connection:
|
||||
|
||||
```javascript
|
||||
async function startHolesailClient(domain, hash, ip, port) {
|
||||
logDebug(`Attempting to start/reuse Holesail client for domain: ${domain}`);
|
||||
|
||||
if (activeConnections[domain]) {
|
||||
logDebug(`Reusing existing Holesail client for domain: ${domain} on ${ip}:${port}`);
|
||||
return activeConnections[domain];
|
||||
}
|
||||
|
||||
logDebug(`Starting new Holesail client for domain: ${domain}, hash: ${hash}, IP: ${ip}, Port: ${port}`);
|
||||
|
||||
const connector = setupConnector(hash);
|
||||
const holesailClient = new HolesailClient(connector);
|
||||
|
||||
holesailClient.connect({ port: port, address: ip, reuseAddr: true }, () => {
|
||||
logDebug(`Holesail client for ${domain} connected on ${ip}:${port}`);
|
||||
});
|
||||
|
||||
activeConnections[domain] = holesailClient;
|
||||
|
||||
setTimeout(() => {
|
||||
logDebug(`Destroying Holesail client for domain ${domain}`);
|
||||
holesailClient.destroy();
|
||||
delete activeConnections[domain];
|
||||
}, 300000);
|
||||
|
||||
return holesailClient;
|
||||
}
|
||||
```
|
||||
|
||||
In this function:
|
||||
- **`setupConnector(hash)`** sets up the connector with the domain’s hash, allowing Holesail to identify and route traffic correctly.
|
||||
- **`holesailClient.connect()`** initiates the connection to the specified IP and port, handling requests sent to the domain.
|
||||
- **Timeout for Connection Lifecycle** ensures the tunnel is automatically destroyed if unused, freeing up resources.
|
||||
|
||||
Holesail is essential for bridging the gap between DNS resolution and accessible peer connections. By using Holesail, each domain can securely connect across peers within the P2P network, overcoming traditional DNS constraints and enabling a scalable, decentralized DNS solution.
|
||||
|
||||
### HTTP Proxy for Routing P2P Traffic
|
||||
|
||||
The HTTP proxy listens on port 80 and reroutes traffic to the appropriate IP for domains within the P2P network. This enables HTTP-based access for P2P-resolved domains.
|
||||
|
||||
```javascript
|
||||
http.createServer(async (req, res) => {
|
||||
const domain = req.url.replace("/", "");
|
||||
const localIP = await createInterfaceForDomain(domain);
|
||||
|
||||
await restartHolesailClient(domain, 'master_hash', localIP, 80);
|
||||
const options = { hostname: localIP, port: 80, path: req.url, method: req.method, headers: req.headers };
|
||||
|
||||
const proxyRequest = http.request(options, (proxyRes) => {
|
||||
res.writeHead(proxyRes.statusCode, proxyRes.headers);
|
||||
proxyRes.pipe(res);
|
||||
});
|
||||
proxyRequest.on('error', () => res.writeHead(500).end('Error'));
|
||||
req.pipe(proxyRequest);
|
||||
}).listen(80, '127.0.0.1');
|
||||
```
|
||||
|
||||
### Synchronizing DNS Records Across Peers
|
||||
|
||||
The `addDomain` function enables peers to add new domains to the P2P DNS system, appending records to `dnsCore`, making them accessible and synchronized across the network.
|
||||
|
||||
```javascript
|
||||
async function addDomain(domain, hash) {
|
||||
await dnsCore.ready();
|
||||
const record = JSON.stringify({ domain, hash });
|
||||
await dnsCore.append(Buffer.from(record));
|
||||
logDebug(`Domain ${domain} added to DNS core`);
|
||||
}
|
||||
```
|
||||
|
||||
### Hyperswarm Integration for Peer Synchronization
|
||||
|
||||
The DNS core joins the Hyperswarm network using the configured `masterNetworkDiscoveryKey`, ensuring only authorized peers connect and sync DNS data.
|
||||
|
||||
```javascript
|
||||
(async () => {
|
||||
await dnsCore.ready();
|
||||
const topic = masterNetworkDiscoveryKey || dnsCore.discoveryKey;
|
||||
logDebug(`DNS Core ready, joining Hyperswarm with topic: ${topic.toString('hex')}`);
|
||||
swarm.join(topic, { server: true, client: true });
|
||||
|
||||
swarm.on('connection', (conn) => {
|
||||
logDebug('Peer connected, starting replication...');
|
||||
dnsCore.replicate(conn);
|
||||
});
|
||||
})();
|
||||
```
|
||||
|
||||
### Expanding DNS Record Types for P2P Networks with Hyperdrive in `dnsCore` (Theoretical Concept)
|
||||
|
||||
In this system, **Hyperdrive** integrated with `dnsCore` presents a theoretical framework for handling various custom DNS record types. While traditional DNS has a limited set of record types, these hypothetical record types illustrate how P2P-specific records could be organized by top-level domain (TLD) to manage unique functionalities across a decentralized network.
|
||||
|
||||
> **Note:** The following examples represent a conceptual approach. These custom record types do not currently exist in the codebase, but they demonstrate how this system could theoretically be extended to handle complex, decentralized data needs.
|
||||
|
||||
1. **TX (Transaction)**:
|
||||
- Under domains like `account.example.p2p`, a `TX` record could store transaction details, ideal for decentralized finance (DeFi) and smart contracts. Each `TX` record would manage transaction histories or balances and could be synchronized across peers using `dnsCore`.
|
||||
|
||||
```javascript
|
||||
// Hypothetical TX record for the example.p2p domain
|
||||
const txDrive = new Hyperdrive(store, { name: 'account.example.p2p' });
|
||||
await txDrive.ready();
|
||||
await txDrive.put('/tx/wallet123.json', Buffer.from(JSON.stringify({
|
||||
type: "TX",
|
||||
txId: "abc123",
|
||||
amount: 100,
|
||||
currency: "ETH",
|
||||
timestamp: Date.now()
|
||||
})));
|
||||
dnsCore.replicate(txDrive.core);
|
||||
```
|
||||
|
||||
2. **PEER**:
|
||||
- For domains like `node.service.peer`, a `PEER` record could theoretically store peer information such as public keys, IP addresses, or resource capabilities (e.g., storage, compute power). This would enable efficient resource sharing and peer discovery across the network.
|
||||
|
||||
```javascript
|
||||
// Hypothetical PEER record for the service.peer domain
|
||||
const peerDrive = new Hyperdrive(store, { name: 'node.service.peer' });
|
||||
await peerDrive.ready();
|
||||
await peerDrive.put('/peers/node456.json', Buffer.from(JSON.stringify({
|
||||
type: "PEER",
|
||||
publicKey: "abcdef...",
|
||||
ip: "192.168.1.1",
|
||||
capabilities: ["storage", "compute"],
|
||||
timestamp: Date.now()
|
||||
})));
|
||||
dnsCore.replicate(peerDrive.core);
|
||||
```
|
||||
|
||||
3. **FINGERPRINT**:
|
||||
- Under domains like `device.secure.tld`, a `FINGERPRINT` record could theoretically store cryptographic identifiers associated with devices or software versions. This would allow nodes to verify the integrity of hardware or software configurations before establishing connections.
|
||||
|
||||
```javascript
|
||||
// Hypothetical FINGERPRINT record for the secure.tld domain
|
||||
const fingerprintDrive = new Hyperdrive(store, { name: 'device.secure.tld' });
|
||||
await fingerprintDrive.ready();
|
||||
await fingerprintDrive.put('/fingerprint/device123.json', Buffer.from(JSON.stringify({
|
||||
type: "FINGERPRINT",
|
||||
fingerprint: "unique-device-hash",
|
||||
deviceType: "sensor",
|
||||
softwareVersion: "v1.0.0",
|
||||
timestamp: Date.now()
|
||||
})));
|
||||
dnsCore.replicate(fingerprintDrive.core);
|
||||
```
|
||||
|
||||
4. **CONTENT**:
|
||||
- A `CONTENT` record under domains like `media.site.p2p` could theoretically serve as a decentralized content delivery record, storing metadata for files or media associated with the domain. This approach could support distributed websites or applications across peers.
|
||||
|
||||
```javascript
|
||||
// Hypothetical CONTENT record for the site.p2p domain
|
||||
const contentDrive = new Hyperdrive(store, { name: 'media.site.p2p' });
|
||||
await contentDrive.ready();
|
||||
await contentDrive.put('/content/video-metadata.json', Buffer.from(JSON.stringify({
|
||||
type: "CONTENT",
|
||||
title: "Decentralized Video",
|
||||
contentHash: "content-hash",
|
||||
author: "AuthorName",
|
||||
timestamp: Date.now()
|
||||
})));
|
||||
dnsCore.replicate(contentDrive.core);
|
||||
```
|
||||
|
||||
5. **AUTH (Authentication Data)**:
|
||||
- Although purely theoretical, an `AUTH` record under domains like `auth.node.peer` could store access tokens or permissions, supporting decentralized access control across the network. This would allow peers to manage encrypted credentials or control access to resources.
|
||||
|
||||
```javascript
|
||||
// Hypothetical AUTH record for the node.peer domain
|
||||
const authDrive = new Hyperdrive(store, { name: 'auth.node.peer' });
|
||||
await authDrive.ready();
|
||||
await authDrive.put('/auth/peer-access.json', Buffer.from(JSON.stringify({
|
||||
type: "AUTH",
|
||||
peer: "peer123",
|
||||
permissions: ["read", "write"],
|
||||
accessToken: "encrypted-token",
|
||||
timestamp: Date.now()
|
||||
})));
|
||||
dnsCore.replicate(authDrive.core);
|
||||
```
|
||||
|
||||
These examples are intended to provide a vision for how `dnsCore` and Hyperdrive could be expanded with domain-specific TLD storage in a fully decentralized DNS system, although they are not implemented in the current codebase.
|
||||
|
||||
#### Customizing DNS Records for P2P Flexibility
|
||||
|
||||
While these record types are theoretical, they represent exciting possibilities for how `dnsCore` and Hyperdrive could be customized to meet the unique requirements of decentralized networks. Future implementations could redefine DNS concepts to support service discovery, data replication, and secure peer communication within a dynamic, P2P-friendly environment.
|
||||
|
||||
## Security and Privacy Implications
|
||||
|
||||
This P2P DNS system’s architecture offers significant privacy advantages. By decentralizing DNS queries and encrypting traffic over Holesail tunnels, it:
|
||||
- Prevents ISPs from logging or tracking DNS requests.
|
||||
- Protects DNS data from centralized surveillance or censorship.
|
||||
- Enables users to create their own namespaces without interference from external authorities.
|
||||
|
||||
|
||||
## Use Cases: Expanding Applications Beyond Traditional DNS
|
||||
|
||||
The applications of this P2P DNS system are vast. Beyond typical DNS, it allows users to create isolated namespaces for organizational use, IoT device management, and censorship-resistant communication. By removing centralized control, it empowers users with autonomy and flexibility over their digital presence.
|
||||
|
||||
## New Era of DNS Freedom
|
||||
|
||||
This decentralized, firewall-resistant P2P DNS system implemented in Node.js offers a resilient, censorship-resistant alternative to traditional DNS. By combining Corestore, Hyperswarm, and Holesail, it provides the infrastructure needed for a free, self-governing Internet. This DNS solution enables users around the world to reclaim control over their digital identities, creating a more open, accessible, and secure online ecosystem.
|
||||
2252
markdown/Deep Dive: Discord-Linux Automated Container Platform.md
Normal file
@ -0,0 +1,504 @@
|
||||
<!-- lead -->
|
||||
Monitoring containerized applications is essential for ensuring optimal performance, diagnosing issues promptly, and maintaining overall system health.
|
||||
|
||||
In a dynamic environment where containers can be spun up or down based on demand, having a flexible and responsive monitoring solution becomes even more critical. This article delves into how I utilize the Netdata REST API to generate real-time, visually appealing graphs and an interactive dashboard for each container dynamically. By integrating technologies like Node.js, Express.js, Chart.js, Docker, and web sockets, I create a seamless monitoring experience that provides deep insights into container performance metrics.
|
||||
|
||||
## Example Dynamic Page
|
||||
|
||||
https://ssh42113405732790.syscall.lol/
|
||||
|
||||
|
||||
## Introduction
|
||||
|
||||
As containerization becomes the backbone of modern application deployment, monitoring solutions need to adapt to the ephemeral nature of containers. Traditional monitoring tools may not provide the granularity or real-time feedback necessary for containerized environments. Netdata, with its poIrful real-time monitoring capabilities and RESTful API, offers a robust solution for collecting and accessing performance metrics. By leveraging the Netdata REST API, I can fetch detailed metrics about CPU usage, memory consumption, network traffic, disk I/O, and running processes within each container.
|
||||
|
||||
Our goal is to create an interactive dashboard that not only displays these metrics in real-time but also provides users with the ability to interact with the data, such as filtering processes or adjusting timeframes. To achieve this, I build a backend server that interfaces with the Netdata API, processes the data, and serves it to the frontend where it's rendered using Chart.js and other web technologies.
|
||||
|
||||
## System Architecture
|
||||
|
||||
Understanding the system architecture is crucial to grasp how each component interacts to provide a cohesive monitoring solution. The architecture comprises several key components:
|
||||
|
||||
1. **Netdata Agent**: Installed on the host machine, it collects real-time performance metrics and exposes them via a RESTful API.
|
||||
2. **Backend Server**: A Node.js application built with Express.js that serves as an intermediary betIen the Netdata API and the frontend clients.
|
||||
3. **Interactive Dashboard**: A web interface that displays real-time graphs and system information, built using HTML, CSS, JavaScript, and libraries like Chart.js.
|
||||
4. **Docker Integration**: Utilizing Dockerode, a Node.js Docker client, to interact with Docker containers, fetch process lists, and verify container existence.
|
||||
5. **Proxy Server**: Routes incoming requests to the appropriate container's dashboard based on subdomain mapping.
|
||||
6. **Discord Bot**: Allows users to request performance graphs directly from Discord, enhancing accessibility and user engagement.
|
||||
|
||||
### Data Flow
|
||||
|
||||
- The Netdata Agent continuously collects performance metrics and makes them available via its RESTful API.
|
||||
- The Backend Server fetches data from the Netdata API based on requests from clients or scheduled intervals.
|
||||
- The Interactive Dashboard requests data from the Backend Server, which processes and serves it in a format suitable for visualization.
|
||||
- Docker Integration ensures that the system is aware of the running containers and can fetch container-specific data.
|
||||
- The Proxy Server handles subdomain-based routing, directing users to the correct dashboard for their container.
|
||||
- The Discord Bot interacts with the Backend Server to fetch graphs and sends them to users upon request.
|
||||
|
||||
## Backend Server Implementation
|
||||
|
||||
The backend server is the linchpin of our monitoring solution. It handles data fetching, processing, and serves as an API endpoint for the frontend dashboard and the Discord bot.
|
||||
|
||||
### Setting Up Express.js Server
|
||||
|
||||
I start by setting up an Express.js server that listens for incoming HTTP requests. The server is configured to handle Cross-Origin Resource Sharing (CORS) to allow requests from different origins, which is essential for serving the dashboard to users accessing it from various domains.
|
||||
|
||||
```javascript
|
||||
const express = require('express');
|
||||
const app = express();
|
||||
const port = 6666;
|
||||
|
||||
app.use(cors()); // Enable CORS
|
||||
app.listen(port, "0.0.0.0", () => {
|
||||
console.log(`Server running on http://localhost:${port}`);
|
||||
});
|
||||
```
|
||||
|
||||
### Interacting with Netdata API
|
||||
|
||||
To fetch metrics from Netdata, I define a function that constructs the appropriate API endpoints based on the container ID and the desired timeframe.
|
||||
|
||||
```javascript
|
||||
const axios = require('axios');
|
||||
|
||||
const getEndpoints = (containerId, timeframe) => {
|
||||
const after = -(timeframe * 60); // Timeframe in seconds
|
||||
return {
|
||||
cpu: `http://netdata.local/api/v1/data?chart=cgroup_${containerId}.cpu&format=json&after=${after}`,
|
||||
memory: `http://netdata.local/api/v1/data?chart=cgroup_${containerId}.mem_usage&format=json&after=${after}`,
|
||||
// Additional endpoints for io, pids, network...
|
||||
};
|
||||
};
|
||||
```
|
||||
|
||||
I then define a function to fetch data for a specific metric:
|
||||
|
||||
```javascript
|
||||
const fetchMetricData = async (metric, containerId, timeframe = 5) => {
|
||||
const endpoints = getEndpoints(containerId, timeframe);
|
||||
try {
|
||||
const response = await axios.get(endpoints[metric]);
|
||||
return response.data;
|
||||
} catch (error) {
|
||||
console.error(`Error fetching ${metric} data for container ${containerId}:`, error);
|
||||
throw new Error(`Failed to fetch ${metric} data.`);
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
### Data Processing
|
||||
|
||||
Once I have the raw data from Netdata, I need to process it to extract timestamps and values suitable for graphing. The data returned by Netdata is typically in a time-series format, with each entry containing a timestamp and one or more metric values.
|
||||
|
||||
```javascript
|
||||
const extractMetrics = (data, metric) => {
|
||||
const labels = data.data.map((entry) => new Date(entry[0] * 1000).toLocaleTimeString());
|
||||
let values;
|
||||
|
||||
switch (metric) {
|
||||
case 'cpu':
|
||||
case 'memory':
|
||||
case 'pids':
|
||||
values = data.data.map(entry => entry[1]); // Adjust index based on metric specifics
|
||||
break;
|
||||
case 'io':
|
||||
values = {
|
||||
read: data.data.map(entry => entry[1]),
|
||||
write: data.data.map(entry => entry[2]),
|
||||
};
|
||||
break;
|
||||
case 'network':
|
||||
values = {
|
||||
received: data.data.map(entry => entry[1]),
|
||||
sent: data.data.map(entry => entry[2]),
|
||||
};
|
||||
break;
|
||||
default:
|
||||
values = [];
|
||||
}
|
||||
|
||||
return { labels, values };
|
||||
};
|
||||
```
|
||||
|
||||
### Graph Generation with Chart.js
|
||||
|
||||
To generate graphs, I use the `chartjs-node-canvas` library, which allows us to render Chart.js graphs server-side and output them as images.
|
||||
|
||||
```javascript
|
||||
const { ChartJSNodeCanvas } = require('chartjs-node-canvas');
|
||||
const chartJSMetricCanvas = new ChartJSNodeCanvas({ width: 1900, height: 400, backgroundColour: 'black' });
|
||||
|
||||
const generateMetricGraph = async (metricData, labels, label, borderColor) => {
|
||||
const configuration = {
|
||||
type: 'line',
|
||||
data: {
|
||||
labels: labels,
|
||||
datasets: [{
|
||||
label: label,
|
||||
data: metricData,
|
||||
borderColor: borderColor,
|
||||
fill: false,
|
||||
tension: 0.1,
|
||||
}],
|
||||
},
|
||||
options: {
|
||||
scales: {
|
||||
x: {
|
||||
title: {
|
||||
display: true,
|
||||
text: 'Time',
|
||||
color: 'white',
|
||||
},
|
||||
},
|
||||
y: {
|
||||
title: {
|
||||
display: true,
|
||||
text: `${label} Usage`,
|
||||
color: 'white',
|
||||
},
|
||||
},
|
||||
},
|
||||
plugins: {
|
||||
legend: {
|
||||
labels: {
|
||||
color: 'white',
|
||||
},
|
||||
},
|
||||
},
|
||||
},
|
||||
};
|
||||
|
||||
return chartJSMetricCanvas.renderToBuffer(configuration);
|
||||
};
|
||||
```
|
||||
|
||||
This function takes the metric data, labels, and graph styling options to produce a PNG image buffer of the graph, which can then be sent to clients or used in the dashboard.
|
||||
|
||||
### API Endpoints for Metrics
|
||||
|
||||
I define API endpoints for each metric that clients can request. For example, the CPU usage endpoint:
|
||||
|
||||
```javascript
|
||||
app.get('/api/graph/cpu/:containerId', async (req, res) => {
|
||||
const { containerId } = req.params;
|
||||
const timeframe = parseInt(req.query.timeframe) || 5;
|
||||
const format = req.query.format || 'graph';
|
||||
|
||||
try {
|
||||
const data = await fetchMetricData('cpu', containerId, timeframe);
|
||||
if (format === 'json') {
|
||||
return res.json(data);
|
||||
}
|
||||
|
||||
const { labels, values } = extractMetrics(data, 'cpu');
|
||||
const imageBuffer = await generateMetricGraph(values, labels, 'CPU Usage (%)', 'rgba(255, 99, 132, 1)');
|
||||
res.set('Content-Type', 'image/png');
|
||||
res.send(imageBuffer);
|
||||
} catch (error) {
|
||||
res.status(500).send(`Error generating CPU graph: ${error.message}`);
|
||||
}
|
||||
});
|
||||
```
|
||||
|
||||
Similar endpoints are created for memory, network, disk I/O, and PIDs.
|
||||
|
||||
### Full Report Generation
|
||||
|
||||
For users who want a comprehensive view of their container's performance, I offer a full report that combines all the individual graphs into one image.
|
||||
|
||||
```javascript
|
||||
app.get('/api/graph/full-report/:containerId', async (req, res) => {
|
||||
// Fetch data for all metrics
|
||||
// Generate graphs for each metric
|
||||
// Combine graphs into a single image using Canvas
|
||||
// Send the final image to the client
|
||||
});
|
||||
```
|
||||
|
||||
By using the `canvas` and `loadImage` modules, I can composite multiple graphs into a single image, adding titles and styling as needed.
|
||||
|
||||
## Interactive Dashboard
|
||||
|
||||
The interactive dashboard provides users with real-time insights into their container's performance. It is designed to be responsive, visually appealing, and informative.
|
||||
|
||||
### Live Data Updates
|
||||
|
||||
To achieve real-time updates, I use client-side JavaScript to periodically fetch the latest data from the backend server. I use `setInterval` to schedule data fetches every second or at a suitable interval based on performance considerations.
|
||||
|
||||
```html
|
||||
<script>
|
||||
async function updateGraphs() {
|
||||
const response = await fetch(`/api/graph/full-report/${containerId}?format=json&timeframe=1`);
|
||||
const data = await response.json();
|
||||
// Update charts with new data
|
||||
}
|
||||
|
||||
setInterval(updateGraphs, 1000);
|
||||
</script>
|
||||
```
|
||||
|
||||
### Chart.js Integration
|
||||
|
||||
I use Chart.js on the client side to render graphs directly in the browser. This allows for smooth animations and interactivity.
|
||||
|
||||
```javascript
|
||||
const cpuChart = new Chart(cpuCtx, {
|
||||
type: 'line',
|
||||
data: {
|
||||
labels: [],
|
||||
datasets: [{
|
||||
label: 'CPU Usage (%)',
|
||||
data: [],
|
||||
borderColor: 'rgba(255, 99, 132, 1)',
|
||||
borderWidth: 2,
|
||||
pointRadius: 3,
|
||||
fill: false,
|
||||
}]
|
||||
},
|
||||
options: {
|
||||
animation: { duration: 500 },
|
||||
responsive: true,
|
||||
maintainAspectRatio: false,
|
||||
scales: {
|
||||
x: { grid: { color: 'rgba(255, 255, 255, 0.1)' } },
|
||||
y: { grid: { color: 'rgba(255, 255, 255, 0.1)' } }
|
||||
},
|
||||
plugins: { legend: { display: false } }
|
||||
}
|
||||
});
|
||||
```
|
||||
|
||||
### Process List Display
|
||||
|
||||
An essential aspect of container monitoring is understanding what processes are running inside the container. I fetch the process list using Docker's API and display it in a searchable table.
|
||||
|
||||
```javascript
|
||||
// Backend endpoint
|
||||
app.get('/api/processes/:containerId', async (req, res) => {
|
||||
const { containerId } = req.params;
|
||||
try {
|
||||
const container = docker.getContainer(containerId);
|
||||
const processes = await container.top();
|
||||
res.json(processes.Processes || []);
|
||||
} catch (err) {
|
||||
console.error(`Error fetching processes for container ${containerId}:`, err);
|
||||
res.status(500).json({ error: 'Failed to fetch processes' });
|
||||
}
|
||||
});
|
||||
|
||||
// Client-side function to update the process list
|
||||
async function updateProcessList() {
|
||||
const processResponse = await fetch(`/api/processes/${containerId}`);
|
||||
const processList = await processResponse.json();
|
||||
// Render the process list in the table
|
||||
}
|
||||
```
|
||||
|
||||
I enhance the user experience by adding a search box that allows users to filter the processes by PID, user, or command.
|
||||
|
||||
### Visual Enhancements
|
||||
|
||||
To make the dashboard more engaging, I incorporate visual elements like particle effects using libraries like `particles.js`. I also apply a dark theme with styling that emphasizes the data visualizations.
|
||||
|
||||
```css
|
||||
body {
|
||||
background-color: #1c1c1c;
|
||||
color: white;
|
||||
font-family: Arial, sans-serif;
|
||||
}
|
||||
```
|
||||
|
||||
### Responsive Design
|
||||
|
||||
Using Bootstrap and custom CSS, I ensure that the dashboard is responsive and accessible on various devices and screen sizes.
|
||||
|
||||
```html
|
||||
<link href="https://cdn.jsdelivr.net/npm/bootstrap@5.3.0-alpha1/dist/css/bootstrap.min.css" rel="stylesheet">
|
||||
<div class="container mt-4">
|
||||
<!-- Dashboard content -->
|
||||
</div>
|
||||
```
|
||||
|
||||
## Docker Integration
|
||||
|
||||
Docker plays a pivotal role in our system, not just for running the containers but also for providing data about them.
|
||||
|
||||
### Fetching Container Information
|
||||
|
||||
I use the `dockerode` library to interact with Docker:
|
||||
|
||||
```javascript
|
||||
const Docker = require('dockerode');
|
||||
const docker = new Docker();
|
||||
|
||||
async function containerExists(subdomain) {
|
||||
try {
|
||||
const containers = await docker.listContainers();
|
||||
return containers.some(container => container.Names.some(name => name.includes(subdomain)));
|
||||
} catch (error) {
|
||||
console.error(`Error checking Docker for subdomain ${subdomain}:`, error.message);
|
||||
return false;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
This function checks whether a container corresponding to a subdomain exists, which is essential for routing and security purposes.
|
||||
|
||||
### Fetching Process Lists
|
||||
|
||||
As mentioned earlier, I can retrieve the list of processes running inside a container:
|
||||
|
||||
```javascript
|
||||
const container = docker.getContainer(containerId);
|
||||
const processes = await container.top();
|
||||
```
|
||||
|
||||
This allows us to display detailed information about what's happening inside the container, which can be invaluable for debugging and monitoring.
|
||||
|
||||
## Proxy Server for web UI
|
||||
|
||||
To provide users with a seamless experience, I set up a proxy server that routes requests to the appropriate container dashboards based on subdomains.
|
||||
|
||||
### Subdomain-Based Routing
|
||||
|
||||
I parse the incoming request's hostname to extract the subdomain, which corresponds to a container ID.
|
||||
|
||||
```javascript
|
||||
app.use(async (req, res, next) => {
|
||||
const host = req.hostname;
|
||||
let subdomain = host.split('.')[0].toUpperCase();
|
||||
|
||||
if (!subdomain || ['LOCALHOST', 'WWW', 'SYSCALL'].includes(subdomain)) {
|
||||
return res.redirect('https://discord-linux.com');
|
||||
}
|
||||
|
||||
const exists = await containerExists(subdomain);
|
||||
if (!exists) {
|
||||
return res.redirect('https://discord-linux.com');
|
||||
}
|
||||
|
||||
// Proceed to proxy the request
|
||||
});
|
||||
```
|
||||
|
||||
### Proxying Requests
|
||||
|
||||
Using `http-proxy-middleware`, I forward the requests to the backend server's live dashboard endpoint:
|
||||
|
||||
```javascript
|
||||
const { createProxyMiddleware } = require('http-proxy-middleware');
|
||||
|
||||
createProxyMiddleware({
|
||||
target: `https://g.syscall.lol/full-report/${subdomain}`,
|
||||
changeOrigin: true,
|
||||
pathRewrite: {
|
||||
'^/': '/live', // Rewrite the root path to /live
|
||||
}
|
||||
})(req, res, next);
|
||||
```
|
||||
|
||||
This setup allows users to access their container's dashboard by visiting a URL like `https://SSH42113405732790.syscall.lol`, where `SSH42113405732790` is the container ID.
|
||||
|
||||
## Discord Bot Integration
|
||||
|
||||
To make the monitoring solution more accessible, I integrate a Discord bot that allows users to request graphs and reports directly within Discord.
|
||||
|
||||
### Command Handling
|
||||
|
||||
I define a `graph` command that users can invoke to get performance graphs:
|
||||
|
||||
```javascript
|
||||
module.exports = {
|
||||
name: "graph",
|
||||
description: "Retrieves a graph report for your container.",
|
||||
options: [
|
||||
// Command options for report type, timeframe, etc.
|
||||
],
|
||||
run: async (client, interaction) => {
|
||||
// Command implementation
|
||||
},
|
||||
};
|
||||
```
|
||||
|
||||
### User Authentication
|
||||
|
||||
I authenticate users by matching their Discord ID with the container IDs stored in our database:
|
||||
|
||||
```javascript
|
||||
let sshSurfID;
|
||||
connection.query(
|
||||
"SELECT uid FROM users WHERE discord_id = ?",
|
||||
[interaction.user.id],
|
||||
(err, results) => {
|
||||
if (results.length === 0) {
|
||||
interaction.editReply("Sorry, you do not have a container associated with your account.");
|
||||
} else {
|
||||
sshSurfID = results[0].uid;
|
||||
}
|
||||
}
|
||||
);
|
||||
```
|
||||
|
||||
### Fetching and Sending Graphs
|
||||
|
||||
Once I have the user's container ID, I fetch the graph image from the backend server and send it as a reply in Discord:
|
||||
|
||||
```javascript
|
||||
const apiUrl = `https://g.syscall.lol/${reportType}/${sshSurfID}?timeframe=${timeframe}`;
|
||||
const response = await axios.get(apiUrl, { responseType: 'stream' });
|
||||
// Send the image in the reply
|
||||
await interaction.editReply({
|
||||
files: [{
|
||||
attachment: response.data,
|
||||
name: `${reportType}_graph.png`
|
||||
}]
|
||||
});
|
||||
```
|
||||
|
||||
This integration provides users with an easy way to monitor their containers without leaving Discord.
|
||||
|
||||
## Security Considerations
|
||||
|
||||
When building a monitoring system, especially one that exposes container data over the network, security is paramount.
|
||||
|
||||
### Access Control
|
||||
|
||||
I ensure that only authenticated users can access the data for their containers. This involves:
|
||||
|
||||
- Verifying container existence and ownership before serving data.
|
||||
- Using secure communication protocols (HTTPS) to encrypt data in transit.
|
||||
- Implementing proper authentication mechanisms in the backend server and Discord bot.
|
||||
|
||||
### Input Validation
|
||||
|
||||
I sanitize and validate all inputs, such as container IDs, to prevent injection attacks and unauthorized access.
|
||||
|
||||
### Rate Limiting
|
||||
|
||||
To protect against Denial of Service (DoS) attacks, I can implement rate limiting on API endpoints.
|
||||
|
||||
## Performance Optimizations
|
||||
|
||||
To ensure the system performs Ill under load, I implement several optimizations:
|
||||
|
||||
- **Caching**: Cache frequently requested data to reduce load on the Netdata Agent and backend server.
|
||||
- **Efficient Data Structures**: Use efficient data structures and algorithms for data processing.
|
||||
- **Asynchronous Operations**: Utilize asynchronous programming to prevent blocking operations.
|
||||
- **Load Balancing**: Distribute incoming requests across multiple instances of the backend server if needed.
|
||||
|
||||
## Future Enhancements
|
||||
|
||||
There are several areas where I can expand and improve the monitoring solution:
|
||||
|
||||
- **Alerting Mechanisms**: Integrate alerting to notify users of critical events or thresholds being exceeded.
|
||||
- **Historical Data Analysis**: Store metrics over longer periods for trend analysis and capacity planning.
|
||||
- **Custom Metrics**: Allow users to define custom metrics or integrate with application-level monitoring.
|
||||
- **Mobile Accessibility**: Optimize the dashboard for mobile devices or create a dedicated mobile app.
|
||||
|
||||
## My Thoughts
|
||||
|
||||
By leveraging the Netdata REST API and integrating it with modern web technologies, I have built a dynamic and interactive monitoring solution tailored for containerized environments. The combination of real-time data visualization, user-friendly interfaces, and accessibility through platforms like Discord empoIrs users to maintain and optimize their applications effectively.
|
||||
|
||||
This approach showcases the poIr of combining open-source tools and technologies to solve complex monitoring challenges in a scalable and efficient manner. As containerization continues to evolve, such solutions will become increasingly vital in managing and understanding the performance of distributed applications.
|
||||
|
||||
*Note: The code snippets provided are simplified for illustrative purposes. In a production environment, additional error handling, security measures, and optimizations should be implemented.*
|
||||
@ -0,0 +1,257 @@
|
||||
<!-- lead -->
|
||||
Creating a Linux Based Hosting Solution for Twitter.
|
||||
|
||||
It all started with a question that initially seemed a bit absurd: *Could you manage a Linux server using only Twitter?* At first glance, the idea appeared impractical. After all, social media platforms aren’t exactly designed for hosting virtual machines or executing server-side commands. But, as someone who thrives on pushing boundaries, I decided to take this concept and run with it.
|
||||
|
||||
I envisioned a Twitter bot that could host Linux containers, execute commands, and interact with users all through tweets. In the end, this project led me to become what I believe is the first person to host Linux containers directly through Twitter interactions. This blog post will take you through the entire process in meticulous detail — from conceptualizing the idea, writing the code, and overcoming challenges, to launching the bot and maintaining it.
|
||||
|
||||
<p align="center">
|
||||
<img src="https://raven-scott.fyi/twit_linux.webp" alt="Twit Linux">
|
||||
</p>
|
||||
|
||||
# Source
|
||||
|
||||
## https://git.ssh.surf/snxraven/codename-t
|
||||
|
||||
Some scripts mentioned in the above code are covered in the below Blog Post:
|
||||
https://blog.raven-scott.fyi/deep-dive-discord-linux-automated-container-platform
|
||||
|
||||
### The Concept: Why Twitter for Linux Hosting?
|
||||
|
||||
Before diving into the technical details, it’s important to understand the motivations behind this project. The world of DevOps and Linux system administration is traditionally one of terminals, SSH keys, and intricate scripts. However, I wanted to bring this technical space to a more social, accessible environment. And what better place to do that than Twitter, a platform where millions of people spend their time daily?
|
||||
|
||||
The goal was simple: **I wanted to democratize Linux hosting by allowing users to spin up containers, execute commands, and even destroy their own instances — all with a tweet.**
|
||||
|
||||
Social media, particularly Twitter, has built-in engagement mechanisms that could make such a concept interactive and fun. Moreover, it would introduce new audiences to Linux without requiring them to navigate the complexities of traditional terminal-based environments. Instead, they could tweet commands like `neofetch` or `apt update` and have my bot respond with the command’s output.
|
||||
|
||||
Let’s break down how I made it all work.
|
||||
|
||||
|
||||
|
||||
## Phase 1: Setting Up the Infrastructure
|
||||
|
||||
### Tools and Technologies
|
||||
To pull this off, I needed a robust stack of tools and technologies. The project hinged on several core technologies, which I’ll go over here:
|
||||
|
||||
1. **Node.js**: JavaScript’s asynchronous nature makes it ideal for handling Twitter streams and Docker management, two of the key tasks in this project.
|
||||
2. **Docker**: Docker allows us to create isolated Linux environments for each user who interacts with the bot. Containers are lightweight, ephemeral, and easy to manage — perfect for this use case.
|
||||
3. **Twit and Twitter API SDK**: Twit and the Twitter SDK provide all the necessary hooks into Twitter’s API, allowing me to listen for mentions, respond to tweets, and manage streams.
|
||||
4. **Simple-Dockerode**: This library offers a simplified interface for managing Docker containers directly from Node.js.
|
||||
5. **Generate-password**: I needed this to dynamically create user passwords for each container, ensuring secure access.
|
||||
|
||||
### Setting up Twitter's API Access
|
||||
To begin with, I needed access to Twitter’s API. Twitter’s API has been around for years and allows developers to interact with almost every aspect of Twitter — from fetching user data to posting tweets. For my project, I needed the bot to:
|
||||
|
||||
- **Listen for mentions**: Whenever someone tweets @mybotname, it should trigger a response.
|
||||
- **Respond with command outputs**: If the mention contains a command like `neofetch`, the bot needs to execute that command in a user’s container and tweet back the result.
|
||||
- **Manage Docker containers**: Each user’s interaction with the bot creates or destroys their own Linux container.
|
||||
|
||||
I set up the basic configuration in Node.js using Twit and Twitter’s SDK.
|
||||
|
||||
```javascript
|
||||
const config = {
|
||||
consumer_key: process.env.TWITTER_API_KEY,
|
||||
consumer_secret: process.env.TWITTER_API_SECRET_KEY,
|
||||
access_token: process.env.TWITTER_ACCESS_TOKEN,
|
||||
access_token_secret: process.env.TWITTER_ACCESS_TOKEN_SECRET,
|
||||
};
|
||||
const T = new Twit(config);
|
||||
|
||||
const client = new Client(process.env.TWITTER_BEARER_TOKEN);
|
||||
```
|
||||
|
||||
This snippet initializes Twit and the Twitter SDK with my credentials, which are securely stored in environment variables.
|
||||
|
||||
### Docker Containers: Isolated Linux Hosts for Every User
|
||||
The next big piece of the puzzle was Docker. Docker allows for easy creation and management of Linux containers, making it a perfect fit for this project. Each user interaction would generate an isolated Linux container for them, in which they could run commands.
|
||||
|
||||
Here’s how the code works to generate and start a container:
|
||||
|
||||
```javascript
|
||||
const Dockerode = require('simple-dockerode');
|
||||
const docker = new Dockerode({ socketPath: '/var/run/docker.sock' });
|
||||
|
||||
function createContainer(userID) {
|
||||
docker.createContainer({
|
||||
Image: 'ubuntu',
|
||||
Cmd: ['/bin/bash'],
|
||||
name: `container_${userID}`
|
||||
}).then(container => {
|
||||
container.start();
|
||||
console.log(`Container for user ${userID} started.`);
|
||||
});
|
||||
}
|
||||
```
|
||||
|
||||
In this code:
|
||||
- A new Docker container running Ubuntu is created for each user.
|
||||
- The container is named after the user’s Twitter ID to keep things organized.
|
||||
- The container is started immediately after creation.
|
||||
|
||||
To avoid clutter and wasted resources, the containers are ephemeral — they’re automatically destroyed after seven days. This ensures that resources aren’t wasted on inactive containers.
|
||||
|
||||
|
||||
|
||||
## Phase 2: The Twitter Bot in Action
|
||||
|
||||
### Listening for Mentions and Running Commands
|
||||
With the infrastructure in place, I had to set up the Twitter bot to continuously monitor tweets for mentions of the bot. The logic here is straightforward:
|
||||
|
||||
1. **Monitor Twitter for mentions** of the bot using a streaming API.
|
||||
2. **Identify valid commands** like `generate`, `neofetch`, `destroy`, etc.
|
||||
3. **Execute the command** in the appropriate Docker container.
|
||||
4. **Tweet the result back** to the user.
|
||||
|
||||
Here’s the code that makes this happen:
|
||||
|
||||
```javascript
|
||||
async function getMentionedTweet() {
|
||||
const stream = await client.tweets.searchStream({
|
||||
"tweet.fields": ["author_id", "id"],
|
||||
"expansions": ["referenced_tweets.id.author_id"]
|
||||
});
|
||||
|
||||
for await (const response of stream) {
|
||||
if (response.data.text.includes(`@${process.env.BOT_USERNAME}`)) {
|
||||
handleCommand(response.data.text, response.data.author_id);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
async function handleCommand(tweet, userID) {
|
||||
if (tweet.includes('generate')) {
|
||||
createContainer(userID);
|
||||
} else if (tweet.includes('destroy')) {
|
||||
destroyContainer(userID);
|
||||
} else {
|
||||
executeCommandInContainer(userID, tweet);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
This code does the following:
|
||||
- **Listens for tweets** that mention the bot.
|
||||
- **Parses the tweet** to determine whether the user wants to generate a new container, destroy an existing one, or run a command.
|
||||
- **Delegates the appropriate action**: generating, destroying, or executing a command inside a Docker container.
|
||||
|
||||
### Command Execution: Let’s Get Interactive
|
||||
For me, the real fun began when I allowed users to run Linux commands inside their containers directly from Twitter. To make this happen, I had to set up the bot to execute commands like `neofetch`, `pwd`, and more.
|
||||
|
||||
Here’s how the bot executes commands inside the container:
|
||||
|
||||
```javascript
|
||||
function executeCommandInContainer(userID, command) {
|
||||
const container = docker.getContainer(`container_${userID}`);
|
||||
|
||||
container.exec({
|
||||
Cmd: ['/bin/bash', '-c', command],
|
||||
AttachStdout: true,
|
||||
AttachStderr: true
|
||||
}, (err, exec) => {
|
||||
if (err) {
|
||||
console.log(err);
|
||||
return;
|
||||
}
|
||||
|
||||
exec.start({ Detach: false }, (err, stream) => {
|
||||
if (err) {
|
||||
console.log(err);
|
||||
return;
|
||||
}
|
||||
|
||||
stream.on('data', (data) => {
|
||||
const output = data.toString();
|
||||
tweetBack(userID, output);
|
||||
});
|
||||
});
|
||||
});
|
||||
}
|
||||
```
|
||||
|
||||
In this code:
|
||||
- We grab the appropriate Docker container for the user using their Twitter ID.
|
||||
- We then execute their command inside the container.
|
||||
- Once the command is executed, the output is captured and sent back to the user in a tweet.
|
||||
|
||||
### Dynamic Password Generation for User Security
|
||||
One of the trickier aspects of this project was ensuring that each user’s container was secure. For this, I dynamically generated passwords for each container using the `generate-password` library:
|
||||
|
||||
```javascript
|
||||
const password = generator.generate({
|
||||
length: 10,
|
||||
numbers: true
|
||||
});
|
||||
|
||||
container.exec({
|
||||
Cmd: ['/bin/bash', '-c', `echo 'root:${password}' | chpasswd`]
|
||||
});
|
||||
```
|
||||
|
||||
By dynamically generating passwords for each container and assigning them only to the user who created it, I ensured that each container had a unique, secure password. This way, only the container's owner could execute commands or access its shell.
|
||||
|
||||
|
||||
|
||||
## Phase 3: Challenges and Solutions
|
||||
|
||||
### 1. Twitter Rate Limits
|
||||
One of the most significant challenges was Twitter’s rate limiting. Twitter’s API has strict limits on how many requests can be made in a specific timeframe. This meant I had to be strategic about how often the bot responded to users. Too many commands, and I’d hit the rate limit, rendering the bot temporarily unusable.
|
||||
|
||||
**Solution**: I implemented a throttling mechanism to ensure the bot could only respond to a certain number of users per minute. This keeps the bot running smoothly and prevents any downtime due to rate limiting.
|
||||
|
||||
### 2. Resource Management
|
||||
Another challenge was ensuring that Docker containers were efficiently managed. If too many users created containers without proper monitoring, server resources could quickly be exhausted.
|
||||
|
||||
**Solution**: I implemented a garbage collection system to automatically destroy containers after seven days. This prevents resource leaks and keeps the system running efficiently.
|
||||
|
||||
```javascript
|
||||
function destroyOldContainers() {
|
||||
|
||||
|
||||
docker.listContainers((err, containers) => {
|
||||
containers.forEach(container => {
|
||||
if (isOlderThanSevenDays(container)) {
|
||||
docker.getContainer(container.Id).stop();
|
||||
docker.getContainer(container.Id).remove();
|
||||
}
|
||||
});
|
||||
});
|
||||
}
|
||||
```
|
||||
|
||||
This simple function checks all active containers, determines their age, and destroys any that are older than seven days.
|
||||
|
||||
### 3. Running Complex Commands
|
||||
Some users wanted to run more complex commands, which generated large outputs that Twitter couldn’t handle (due to character limits). For example, commands like `neofetch` could generate lengthy outputs that couldn’t be tweeted back directly.
|
||||
|
||||
**Solution**: For large outputs, I utilized an external paste service. If the command output was too large for a tweet, the bot would generate a paste and tweet the link back to the user.
|
||||
|
||||
```javascript
|
||||
if (output.length > 280) {
|
||||
const pasteURL = await createPaste(output);
|
||||
tweetBack(userID, `Output too long! Check it here: ${pasteURL}`);
|
||||
} else {
|
||||
tweetBack(userID, output);
|
||||
}
|
||||
```
|
||||
|
||||
This way, users could still run complex commands and access their output, even if Twitter’s character limits were restrictive.
|
||||
|
||||
|
||||
|
||||
## Phase 4: Going Live and User Reactions
|
||||
|
||||
Finally, after weeks of coding, testing, and refining, the bot was ready to go live. I made the bot publicly accessible and tweeted out a simple message explaining how to interact with it. Within hours, users were tweeting `generate` to create containers, running `neofetch` to see their system stats, and even running complex commands like `apt update`.
|
||||
|
||||
The response was overwhelming. People loved the idea of managing a Linux server using only Twitter. The bot provided a fun, interactive way to introduce users to Linux without needing them to understand terminal commands or SSH keys.
|
||||
|
||||
## At the end of the day...
|
||||
|
||||
Becoming the first Linux host on Twitter was an incredible journey, blending the power of Docker, the simplicity of Twitter’s API, and a dose of creative coding. What started as a wild idea quickly evolved into a fully-fledged project that allowed people to manage Linux containers through social media. The integration of social media and DevOps opened up fascinating possibilities, and I believe this was just the beginning of what could be done in this space.
|
||||
|
||||
However, since Elon Musk’s acquisition of Twitter and its transformation into X, the platform's API has become significantly more expensive, making it no longer feasible to continue this project in its original form. The increased cost of access to the API means that projects like this, which rely heavily on interaction through the platform, are now difficult to sustain without a large budget.
|
||||
|
||||
Despite this setback, I’m excited to have developed this system in the first place. It was an innovative experiment that pushed the boundaries of what can be done with social media and cloud infrastructure. The project taught me a lot about integrating two very different worlds—social media and Linux hosting—and there’s no doubt that the lessons I learned here will fuel future innovations.
|
||||
|
||||
Even though it’s no longer feasible on X, this experiment will remain a unique milestone in my journey through technology. Who knows what’s next? Maybe the future holds even more exciting possibilities for blending technology with unconventional platforms.
|
||||
|
||||
And that’s the story of how I became the first Linux host on Twitter!
|
||||
@ -0,0 +1,280 @@
|
||||
<!-- lead -->
|
||||
Streamlining Node.js Tunnels: Isolation, port management, and resource efficiency for peak performance!
|
||||
|
||||
In this post, I dive deeply into recent optimizations made to a Node.js clustered application managing tunneled requests with isolated connections. I explore the issues with the initial setup, outline each enhancement in detail, and contrast the old and new methods. These changes aim to improve tunnel isolation, streamline resource management, and prevent critical errors that could disrupt the application’s operation.
|
||||
|
||||
# Source
|
||||
## https://git.ssh.surf/hypermc/hyperMC-Web-Relay
|
||||
|
||||
# Git Commit
|
||||
## https://s.nodejs.lol/ff51iaPLY
|
||||
|
||||
|
||||
## Initial Setup and Issues
|
||||
|
||||
Our application originally served HTTP requests over a peer-to-peer network using **clustered Node.js workers**. Each incoming request established a **tunnel** to relay data through the `hyperdht` protocol using public keys derived from subdomain headers. The tunnels enabled communication to unique remote peers, allowing each HTTP request to reach its intended destination.
|
||||
|
||||
### Key Components in the Original Code
|
||||
|
||||
1. **Clustered Node.js Workers**: Using `cluster`, the application spawns multiple workers, leveraging all CPU cores for better concurrency and faster request handling.
|
||||
2. **HyperDHT Tunnels**: For each request, the application creates a tunnel to relay data between the client and the destination using the `hyperdht` protocol.
|
||||
3. **Port Management for Tunnels**: To assign ports for tunnel servers, I used randomly generated port numbers within a specified range.
|
||||
|
||||
### The Problem
|
||||
|
||||
As the application scaled, several issues began to emerge:
|
||||
|
||||
1. **Tunnel Confusion Across Requests**:
|
||||
- Since tunnels weren’t strictly isolated to individual requests, responses sometimes bled into unrelated requests, causing data mix-ups.
|
||||
- Persistent tunnels without proper cleanup led to stale or unintended connections, increasing the risk of incorrect data delivery.
|
||||
|
||||
2. **Port Conflicts**:
|
||||
- The application frequently encountered `EADDRINUSE` errors, meaning some generated ports were already in use by other tunnels.
|
||||
- Port conflicts led to worker crashes, causing downtime and reduced concurrency.
|
||||
|
||||
3. **Inefficient Resource Management**:
|
||||
- Tunnels remained open even after requests completed, resulting in unnecessary resource consumption.
|
||||
- Workers were busy managing unused connections instead of handling new requests, leading to performance bottlenecks.
|
||||
|
||||
Given these challenges, I set out to improve tunnel isolation, ensure reliable port availability, and enhance resource efficiency.
|
||||
|
||||
|
||||
|
||||
## New Approach: Enhanced Isolation, Dynamic Port Allocation, and Resource Management
|
||||
|
||||
To tackle these issues, I implemented several key improvements:
|
||||
|
||||
### 1. Strict Tunnel Isolation Per Request
|
||||
|
||||
Previously, tunnels were reused across requests, leading to data mix-ups and unintended connections. In the new approach:
|
||||
|
||||
- **Unique Tunnel Instances**: Each HTTP request now creates a dedicated `tunnelServer` instance, serving only that specific request. This ensures strict one-to-one mapping between the request and the tunnel, eliminating any chance of cross-request interference.
|
||||
- **No Shared Tunnel State**: By eliminating shared tunnel tracking objects, each request operates with complete isolation, reducing complexity and risk of data leakage.
|
||||
|
||||
**Code Difference**:
|
||||
|
||||
**Old Method**:
|
||||
```javascript
|
||||
if (!tunnels[publicKey]) {
|
||||
tunnels[publicKey] = port; // Assign port to a tunnel that may get reused
|
||||
}
|
||||
```
|
||||
|
||||
**New Method**:
|
||||
```javascript
|
||||
const tunnelServer = net.createServer((servsock) => {
|
||||
// Dedicated tunnel for each request
|
||||
});
|
||||
```
|
||||
|
||||
With this change, each tunnel becomes ephemeral, existing solely to complete a single request before it’s removed, reducing unintended interactions between requests.
|
||||
|
||||
### 2. Robust Port Availability Check with `getAvailablePort`
|
||||
|
||||
In the initial implementation, the application generated random ports without checking their availability, leading to frequent `EADDRINUSE` errors. To address this:
|
||||
|
||||
- **Port Checking with `net.createServer`**: I enhanced `getAvailablePort` by creating a temporary server to verify port availability. If the port is free, the function closes the test server and assigns that port to the new tunnel. If the port is already in use, it retries until it finds a free port.
|
||||
- **Automatic Retry Mechanism**: This approach ensures no `EADDRINUSE` errors by dynamically testing ports until an available one is found.
|
||||
|
||||
**Code Difference**:
|
||||
|
||||
**Old Method**:
|
||||
```javascript
|
||||
const port = 1337 + Math.floor(Math.random() * 1000); // No check for availability
|
||||
```
|
||||
|
||||
**New Method**:
|
||||
```javascript
|
||||
async function getAvailablePort() {
|
||||
return new Promise((resolve, reject) => {
|
||||
const tryPort = () => {
|
||||
const port = 1337 + Math.floor(Math.random() * 1000);
|
||||
const tester = net.createServer()
|
||||
.once('error', (err) => {
|
||||
if (err.code === 'EADDRINUSE') {
|
||||
tryPort(); // Retry if port is in use
|
||||
} else {
|
||||
reject(err);
|
||||
}
|
||||
})
|
||||
.once('listening', () => {
|
||||
tester.close(() => resolve(port)); // Port is available
|
||||
})
|
||||
.listen(port, '127.0.0.1');
|
||||
};
|
||||
tryPort();
|
||||
});
|
||||
}
|
||||
```
|
||||
|
||||
This method guarantees that ports are only assigned if they are actually available, ensuring reliable tunnel creation and eliminating port-related crashes.
|
||||
|
||||
### 3. Automatic Tunnel Closure for Efficient Resource Management
|
||||
|
||||
Previously, tunnels remained open even after completing requests, wasting system resources and risking data leaks. Now, each tunnel is closed as soon as the associated response finishes.
|
||||
|
||||
- **Tunnel Lifecycle Bound to Request Lifecycle**: Using the `res.on('finish')` event, the tunnel server closes immediately after the response is sent, freeing resources for other requests.
|
||||
- **Reduced Memory and CPU Overhead**: By closing tunnels promptly, workers are freed to handle new requests, reducing CPU and memory consumption.
|
||||
|
||||
**Code Difference**:
|
||||
|
||||
**Old Method**:
|
||||
```javascript
|
||||
// Tunnels were left open, requiring manual cleanup and causing resource issues
|
||||
```
|
||||
|
||||
**New Method**:
|
||||
```javascript
|
||||
res.on('finish', () => {
|
||||
tunnelServer.close(() => {
|
||||
if (DEBUG === 1 || CONINFO === 1) console.log("Tunnel closed after request completion.");
|
||||
});
|
||||
});
|
||||
```
|
||||
|
||||
With this approach, the system efficiently reclaims resources after each request, making the application more scalable and responsive under load.
|
||||
|
||||
|
||||
|
||||
## Detailed Code Walkthrough
|
||||
|
||||
Here’s the fully optimized code with all the changes:
|
||||
|
||||
```javascript
|
||||
const cluster = require('cluster');
|
||||
const numCPUs = require('os').cpus().length;
|
||||
const net = require('net');
|
||||
|
||||
if (cluster.isMaster) {
|
||||
console.log(`Master ${process.pid} is running`);
|
||||
console.log(`Total Workers ${numCPUs * 6}`);
|
||||
for (let i = 0; i < numCPUs * 4; i++) {
|
||||
cluster.fork();
|
||||
}
|
||||
|
||||
cluster.on('exit', (worker, code, signal) => {
|
||||
console.log(`Worker ${worker.process.pid} died`);
|
||||
});
|
||||
} else {
|
||||
const fs = require('fs');
|
||||
const http = require('http');
|
||||
const httpProxy = require('http-proxy');
|
||||
const HyperDHTServer = require('hyperdht');
|
||||
const b32 = require("hi-base32");
|
||||
const agent = new http.Agent({ maxSockets: Number.MAX_VALUE });
|
||||
const content = fs.readFileSync('404.txt', 'utf8');
|
||||
const DEBUG = 0;
|
||||
const CONINFO = 0;
|
||||
const dhtServer = new HyperDHTServer();
|
||||
|
||||
const startServer = async () => {
|
||||
console.log(`Worker ${process.pid} started`);
|
||||
await dhtServer.ready();
|
||||
|
||||
const proxy = httpProxy.createProxyServer({
|
||||
ws: true,
|
||||
agent: agent,
|
||||
timeout: 360000
|
||||
});
|
||||
|
||||
const server = http.createServer(async function (req, res) {
|
||||
try {
|
||||
const split = req.headers.host.split('.');
|
||||
const publicKey = Buffer.from(b32.decode.asBytes(split[0].toUpperCase()));
|
||||
|
||||
if (publicKey.length < 32) {
|
||||
console.log("Invalid Connection!");
|
||||
res.writeHead(418, { 'Content-Type': 'text/html' });
|
||||
res.end(content);
|
||||
return;
|
||||
}
|
||||
|
||||
const port = await getAvailablePort();
|
||||
const tunnelServer = net.createServer(function (servsock) {
|
||||
const socket = dhtServer.connect(publicKey);
|
||||
let open = { local: true, remote: true };
|
||||
|
||||
servsock.on('data', (d) => socket.write(d));
|
||||
socket.on('data', (d) => servsock.write(d));
|
||||
|
||||
const remoteend = () => {
|
||||
if (open.remote) socket.end();
|
||||
open.remote = false;
|
||||
};
|
||||
const localend = () => {
|
||||
if (open.local) servsock.end();
|
||||
open.local = false;
|
||||
};
|
||||
|
||||
servsock.on('error', remoteend);
|
||||
servsock.on('finish', remoteend);
|
||||
servsock.on('end', remoteend);
|
||||
socket.on('finish', localend);
|
||||
socket.on('error', localend);
|
||||
socket.on('end', localend);
|
||||
});
|
||||
|
||||
tunnelServer.listen(port, "127.0.0.1", () => {
|
||||
if (DEBUG === 1 || CONINFO === 1) console.log(`Tunnel server listening on port ${port}`);
|
||||
|
||||
proxy.web(req, res, {
|
||||
target: 'http://127.0.0.1:' + port
|
||||
}, function (e) {
|
||||
console.log("Proxy Web Error: ", e);
|
||||
res.writeHead(404, { 'Content-Type': 'text/html' });
|
||||
res.end(content);
|
||||
});
|
||||
|
||||
res.on('finish', () => {
|
||||
tunnelServer.close(() => {
|
||||
if (DEBUG === 1 || CONINFO === 1) console.log("Tunnel closed after request completion.");
|
||||
});
|
||||
});
|
||||
});
|
||||
} catch (e) {
|
||||
console.error("Error Occurred: ", e);
|
||||
}
|
||||
|
||||
|
||||
});
|
||||
|
||||
server.listen(8081, () => {
|
||||
console.log(`Worker ${process.pid} listening on port 8081`);
|
||||
});
|
||||
};
|
||||
|
||||
startServer().catch(console.error);
|
||||
|
||||
async function getAvailablePort() {
|
||||
return new Promise((resolve, reject) => {
|
||||
const tryPort = () => {
|
||||
const port = 1337 + Math.floor(Math.random() * 1000);
|
||||
const tester = net.createServer()
|
||||
.once('error', (err) => {
|
||||
if (err.code === 'EADDRINUSE') {
|
||||
tryPort();
|
||||
} else {
|
||||
reject(err);
|
||||
}
|
||||
})
|
||||
.once('listening', () => {
|
||||
tester.close(() => resolve(port));
|
||||
})
|
||||
.listen(port, '127.0.0.1');
|
||||
};
|
||||
tryPort();
|
||||
});
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
## Final Thoughts
|
||||
|
||||
The new design introduces strict isolation for tunnels, efficient port management, and automatic resource cleanup. By implementing these changes, I:
|
||||
- Solved the `EADDRINUSE` errors by dynamically checking port availability.
|
||||
- Isolated tunnels to prevent cross-request data confusion.
|
||||
- Enhanced performance and scalability by closing tunnels immediately after requests finish.
|
||||
|
||||
These updates not only improve reliability but also ensure that the application scales effectively, even under heavy load. This level of optimization is essential for any high-traffic Node.js service, as it directly impacts the user experience, system stability, and overall application performance.
|
||||
409
markdown/Implementing RayAI into This Blog.md
Normal file
@ -0,0 +1,409 @@
|
||||
<!-- lead -->
|
||||
How I built RayAI into this Very Blog.
|
||||
|
||||
In my previous post, <u>[Building a Feature-Rich Blog Platform with Node.js, Express, and Markdown](https://blog.raven-scott.fyi/building-a-feature-rich-blog-platform-with-nodejs-express-and-markdown)</u>, I walked through the technical architecture of a blog platform designed for flexibility, performance, and ease of content management. Today, I’m introducing a new feature: **RayAI** — an interactive AI chat system integrated directly into the blog.
|
||||
|
||||
RayAI allows visitors to ask questions, get real-time responses, and even interact with the blog content on a deeper level. Think of it as an intelligent assistant embedded within the blog, ready to help users understand, explore, and engage with the content. This is not just a simple Q&A bot; RayAI can handle markdown, provide code snippets, and even let users copy content for their own use.
|
||||
|
||||
In this post, I’ll take you through every step of integrating RayAI into the blog, from the front-end interface to the back-end API handling. Let's dive into the details of this integration and see how it all comes together.
|
||||
|
||||
# Source
|
||||
|
||||
## https://git.ssh.surf/snxraven/ravenscott-blog
|
||||
|
||||
## Why Implement RayAI?
|
||||
|
||||
The primary motivation behind RayAI is to enhance user engagement. Static blog posts are great, but they often leave the user with questions or areas where they might want further explanation. RayAI bridges that gap by offering:
|
||||
|
||||
1. **Real-time Chat**: Users can interact directly with the AI to get instant responses to questions.
|
||||
2. **Markdown Support**: RayAI interprets markdown, making it perfect for developers who might want to see code snippets or explanations in a well-formatted way.
|
||||
3. **Code Snippet Copying**: Users can easily copy code from AI responses, reducing the time they would spend manually copying and pasting.
|
||||
4. **Interactive Tools**: RayAI includes utilities for checking logs, system stats, and even fetching specific data directly within the chat interface.
|
||||
|
||||
With these features in mind, let's explore how RayAI was integrated into the blog platform.
|
||||
|
||||
## The Front-End: Creating the Chat Interface
|
||||
|
||||
The **front-end** implementation of RayAI begins with the **`chat.ejs`** file, which defines the structure of the chat interface. This file includes the layout, user input area, and the section for displaying chat messages. It also leverages **Bootstrap** for styling and **FontAwesome** for icons, keeping the UI clean and responsive.
|
||||
|
||||
### Setting Up the HTML Structure
|
||||
|
||||
Here's the code for `chat.ejs`:
|
||||
|
||||
```html
|
||||
<!DOCTYPE html>
|
||||
<html lang="en">
|
||||
<head>
|
||||
<meta charset="UTF-8">
|
||||
<meta name="viewport" content="width=device-width, initial-scale=1.0">
|
||||
<meta name="description" content="<%= process.env.OWNER_NAME %>'s Blog">
|
||||
<title><%= title %> | <%= process.env.OWNER_NAME %>'s Blog</title>
|
||||
|
||||
<!-- Bootstrap and Custom Styles -->
|
||||
<link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/bootstrap@5.3.0-alpha1/dist/css/bootstrap.min.css">
|
||||
<link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/font-awesome/6.0.0-beta3/css/all.min.css">
|
||||
<link rel="stylesheet" href="<%= process.env.HOST_URL %>/css/chat.css">
|
||||
</head>
|
||||
|
||||
<body class="bg-dark text-white">
|
||||
<!-- Chat Container -->
|
||||
<div class="chat-container">
|
||||
<!-- Navbar -->
|
||||
<nav class="navbar navbar-expand-lg navbar-dark">
|
||||
<div class="container-fluid">
|
||||
<a class="navbar-brand" href="<%= process.env.HOST_URL %>"><%= process.env.SITE_NAME %></a>
|
||||
<button class="navbar-toggler" type="button" data-bs-toggle="collapse" data-bs-target="#navbarNav" aria-controls="navbarNav" aria-expanded="false" aria-label="Toggle navigation">
|
||||
<span class="navbar-toggler-icon"></span>
|
||||
</button>
|
||||
<div class="collapse navbar-collapse" id="navbarNav">
|
||||
<ul class="navbar-nav ms-auto">
|
||||
<% menuItems.forEach(item => { %>
|
||||
<li class="nav-item">
|
||||
<a class="nav-link" href="<%= item.url %>" <%= item.openNewPage ? 'target="_blank"' : '' %>><%= item.title %></a>
|
||||
</li>
|
||||
<% }) %>
|
||||
</ul>
|
||||
</div>
|
||||
</div>
|
||||
</nav>
|
||||
|
||||
<!-- Chat Box -->
|
||||
<div class="chat-box">
|
||||
<div id="messages" class="messages"></div>
|
||||
|
||||
<!-- Input area -->
|
||||
<div class="input-area">
|
||||
<textarea id="messageInput" class="form-control mb-2" rows="3" placeholder="Type your message..." onkeydown="handleKeyDown(event)" autofocus></textarea>
|
||||
|
||||
<div class="d-flex justify-content-between">
|
||||
<button class="btn btn-secondary" onclick="resetChat()">Reset Chat</button>
|
||||
<div id="loading" class="spinner-border text-primary" role="status" style="display: none;">
|
||||
<span class="visually-hidden">Loading...</span>
|
||||
</div>
|
||||
<button class="btn btn-primary" onclick="sendMessage()">Send Message</button>
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
|
||||
<!-- Bootstrap JS -->
|
||||
<script src="https://cdn.jsdelivr.net/npm/bootstrap@5.3.0-alpha1/dist/js/bootstrap.bundle.min.js"></script>
|
||||
<!-- Custom Chat JS -->
|
||||
<script src="<%= process.env.HOST_URL %>/js/chat.js"></script>
|
||||
</body>
|
||||
</html>
|
||||
```
|
||||
|
||||
### Key Sections in the HTML
|
||||
|
||||
- **Navbar**: Displays the blog title and navigation items dynamically loaded from the `menuItems` array.
|
||||
- **Chat Box**: This is where the chat messages between the user and RayAI are displayed. Each message is dynamically added via JavaScript.
|
||||
- **Input Area**: Includes a textarea for input and two buttons—one for sending the message, and the other for resetting the chat.
|
||||
|
||||
#### Styling with Bootstrap and FontAwesome
|
||||
|
||||
The **Bootstrap CSS framework** is used to ensure the page is responsive and user-friendly. I also included **FontAwesome** for icons, like the send button and the loading spinner, ensuring the interface looks polished.
|
||||
|
||||
|
||||
|
||||
## Handling User Input and Chat Logic: `chat.js`
|
||||
|
||||
Now that the front-end structure is in place, let’s look at the **JavaScript** that powers the chat functionality. This file, **`chat.js`**, is responsible for:
|
||||
|
||||
- Handling key events (like sending messages when the user presses Enter)
|
||||
- Interacting with the AI via API calls
|
||||
- Displaying messages in the chat window
|
||||
- Managing the loading indicator while waiting for responses
|
||||
|
||||
### Handling Key Events and Sending Messages
|
||||
|
||||
The **key event handler** ensures that when the user presses "Enter", the message is sent without needing to click the "Send" button.
|
||||
|
||||
```javascript
|
||||
// Handles key down event to send message on Enter
|
||||
function handleKeyDown(event) {
|
||||
if (event.key === 'Enter' && !event.shiftKey) {
|
||||
event.preventDefault();
|
||||
sendMessage();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
This function ensures that users can submit messages quickly by hitting Enter, making the chat experience smooth.
|
||||
|
||||
### Sending Messages to the API
|
||||
|
||||
The **`sendMessage`** function is the core of RayAI's interaction. It takes the user input, sends it to the AI backend, and displays the AI's response.
|
||||
|
||||
```javascript
|
||||
// Sends a message to the chat API
|
||||
async function sendMessage() {
|
||||
const messageInput = document.getElementById('messageInput');
|
||||
let message = messageInput.value.trim();
|
||||
|
||||
if (message === '') return;
|
||||
|
||||
// Encode the message to avoid XSS attacks
|
||||
message = he.encode(message);
|
||||
|
||||
// Display the user's message in the chat
|
||||
displayMessage(message, 'user');
|
||||
messageInput.value = ''; // Clear the input
|
||||
toggleLoading(true); // Show loading indicator
|
||||
|
||||
try {
|
||||
const response = await fetch('https://infer.x64.world/chat', {
|
||||
method: 'POST',
|
||||
headers: {
|
||||
'Content-Type': 'application/json'
|
||||
},
|
||||
body: JSON.stringify({ message: message })
|
||||
});
|
||||
|
||||
if (response.ok) {
|
||||
const data = await response.json();
|
||||
displayMessage(data.content, 'assistant');
|
||||
} else {
|
||||
handleErrorResponse(response.status);
|
||||
}
|
||||
} catch (error) {
|
||||
displayMessage('Error: ' + error.message, 'assistant');
|
||||
} finally {
|
||||
toggleLoading(false); // Hide loading indicator
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
- **API Interaction**: This function sends the user’s message to the API endpoint `https://infer.x64.world/chat`, which handles the AI interaction.
|
||||
- **XSS Protection**: The message is encoded using `he.encode()` to prevent cross-site scripting attacks.
|
||||
- **Message Display**: After the message is sent, it’s displayed in the chat window and the loading spinner is shown while waiting for the response.
|
||||
|
||||
### Displaying Chat Messages
|
||||
|
||||
Once the API responds, the message is displayed in the chat box using the **`displayMessage`** function. This function takes care of rendering both user and AI messages in the chat window.
|
||||
|
||||
```javascript
|
||||
// Displays a message in the chat window
|
||||
function displayMessage(content, sender) {
|
||||
const messages = document.getElementById('messages');
|
||||
const messageElement = document.createElement('div');
|
||||
messageElement.classList.add('message', sender);
|
||||
|
||||
// Decode HTML entities and
|
||||
|
||||
render Markdown
|
||||
const decodedContent = he.decode(content);
|
||||
const htmlContent = marked(decodedContent);
|
||||
messageElement.innerHTML = htmlContent;
|
||||
|
||||
messages.appendChild(messageElement);
|
||||
messages.scrollTop = messages.scrollHeight; // Scroll to the bottom of the chat
|
||||
|
||||
// Highlight code blocks if any
|
||||
document.querySelectorAll('pre code').forEach((block) => {
|
||||
hljs.highlightElement(block);
|
||||
if (sender === 'assistant') {
|
||||
addCopyButton(block); // Add copy button to code blocks
|
||||
}
|
||||
});
|
||||
|
||||
// Add "Copy Full Response" button after each assistant response
|
||||
if (sender === 'assistant') {
|
||||
addCopyFullResponseButton(messages, messageElement);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Key features of this function:
|
||||
- **Markdown Support**: RayAI’s responses are parsed as Markdown using **`marked`**, allowing code snippets and formatted text to display beautifully.
|
||||
- **Scroll Management**: Automatically scrolls the chat window to the bottom when a new message is added.
|
||||
- **Code Highlighting**: If the AI responds with a code snippet, it’s highlighted using **highlight.js**, improving readability for developers.
|
||||
- **Copy Functionality**: Adds a "Copy" button to code blocks, allowing users to copy snippets with a single click.
|
||||
|
||||
### Adding Utility Buttons
|
||||
|
||||
RayAI goes beyond just chat by offering interactive tools directly within the chat interface. Here's how we implement the "Copy Full Response" and "Copy Code" buttons.
|
||||
|
||||
```javascript
|
||||
// Adds "Copy Full Response" button below the assistant response
|
||||
function addCopyFullResponseButton(messagesContainer, messageElement) {
|
||||
const copyFullResponseButton = document.createElement('button');
|
||||
copyFullResponseButton.classList.add('copy-button');
|
||||
copyFullResponseButton.textContent = 'Copy Full Response';
|
||||
copyFullResponseButton.addEventListener('click', () => copyFullResponse(messageElement));
|
||||
|
||||
messagesContainer.appendChild(copyFullResponseButton);
|
||||
}
|
||||
```
|
||||
|
||||
This button copies the entire AI response, including any markdown or code blocks, into the user’s clipboard in Markdown format.
|
||||
|
||||
|
||||
|
||||
Certainly! Here's an extended and more detailed version of the section on **The Backend: RayAI API Integration**.
|
||||
|
||||
|
||||
|
||||
## The Backend: RayAI API Integration
|
||||
|
||||
The backbone of RayAI’s functionality lies in how it communicates with an external AI service, processes the user's inputs, and returns intelligent, contextual responses. In this section, I will break down how RayAI handles requests, the architecture behind it, and the measures taken to ensure smooth interaction between the blog platform and the AI API.
|
||||
|
||||
### API Overview and How It Works
|
||||
|
||||
At its core, the AI powering RayAI is hosted at an external endpoint, `https://infer.x64.world/chat`. This API accepts POST requests with user input and returns a generated response. To integrate this with the blog platform, the JavaScript on the front-end captures the user's message, sends it to the API, and processes the AI's response for display within the chat interface.
|
||||
|
||||
The **key objectives** of this integration are:
|
||||
1. Seamlessly send user input to the AI API.
|
||||
2. Receive and display the response from the API in real time.
|
||||
3. Handle network issues or server overloads gracefully.
|
||||
4. Secure communication to prevent potential vulnerabilities, such as cross-site scripting (XSS) or API abuse.
|
||||
|
||||
### Sending Requests to the AI API
|
||||
|
||||
The main logic for sending user messages to the API is contained in the **`sendMessage`** function. Let’s go deeper into the code to explain how the back-and-forth communication is handled.
|
||||
|
||||
Here’s the function once again:
|
||||
|
||||
```javascript
|
||||
async function sendMessage() {
|
||||
const messageInput = document.getElementById('messageInput');
|
||||
let message = messageInput.value.trim();
|
||||
|
||||
if (message === '') return;
|
||||
|
||||
// Encode the message to avoid XSS attacks
|
||||
message = he.encode(message);
|
||||
|
||||
// Display the user's message in the chat
|
||||
displayMessage(message, 'user');
|
||||
messageInput.value = ''; // Clear the input
|
||||
toggleLoading(true); // Show loading indicator
|
||||
|
||||
try {
|
||||
// Send the user's message to the AI API
|
||||
const response = await fetch('https://infer.x64.world/chat', {
|
||||
method: 'POST',
|
||||
headers: {
|
||||
'Content-Type': 'application/json'
|
||||
},
|
||||
body: JSON.stringify({ message: message })
|
||||
});
|
||||
|
||||
// Handle the API response
|
||||
if (response.ok) {
|
||||
const data = await response.json();
|
||||
displayMessage(data.content, 'assistant');
|
||||
} else {
|
||||
handleErrorResponse(response.status);
|
||||
}
|
||||
} catch (error) {
|
||||
displayMessage('Error: ' + error.message, 'assistant');
|
||||
} finally {
|
||||
toggleLoading(false); // Hide loading indicator
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### Breaking Down the Code
|
||||
|
||||
1. **Input Validation**:
|
||||
Before sending any request, the user’s input is first **trimmed** to remove unnecessary whitespace. If the input is empty (i.e., no text was entered), the function exits early to avoid sending unnecessary requests.
|
||||
|
||||
2. **XSS Protection**:
|
||||
User input is **encoded** using `he.encode()`. This is crucial for preventing **cross-site scripting (XSS)** attacks, where malicious users could inject harmful code into the chat. By encoding the input, we ensure that any special characters are safely transformed, so the AI API only processes clean text.
|
||||
|
||||
3. **Displaying the User’s Message**:
|
||||
Once the message is encoded, it is immediately displayed in the chat interface (before even getting a response from the AI). This gives the user a smooth, instant feedback loop and ensures that their input is visually confirmed.
|
||||
|
||||
4. **Sending the Request**:
|
||||
The **`fetch()`** function sends the message as a **POST request** to the external API (`https://infer.x64.world/chat`). Here’s what happens in the background:
|
||||
- The request contains a JSON object with the key `message` holding the user’s input.
|
||||
- Headers are set to indicate that the request body is JSON (`'Content-Type': 'application/json'`), which is what the API expects.
|
||||
|
||||
5. **Handling the Response**:
|
||||
- **Success**: If the response from the API is successful (status code 200), the response body (a JSON object) is parsed. The content generated by the AI is then passed to the `displayMessage` function to be shown as an AI response in the chat interface.
|
||||
- **Error**: If the response is not successful (e.g., status codes like 400 or 500), the `handleErrorResponse` function is called to manage error feedback to the user.
|
||||
|
||||
6. **Loading Indicator**:
|
||||
While waiting for the API to respond, a loading indicator (a spinner) is displayed, improving user experience by signaling that the system is processing their request. This indicator is hidden once the response is received.
|
||||
|
||||
### Error Handling and Rate Limiting
|
||||
|
||||
Integrating a third-party API like this comes with challenges, such as network errors, rate limits, and potential server overloads. These are handled through robust error-checking and failover mechanisms.
|
||||
|
||||
```javascript
|
||||
function handleErrorResponse(status) {
|
||||
if (status === 429) {
|
||||
displayMessage('Sorry, I am currently too busy at the moment!', 'assistant');
|
||||
} else {
|
||||
displayMessage('Error: ' + status, 'assistant');
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### Handling Rate Limiting (429 Status Code)
|
||||
|
||||
When multiple users interact with RayAI simultaneously, or when the API receives too many requests in a short span of time, it may respond with a **429 (Too Many Requests)** status. This is known as **rate limiting**, a mechanism used by APIs to prevent overloading.
|
||||
|
||||
In such cases, RayAI responds with a friendly message like:
|
||||
> "Sorry, I am currently too busy at the moment!"
|
||||
|
||||
This ensures users know the service is temporarily unavailable, rather than simply failing silently. Additionally, **retry logic** could be implemented if needed, to automatically attempt a new request after a short delay.
|
||||
|
||||
#### Handling Network and Other Errors
|
||||
|
||||
Other common errors include server issues (status code 500) or connection issues (e.g., when the user’s internet connection is unstable). These are captured within the `catch` block of the `try-catch` structure. In case of failure, an error message such as the following is displayed:
|
||||
> "Error: {error.message}"
|
||||
|
||||
This ensures that even if something goes wrong, the user receives a clear explanation of the issue.
|
||||
|
||||
### Securing the API
|
||||
|
||||
While RayAI’s front-end handles much of the logic, securing the API interaction is essential to prevent abuse, data breaches, or malicious attacks.
|
||||
|
||||
#### XSS and Input Validation
|
||||
|
||||
As mentioned earlier, we encode all user input using **`he.encode()`** before sending it to the API. This ensures that special characters (such as `<`, `>`, and `&`) are converted into their HTML-safe equivalents, protecting the application from cross-site scripting attacks.
|
||||
|
||||
#### Rate Limiting and Abuse Prevention
|
||||
|
||||
The external AI service includes built-in rate limiting (as indicated by the 429 error code), but further measures could be implemented to prevent API abuse:
|
||||
1. **IP-Based Rate Limiting**: You can restrict the number of API requests allowed from a single IP address within a given time window. This prevents users or bots from spamming the service with excessive requests.
|
||||
2. **Authentication**: Adding a layer of authentication (such as API keys or OAuth) could ensure that only authorized users have access to RayAI’s features.
|
||||
|
||||
|
||||
|
||||
### Enhancing AI Responses
|
||||
|
||||
RayAI is more than just a simple chatbot. The backend API offers several features that enhance the experience:
|
||||
|
||||
1. **Markdown Rendering**:
|
||||
RayAI’s responses often include formatted text, especially when answering technical questions. The responses are processed using **marked.js** to ensure markdown syntax is rendered correctly in the chat.
|
||||
|
||||
2. **Code Highlighting**:
|
||||
If the AI responds with a code snippet, it’s automatically highlighted using **highlight.js**, which provides syntax highlighting for over 180 programming languages. This is particularly useful for developers who interact with RayAI.
|
||||
|
||||
3. **Copy Buttons**:
|
||||
Each response that includes code also has a "Copy" button. This feature is implemented using custom JavaScript, which allows users to copy entire code blocks or full responses to their clipboard in a single click.
|
||||
|
||||
|
||||
|
||||
### Additional Tools in RayAI
|
||||
|
||||
Apart from chat functionality, RayAI also provides access to **interactive tools** through the chat interface. These include:
|
||||
- **Live Logs**: Users can view live system logs in real-time by clicking a "Live Log" button.
|
||||
- **System Stats**: Displays system metrics like CPU, memory, and GPU stats through the "GPU Stats" button.
|
||||
- **Reset Chat**: This feature allows users to clear the current chat history and reset the conversation.
|
||||
It sends a POST request to `https://infer.x64.world/reset-conversation`, clearing the session data.
|
||||
|
||||
These tools are essential for advanced users who want to monitor system performance or interact with RayAI in more technical ways.
|
||||
|
||||
## Final Thoughts: The Power of RayAI
|
||||
|
||||
By integrating RayAI, the blog has evolved from a static platform into a dynamic, interactive experience. RayAI provides real-time interactions, makes technical content more accessible, and helps users engage with blog posts on a deeper level. Features like code highlighting, markdown rendering, and interactive tools bring immense value to both developers and casual readers.
|
||||
|
||||
In the future, RayAI could be extended even further with additional features like natural language search for blog posts, personalized recommendations, or even interactive tutorials. The possibilities are endless.
|
||||
|
||||
For now, I’m thrilled with how RayAI enhances the blog, and I can’t wait to see how users engage with it.
|
||||
|
||||
If you want to try it yourself, head over to the <u>[RayAI Chat Page](https://chat.raven.scott-fyi)</U> and start a conversation!
|
||||
@ -0,0 +1,105 @@
|
||||
<!-- lead -->
|
||||
The AI Industry’s Apocalyptic Folly
|
||||
|
||||
# Intro
|
||||
The AI industry isn’t just teetering on the edge of disaster - it’s sprinting toward a cliff, blindfolded, with a lit dynamite stick in each hand. Large language models (LLMs) and their overhyped progeny, large reasoning models (LRMs), are being rammed into production environments with a recklessness that makes a drunken pilot look like a paragon of caution. This isn’t progress; it’s a death pact signed in Silicon Valley’s blood.
|
||||
|
||||
Worse, the industry’s insatiable data hunger, fueled by tools like Scrapy, is waging a silent war on the internet, pummeling servers into oblivion and strangling the digital ecosystem that holds our world together. Apple’s June 2025 paper, *The Illusion of Thinking*, obliterates the myth that these models are ready for the real world, exposing them as brittle, unreliable frauds that crumble under scrutiny. Anthropic CEO Dario Amodei’s gut-wrenching confession - “nobody knows how AI works” - is a scream into the void, admitting we’re piloting a spaceship with no clue how the controls function.
|
||||
|
||||
A post on X glorifying Scrapy’s web-scraping prowess lays bare the industry’s complicity in this digital carnage, celebrating server-killing tools as if they’re heroes. Deploying LLMs and LRMs, built on this unethical, destructive foundation, is a betrayal of humanity’s trust. This blog post is a raging indictment of the AI industry’s suicidal crusade, a desperate plea to lock this madness in research labs before we torch everything, backed by damning evidence from recent research and industry failures.
|
||||
|
||||
## A Cult of Digital Vandals
|
||||
|
||||
The AI landscape in 2025 is a dystopian fever dream, a chaotic gold rush where tech giants - OpenAI, Anthropic, Google, Meta AI, xAI - pillage the digital world to build their empires. LLMs like GPT-4, Claude 3, and Grok 3 are already infesting healthcare, finance, education, and defense, while LRMs, hyped as reasoning savants that “think” before answering, are peddled as the next messiah. Let’s rip off the rose-tinted glasses: these aren’t tools; they’re black-box bombs built on a foundation of stolen, scraped data that’s choking the internet to death.
|
||||
|
||||
The transformer architecture, a statistical trick for predicting text, has been inflated into a godlike entity, worshipped with fanatical zeal while ignoring the wreckage it leaves behind. This obsession with scale is collective madness. Models are trained on datasets so colossal - trillions of tokens scraped from the internet’s cesspool, books, and corporate sludge - that even their creators can’t untangle the mess.
|
||||
|
||||
## Apple’s *Illusion of Thinking*: A Flamethrower to AI’s Lies
|
||||
|
||||
Apple’s June 2025 paper, *The Illusion of Thinking*, is a flamethrower torching the AI industry’s lies. Authors Parshin Shojaee, Iman Mirzadeh, and their team devised ingenious puzzle environments to test LRMs’ so-called reasoning, demanding real problem-solving, not regurgitated answers. The results are a flaming middle finger to every AI evangelist.
|
||||
|
||||
LRMs breeze through simple tasks but implode spectacularly on complex ones, spewing nonsense or flat-out wrong answers. Deploy that in a hospital or courtroom, and it’s a massacre waiting to happen. Pumping more compute or tokens doesn’t fix the problem - it’s a cruel mirage. Apple found LRMs’ “reasoning effort” peaks early, then nosedives, even with resources to spare, like a rocket exploding at 10,000 feet no matter how much fuel you pump.
|
||||
|
||||
These models are erratic, nailing one puzzle only to choke on a near-identical one, guessing instead of reasoning, their outputs as reliable as a drunk gambler’s dice roll. Humiliatingly, basic LLMs often outshine LRMs on simple tasks, with the “reasoning” baggage slowing them down or causing errors. Why are we worshipping a downgrade?
|
||||
|
||||
The “thinking processes” LRMs boast are a marketing stunt, revealed by Apple as a chaotic mess of incoherent leaps, dead ends, and half-baked ideas - not thought, but algorithmic vomit. LRMs fail to use explicit algorithms, even when essential, faking it with statistical sleight-of-hand that collapses under scrutiny.
|
||||
|
||||
## Amodei’s Confession: We’re Flying Blind
|
||||
|
||||
If Apple’s paper lit the fuse, Dario Amodei’s essay is the explosion that levels the city. The Anthropic CEO, a supposed champion of AI safety, dropped a truth bomb: “Nobody really knows how AI works.” Let that sink in. The guy steering one of the world’s top labs is confessing we’re flying blind. This isn’t a minor glitch - it’s an existential failure.
|
||||
|
||||
We’re not tweaking a buggy app; we’re wielding tech that could reshape civilization, navigating it with a Magic 8-Ball. Amodei’s dream of an “MRI on AI” is a desperate cry, not a roadmap. He admits we can’t explain why a model picks one word or makes an error. This isn’t like not knowing a car’s engine - you can still drive. It’s like not knowing why a nuclear reactor keeps melting down, yet firing it up.
|
||||
|
||||
Anthropic’s red-teaming experiments, breaking models to study flaws, are a Band-Aid on a severed artery. We’re light-years from cracking the black box.
|
||||
## Web Scraping’s Reign of Terror
|
||||
|
||||
The AI industry’s data addiction is a digital plague, and web scraping is its weapon. An X post glorifying Scrapy, a Python framework with over 55,000 GitHub stars, exposes the truth: the industry is waging war on the internet [Scrapy Post, 2025](https://x.com/birgenbilge_mk/status/1930558228590428457?s=46). Scrapy’s “event-driven architecture” and “asynchronous engine” hammer servers with hundreds of simultaneous requests, ripping data at breakneck speed. Its CSS/XPath selectors and JSONL exports make it a darling for LLM pipelines.
|
||||
|
||||
But Scrapy’s non-sane defaults and aggressive concurrency are a death sentence for servers. Its defaults prioritize speed over ethics, overwhelming servers with relentless requests. Small websites, blogs, and forums - run by individuals or small businesses - crash or rack up crippling bandwidth costs. The X post brags about handling “tens of thousands of pages,” but each page is a sledgehammer to someone’s infrastructure.
|
||||
|
||||
The internet thrives on open access, but scraping is strangling it. Websites implement bot protections, paywalls, or IP bans, locking out legitimate users. The X post admits to “bot protections” and “IP bans” as challenges, but Scrapy’s workarounds escalate this arms race, turning the web into a walled garden.
|
||||
|
||||
Scrapers plunder content without consent, stealing intellectual property, leaving creators - writers, artists, publishers - with no compensation. The X post’s “clean datasets” fantasy ignores the dirty truth: this data is pilfered. A February 2025 EPIC report calls this the “great scrape,” noting that companies like OpenAI allegedly scraped New York Times articles, copyrighted books, and YouTube videos without permission, violating privacy and IP rights [EPIC, 2025](https://epic.org/scraping-for-me-not-for-thee-large-language-models-web-data-and-privacy-problematic-paradigms/).
|
||||
|
||||
Scraping collects sensitive personal information without consent, raising privacy concerns. A 2024 OECD report highlights how scraping violates privacy laws and the OECD AI Principles, risking identity fraud and cyberattacks. A May 2025 Simplilearn article notes that scraping exacerbates AI’s privacy violations, advocating for GDPR and HIPAA compliance [Simplilearn, 2025](https://www.simplilearn.com/challenges-of-artificial-intelligence-article).
|
||||
|
||||
Millions of scrapers clog networks, slowing access, while data centers strain, driving up energy costs and carbon emissions. Websites lose faith, shutting down or going offline, shrinking the internet’s diversity. Scrapy’s defenders claim it’s “essential” for LLMs, but that’s a lie. This data hunger is a choice. By glorifying server-killing tools, we’re murdering the internet’s soul. Deploying LLMs built on this stolen foundation isn’t reckless - it’s immoral.
|
||||
|
||||
## Technical Abyss: A House of Horrors
|
||||
|
||||
The rot goes beyond bad data. LLMs and LRMs are built on the transformer architecture, a statistical beast predicting the next word by crunching probabilities. It’s not intelligence - it’s autocomplete on steroids. LRMs add “thinking steps,” but Apple proved those are a chaotic mess, not reasoning.
|
||||
|
||||
Scraped datasets are a toxic stew of biases, errors, and garbage. Models inherit these flaws, amplifying hate, misinformation, and stereotypes. The X post’s “clean datasets” claim is a fantasy. Models memorize training data, regurgitating answers, acing benchmarks but choking on novel problems - not smarts, but cheating. Scaled models do unpredictable, creepy things - generating lies or toxic content - and we don’t know why, like breeding a mutant that bites.
|
||||
|
||||
Transformers’ attention mechanisms “hallucinate” nonexistent connections, sparking errors that could mean lawsuits or worse in production. Models overfit to scraped data quirks, brittle in real-world scenarios - a context shift, and they’re lost. LRMs burn obscene resources for negligible gains. Apple showed their “reasoning” doesn’t scale, yet we torch energy grids to keep the farce alive.
|
||||
|
||||
A 2021 arXiv paper outlines six risk areas for LLMs, including discrimination, toxicity, misinformation, and environmental harms, all amplified by flawed data [arXiv, 2021](https://arxiv.org/abs/2112.04359). This isn’t a system - it’s a house of horrors, and deploying it on stolen, server-killing data is lunacy.
|
||||
|
||||
## Why Deployment Is a Betrayal
|
||||
|
||||
Deploying LLMs and LRMs, fueled by unethical scraping, is a middle finger to reason, ethics, and survival. Apple’s research proves these models collapse on complex tasks. In production, that’s a body count - an LRM misdiagnosing cancer kills a patient, a trading algorithm misreading a signal wipes out trillions, a military drone misjudging a target levels a village. These are certainties.
|
||||
|
||||
Amodei’s right: we can’t explain a damn thing these models do. If an AI denies your loan or flags you as a criminal, nobody can trace the logic. It’s a black box with a “trust me” sticker, not engineering but tyranny. LRMs are as reliable as a drunk tightrope walker, acing one task and botching the next. An AI air traffic controller brilliant Monday but brain-dead Tuesday kills thousands.
|
||||
|
||||
Benchmarks are a con, rigged because models train on test problems, faking genius. Apple’s puzzles exposed the truth: in the real world, they’re clueless. Deploying based on fake scores is fraud. LLMs, built on stolen data, spew bias, lies, and hate. Scaling that is weaponizing chaos - an AI newsroom churning propaganda, a hiring tool blacklisting groups, a legal bot fabricating evidence. This is how civilizations rot.
|
||||
|
||||
The AI hype train is a cult, brainwashing us into worshipping statistical parrots as gods, screaming “reasoning!” and “intelligence!” when it’s all lies, driving us off a cliff. Real-world nightmares abound: an LRM in a self-driving car misreads an intersection, causing a pileup killing dozens; an AI teacher misgrades exams, ruining futures; a power grid AI miscalculates, triggering blackouts for millions. These are headlines waiting to happen.
|
||||
|
||||
Outsourcing decisions to AI strips human agency, turning us into drones who can’t question or innovate - not augmenting humanity but lobotomizing it. Production use breeds dependence. When LLMs fail, systems collapse - hospitals halt, markets freeze, supply chains implode, leaving us one glitch from anarchy. LLMs craft lies that fool experts. In production, they could sway elections, manipulate juries, or radicalize masses - we’re not ready for AI-powered propaganda.
|
||||
|
||||
Governments are asleep, with no framework to govern AI or scraping’s risks, no accountability, like letting a toddler play with a nuclear reactor. AI and scraping concentrate power in a few tech titans who afford the compute and data, yet their creations control us, widening the elite-everyone gap. When AI fails, trust in tech and institutions will crater. A high-profile disaster could spark a backlash, halting progress for decades. We’re gambling the future on a losing bet.
|
||||
|
||||
Autonomous AI in critical systems, powered by flawed LRMs, is a death sentence - Apple’s research shows failures go unchecked without human oversight, amplifying harm exponentially. Scraping’s data theft, glorified by the X post, steals from creators, undermining the web’s creative ecosystem. Deploying LLMs built on this is endorsing piracy at scale. Scraping’s server attacks are killing the open web, forcing websites behind paywalls or offline, shrinking the internet’s diversity. LLMs are complicit in this murder.
|
||||
|
||||
## Toxic Incentives: Profit Over Existence
|
||||
|
||||
This insanity is driven by perverse incentives. Venture capitalists demand unicorn returns, so companies rush half-baked models and scraping pipelines to market. OpenAI’s profit-chasing pivot, as Amodei criticized, is the blueprint for this rot. Safety, ethics, and infrastructure are roadkill under “move fast and break things.”
|
||||
|
||||
The X post’s Scrapy worship shows developers are complicit, treating server abuse as a feature, not a bug. The academic-industrial complex is guilty too, with researchers trading integrity for paychecks, churning out hype papers instead of hard questions. Apple’s study is a rare exception - most research is a glorified ad. Whistleblowers like Amodei are drowned out by “AI will save us!” propaganda. It’s a machine built to self-destruct, and we’re all strapped in.
|
||||
|
||||
## The Myth of “Safe” AI
|
||||
|
||||
The industry’s “we’ll make AI safe” mantra is bullshit. Apple’s research shows LRMs are inherently unreliable, and Amodei admits we can’t define the problem. Safety measures like alignment are guesswork - Anthropic’s red-teaming caught flaws, but scaling that is a fantasy. Scraping’s ethical rot makes it worse: models built on stolen data are tainted from birth. “Safe AI” is a marketing ploy. Deploying now is boarding a plane with a “probably not crashing” guarantee.
|
||||
|
||||
## The Path Forward: Research, Not Recklessness
|
||||
|
||||
This is a five-alarm fire. Deploying LLMs and LRMs, fueled by scraping’s destruction, is suicidal. They must stay in labs until we crack the black box and stop killing the internet.
|
||||
|
||||
Ideas:
|
||||
|
||||
- Ban these models from critical systems - healthcare, finance, defense, governance - allowing only tightly overseen non-critical uses like content generation.
|
||||
- Pour resources into interpretability, chasing Amodei’s “MRI” vision until we trace every decision.
|
||||
- Curb aggressive scraping tools like Scrapy, enforcing sane defaults - rate limits, consent protocols - with penalties for server-hammering or data theft.
|
||||
- Adopt Apple’s puzzle-based testing, using novel, complex problems, not rigged benchmarks.
|
||||
- Demand transparency - no “proprietary” excuses; open-source model architectures, training data, failure logs. Scraping pipelines must disclose sources and impacts.
|
||||
- Regulate AI and scraping like nuclear weapons - global standards, audits, severe penalties for reckless deployment or server abuse.
|
||||
- Build tools that augment, not replace, human decisions. AI is a calculator, not a dictator.
|
||||
- Educate the public to demystify AI and scraping’s limits, teaching these are statistical toys built on stolen data, not gods, to curb blind trust.
|
||||
- Freeze model size, compute, and scraping until we understand what we’ve got - bigger is riskier, not better.
|
||||
- Force companies to pay for scraped data or face lawsuits, protecting the web’s creative ecosystem.
|
||||
|
||||
## My Final Takeaway
|
||||
|
||||
The AI industry’s peddling a fairy tale, and we’re the suckers buying it. LLMs and LRMs aren’t saviors - they’re ticking bombs wrapped in buzzwords, built on a dying internet’s ashes. Apple’s *The Illusion of Thinking* and Amodei’s confession are klaxons blaring in our faces. Scrapy’s server-killing rampage, glorified on X, is the final straw - we’re not just risking failure; we’re murdering the digital world that sustains us.
|
||||
|
||||
Deploying LLMs and LRMs, fueled by scraping’s destruction, isn’t just dumb - it’s a crime against our survival. Lock them in the lab, crack the code, and stop the internet’s slaughter, or brace for the apocalypse. The clock’s ticking, and we’re out of excuses.
|
||||
@ -0,0 +1,194 @@
|
||||
<!-- lead -->
|
||||
Setting up a scalable, secure, and modular Minecraft server system is no easy feat.
|
||||
|
||||
In this post we will look into how to deploy a Minecraft cluster using Docker, orchestrate the servers with PM2, and manage secure peer-to-peer connections with Holesail.
|
||||
|
||||
Whether you're a hobbyist or managing servers for a community, this system provides everything you need to run a robust setup.
|
||||
|
||||
|
||||
|
||||
# Cluster Source Code:
|
||||
|
||||
## https://git.ssh.surf/snxraven/mc-cluster
|
||||
|
||||
## Why Build a Minecraft Cluster:
|
||||
|
||||
Running a single Minecraft server can be sufficient for small groups, but as player numbers grow, or if you want to offer different experiences (e.g., creative, survival, or modded servers), a clustered setup becomes invaluable. The key benefits include:
|
||||
|
||||
1. **Scalability**: Add or remove servers based on demand.
|
||||
2. **Flexibility**: Host different game modes or mods on separate servers.
|
||||
3. **Performance**: Distribute player loads across multiple servers.
|
||||
4. **Security**: Use Holesail for end-to-end encrypted peer-to-peer communication.
|
||||
|
||||
|
||||
|
||||
## Overview of the System
|
||||
|
||||
This system consists of three major components:
|
||||
|
||||
1. **Minecraft Server Cluster**: A group of Minecraft servers running FabricMC for mod support, deployed with Docker Compose and orchestrated using PM2.
|
||||
2. **Velocity Proxy**: A lightweight proxy that routes player connections to the appropriate Minecraft server.
|
||||
3. **Holesail Networking**: Secure peer-to-peer networking for managing connections between servers and the proxy.
|
||||
|
||||
Here’s a simplified architecture:
|
||||
|
||||
```
|
||||
Players → Velocity Proxy (JUMP Node) → Minecraft Cluster (MC Host Node)
|
||||
```
|
||||
|
||||
|
||||
|
||||
## Component Breakdown
|
||||
|
||||
### 1. **Minecraft Cluster**
|
||||
|
||||
The cluster is built using Docker Compose, allowing multiple Minecraft servers to run in isolated containers. Each server has:
|
||||
|
||||
- **FabricMC**: For modding support.
|
||||
- **PM2**: Process manager to ensure stability and logs.
|
||||
- **Holesail Integration**: Secure connections using predefined connection strings.
|
||||
|
||||
**How It Works**:
|
||||
- The `docker-compose.yml` defines the services (servers) in the cluster.
|
||||
- Each server is configured with its own Holesail connection string and port.
|
||||
- PM2 ensures the servers restart automatically if they crash.
|
||||
|
||||
|
||||
|
||||
### 2. **Velocity Proxy**
|
||||
|
||||
Velocity is a Minecraft proxy designed for performance and flexibility. It routes player traffic to the appropriate backend Minecraft servers.
|
||||
|
||||
**Features**:
|
||||
- **Customizable MOTD**: Tailor the server’s welcome message.
|
||||
- **Player Forwarding**: Seamlessly switch players between servers.
|
||||
- **Holesail Integration**: Secure backend connections.
|
||||
|
||||
**How It Works**:
|
||||
- The `velocity.toml` configuration file specifies backend servers and ports.
|
||||
- Players connect to the Velocity proxy, which uses Holesail to route traffic to the appropriate server in the cluster.
|
||||
|
||||
|
||||
|
||||
### 3. **Holesail Networking**
|
||||
|
||||
Holesail provides secure peer-to-peer networking using connection strings. This ensures encrypted communication between the Velocity proxy and Minecraft servers.
|
||||
|
||||
**Key Points**:
|
||||
- Each server is assigned a unique connection string and port.
|
||||
- The `pm2-setup.sh` script initializes Holesail connections.
|
||||
- Holesail manages end-to-end encryption, ensuring secure traffic.
|
||||
|
||||
|
||||
|
||||
## Step-by-Step Deployment Guide
|
||||
|
||||
### **Step 1: Set Up the Minecraft Host Node**
|
||||
|
||||
This node hosts the Minecraft server cluster.
|
||||
|
||||
1. **Clone the Repository**:
|
||||
```bash
|
||||
git clone https://git.ssh.surf/snxraven/mc-cluster.git
|
||||
cd mc-cluster/mc-cluster-image
|
||||
```
|
||||
|
||||
2. **Build the Minecraft Cluster Image**:
|
||||
```bash
|
||||
docker build . -t mc:cluster
|
||||
```
|
||||
|
||||
3. **Navigate Back to the Main Directory**:
|
||||
```bash
|
||||
cd ..
|
||||
```
|
||||
|
||||
4. **Start the Cluster**:
|
||||
```bash
|
||||
docker-compose up -d
|
||||
```
|
||||
|
||||
This command deploys a cluster of Minecraft servers, each with its own connection string and port defined in `pm2-setup.sh`.
|
||||
|
||||
|
||||
|
||||
### **Step 2: Set Up the JUMP Node**
|
||||
|
||||
The JUMP node hosts the Velocity proxy, managing player connections and routing traffic to the Minecraft cluster. The docker compose also starts up the holesail connections to bind the remote Minecraft servers to the local JUMP Server. All connections within velocity are configured within localhost.
|
||||
|
||||
1. **Clone the Repository**:
|
||||
```bash
|
||||
git clone https://git.ssh.surf/snxraven/mc-cluster.git
|
||||
cd mc-cluster/velocity-image
|
||||
```
|
||||
|
||||
2. **Build the Velocity Proxy Image**:
|
||||
```bash
|
||||
docker build . -t velocity:proxy
|
||||
```
|
||||
|
||||
3. **Start the Proxy**:
|
||||
```bash
|
||||
docker-compose up -d
|
||||
```
|
||||
|
||||
## Customization and Advanced Configuration
|
||||
|
||||
### Minecraft Cluster Customization
|
||||
|
||||
- **Add/Remove Servers**:
|
||||
Edit the `docker-compose.yml` file and modify the `services` section.
|
||||
|
||||
Example:
|
||||
```yaml
|
||||
services:
|
||||
mc-server-1:
|
||||
image: mc:cluster
|
||||
environment:
|
||||
CONNECTION_STRING: "mc-server-1"
|
||||
PORT: "5000"
|
||||
mc-server-2:
|
||||
image: mc:cluster
|
||||
environment:
|
||||
CONNECTION_STRING: "mc-server-2"
|
||||
PORT: "5001"
|
||||
```
|
||||
|
||||
### Velocity Proxy Customization
|
||||
|
||||
- **MOTD and Server List**:
|
||||
Modify `velocity.toml` to change the MOTD and backend server settings.
|
||||
|
||||
Example:
|
||||
```toml
|
||||
motd = "&aWelcome to our Minecraft Cluster!"
|
||||
[servers]
|
||||
lobby = "mc-server-1"
|
||||
survival = "mc-server-2"
|
||||
```
|
||||
|
||||
- **Secure Player Forwarding**:
|
||||
Update the `forwarding.secret` file for secure player forwarding.
|
||||
|
||||
|
||||
|
||||
## Troubleshooting
|
||||
|
||||
### Common Issues
|
||||
|
||||
1. **Holesail Connection Error**:
|
||||
- Ensure the `CONNECTION_STRING` and `PORT` values are correctly set.
|
||||
|
||||
2. **Velocity Not Forwarding Players**:
|
||||
- Ensure the `velocity.toml` file has the correct backend server configurations.
|
||||
|
||||
|
||||
|
||||
## Future Enhancements
|
||||
|
||||
- **Auto-Scaling**:
|
||||
Add or remove Minecraft servers dynamically based on player load.
|
||||
- **Integrated Monitoring**:
|
||||
Use tools like Netdata to monitor server performance and health.
|
||||
- **Web Dashboard**:
|
||||
Develop a web interface for managing the cluster, viewing logs, and deploying updates.
|
||||
304
markdown/Oracle Free Tier: The Best Free Host Around.md
Normal file
@ -0,0 +1,304 @@
|
||||
### What is Oracle Free Tier?
|
||||
|
||||
When exploring cloud services, one of the most important factors to consider is how much you can accomplish without breaking the bank.
|
||||
|
||||
That's where **Oracle's Free Tier** comes in—a cloud offering that provides access to powerful computing, storage, networking, and database resources at no cost.
|
||||
|
||||
Oracle’s Free Tier gives you the freedom to build and scale applications without worrying about upfront costs or limitations.
|
||||
|
||||
In this post, we’ll dive into what Oracle Free Tier is, what it offers, and how you can take advantage of it.
|
||||
|
||||
### Access Oracle's free services today: https://www.oracle.com/cloud/free/
|
||||
|
||||
|
||||
|
||||
## Before we begin...
|
||||
# What is a VPS (Virtual Private Server)?
|
||||
<!-- lead -->
|
||||
Why Oracle Cloud is still one of the best offerings on the planet since its launch.
|
||||
|
||||
A **Virtual Private Server (VPS)** is a type of server that operates in a shared environment but behaves as though it's a dedicated server. The VPS provider allocates a portion of their physical server's resources to you, along with an operating system, granting you the freedom to build websites, run software, or even host game servers.
|
||||
|
||||
With a VPS, you essentially have your own **virtual machine** on the server, allowing you complete control over your space. This flexibility makes VPS hosting ideal when you require more power than a shared hosting account but don't want the hefty costs associated with a dedicated server. It combines the functionality and customization of a dedicated server at a fraction of the price.
|
||||
|
||||
Unlike shared hosting, where hundreds of websites are housed on the same server, VPS hosting offers much greater control over your resources. You can install custom software, configure settings, and tailor the environment to your specific needs. Best of all, VPS hosting is often far less expensive than dedicated hosting, making it a great choice for those seeking the best of both worlds.
|
||||
|
||||
## Why Do You Need a VPS?
|
||||
|
||||
VPS hosting offers enhanced security and privacy for individual websites and applications.
|
||||
|
||||
It’s a fantastic option for hosting websites, online stores, or any other project that demands ample resources and scalability. VPS hosting is like a **server on steroids**, providing abundant resources and the ability to scale up or down as your needs evolve. It’s an excellent choice for both beginners and experienced users alike.
|
||||
|
||||
With a VPS, you’ll experience a significant speed boost for your website—much faster than shared hosting can offer. If you're running a **mission-critical** website or project that requires zero downtime or experiences significant traffic fluctuations, a VPS is a must.
|
||||
|
||||
Additionally, virtual private servers tend to be as affordable as quality shared hosting plans but come with far less downtime.
|
||||
|
||||
Besides web hosting, VPS is a perfect solution for hosting game servers. Whether you’re running a **Minecraft** server or another game, you can easily set up a VPS and play with your friends.
|
||||
|
||||
When your shared hosting account reaches its limits, it's time to upgrade to a VPS to harness the full power of virtual servers.
|
||||
|
||||
A VPS hosting environment allows you to host websites without sharing resources with others on the same server, giving you complete control over your environment. You can also host multiple websites on a single physical server, lowering costs and improving performance.
|
||||
|
||||
For high-traffic websites, VPS hosting is the way to go—it delivers superior performance and reliability compared to shared hosting.
|
||||
|
||||
### Free Trial Explained
|
||||
|
||||
Oracle Cloud offers a **free trial** for first-time customers, providing an excellent opportunity to explore the platform and test its capabilities before making a financial commitment. This trial allows users to familiarize themselves with Oracle’s services, ensuring compatibility and performance within their specific use cases.
|
||||
|
||||
The free trial is a hands-on way for users to gain valuable experience and understand how to best utilize the platform’s features. It helps potential customers feel more confident and secure about how Oracle Cloud will perform in their environment, making it an ideal way to experiment with different cloud solutions.
|
||||
|
||||
The trial lasts for **30 days** and includes **$300 in credits**, giving users full access to Oracle Cloud's upgraded services during this period. These credits can be used across a wide range of services, including databases, analytics, compute, and container engines for Kubernetes.
|
||||
|
||||
It's important to note that the **free trial** is different from the **Always Free Tier**. Once the trial ends, users transition into the Always Free Tier, which provides a set of free resources that last indefinitely. The trial’s credits are consumed at a discounted rate, allowing users to fully explore Oracle Cloud’s premium offerings before the free tier kicks in.
|
||||
|
||||
This trial is available worldwide in multiple regions, but remember to distinguish between the **trial** and the **Always Free Tier**, as they serve different purposes and offer different benefits.
|
||||
|
||||
#### Now that we know what those concepts are, lets talk about free hosting.
|
||||
## Oracle Always Free Tier: Features
|
||||
|
||||
Oracle offers an exceptionally generous **Always Free Tier** that provides multiple services at no cost.
|
||||
|
||||
Below is a summarized breakdown of what Oracle offers within the **Always Free** plan:
|
||||
|
||||
### **Compute**
|
||||
- **AMD Compute Instance**
|
||||
2 AMD-based Compute VMs with 1/8 OCPU and 1 GB of memory each.
|
||||
- **Arm Compute Instance**
|
||||
4 Arm-based Ampere A1 cores with 24 GB of memory, which can be used as a single VM or split into up to 4 VMs.
|
||||
- **3,000 OCPU hours** and **18,000 GB hours** per month.
|
||||
|
||||
### **Developer Services**
|
||||
- **APEX (Application Express)**
|
||||
A low-code platform for building, integrating, and innovating applications with up to 744 hours per instance.
|
||||
|
||||
### **Networking**
|
||||
- **Flexible Network Load Balancer**
|
||||
Provides automated traffic distribution, ensuring services remain available by routing traffic only to healthy servers.
|
||||
Always Free: 1 instance.
|
||||
- **Load Balancer**
|
||||
Allows for highly available load balancers within your Virtual Cloud Network (VCN) with 10 Mbps bandwidth.
|
||||
Always Free: 1 instance.
|
||||
- **Outbound Data Transfer**
|
||||
Always Free: Up to 10 TB per month.
|
||||
- **Service Connector Hub**
|
||||
A cloud message bus platform for moving data between Oracle Cloud services.
|
||||
Always Free: 2 service connectors.
|
||||
- **Site-to-Site VPN**
|
||||
Secure IPSec connection between your on-premises network and your VCN.
|
||||
Always Free: 50 IPSec connections.
|
||||
- **VCN Flow Logs**
|
||||
Logs traffic through your VCN for auditing and security purposes.
|
||||
Always Free: 10 GB per month shared across OCI Logging services.
|
||||
- **Virtual Cloud Networks (VCN)**
|
||||
Allows the creation of software-defined networks.
|
||||
Always Free: 2 VCNs with IPv4 and IPv6 support.
|
||||
|
||||
### **Observability and Management**
|
||||
- **Application Performance Monitoring**
|
||||
Monitors application performance and diagnoses issues.
|
||||
Always Free: Up to 1000 tracing events and 10 Synthetic Monitoring runs per hour.
|
||||
- **Email Delivery**
|
||||
Managed solution for sending secure, high-volume emails.
|
||||
Always Free: Up to 100 emails sent per day.
|
||||
- **Logging**
|
||||
Centralized, scalable logging service.
|
||||
Always Free: Up to 10 GB per month.
|
||||
- **Monitoring**
|
||||
Queries metrics and manages alarms to monitor the health of cloud resources.
|
||||
Always Free: Up to 500 million ingestion datapoints, 1 billion retrieval datapoints.
|
||||
- **Notification**
|
||||
Sends alerts based on cloud resource activities.
|
||||
Always Free: Up to 1 million HTTP notifications and 1,000 email notifications per month.
|
||||
|
||||
### **Oracle Databases**
|
||||
- **Autonomous Database**
|
||||
Fully managed databases like Oracle Autonomous Transaction Processing and Autonomous Data Warehouse.
|
||||
Always Free: Up to two databases total.
|
||||
- **HeatWave**
|
||||
An integrated service for transactions, analytics, and generative AI.
|
||||
Always Free: 1 standalone instance with 50 GB of storage and 50 GB of backup storage.
|
||||
- **NoSQL Database**
|
||||
Fully managed, low-latency NoSQL database.
|
||||
Always Free: Up to 133 million reads, 133 million writes per month, and 25 GB of storage per table (up to 3 tables).
|
||||
|
||||
### **Others**
|
||||
- **Console Dashboards**
|
||||
Custom dashboards to monitor resources and key metrics.
|
||||
Always Free: Up to 100 dashboards.
|
||||
|
||||
### **Security**
|
||||
- **Bastions**
|
||||
Provides restricted SSH access to resources without public endpoints.
|
||||
Always Free: Up to 5 OCI Bastions.
|
||||
- **Certificates**
|
||||
Issuance, storage, and management of certificates, including automatic renewal.
|
||||
Always Free: Up to 5 Private CAs and 150 private TLS certificates.
|
||||
- **Vault**
|
||||
Manages master encryption keys and secrets with hardware security module (HSM) protection.
|
||||
Always Free: Up to 20 key versions and 150 secrets.
|
||||
|
||||
### **Storage**
|
||||
- **Archive Storage**
|
||||
Unstructured archive storage.
|
||||
Always Free: Up to 20 GB total for standard, infrequent, and archive storage.
|
||||
- **Block Volume Storage**
|
||||
Boot and block volume storage.
|
||||
Always Free: Up to 2 block volumes (200 GB total) and 5 backups.
|
||||
- **Object Storage**
|
||||
Object Storage API requests.
|
||||
Always Free: Up to 50,000 API requests per month.
|
||||
- **Object Storage - Infrequent Access**
|
||||
Unstructured storage for infrequently accessed data.
|
||||
Always Free: Up to 20 GB total.
|
||||
- **Object Storage - Standard**
|
||||
Standard unstructured storage.
|
||||
Always Free: Up to 20 GB total for standard, infrequent, and archive storage.
|
||||
|
||||
## Oracle Free Tier: A Comprehensive Breakdown of the Above summary
|
||||
|
||||
Oracle Cloud’s Always Free Tier stands out as a top choice for developers, startups, and businesses that require a robust, scalable cloud environment without the burden of upfront costs. With an impressive suite of compute, storage, database, and networking services, Oracle consistently outperforms competitors, offering far more generous free resources that can support everything from small web applications to more demanding, high-traffic environments.
|
||||
|
||||
In my personal experience, I’ve hosted Discord-Linux.com on Oracle Cloud for over 5 years, and I can confidently say that I have had zero issues during this time. The platform has proven to be reliable and efficient, handling everything from server management to traffic fluctuations effortlessly. In fact, the very blog you are reading is running on Oracle Cloud, utilizing only the free resources available under the Always Free Tier. Oracle’s stability and generous offering make it an unbeatable solution for those looking for both reliability and scalability without the associated costs.
|
||||
|
||||
Below, we’ll review Oracle’s **Always Free Tier** offerings, highlight the strengths and limitations, and assess how they compare to other providers like AWS, Google Cloud, and Microsoft Azure.
|
||||
|
||||
### **Compute Services**
|
||||
|
||||
Oracle Cloud’s **compute offerings** are perhaps the most significant draw of the Always Free Tier. The **AMD Compute Instances** and **Arm Compute Instances** provide considerable flexibility for users with a variety of needs.
|
||||
|
||||
- **AMD Compute Instance**: This includes **2 VMs** with 1/8 OCPU and 1 GB of memory each. While these may seem modest specs, for simple workloads such as small web servers, test environments, or lightweight applications, these VMs can be invaluable. The ability to run two instances simultaneously increases the scope of potential projects, making it possible to deploy a frontend/backend setup or even experiment with multi-node applications.
|
||||
|
||||
- **Arm Compute Instance**: The **Arm-based Ampere A1** cores are the stars of Oracle’s free compute resources. You get **24 GB of memory**, which can be allocated to **one large VM or split into four smaller VMs**. This flexibility offers developers an excellent opportunity to scale their applications, test distributed systems, or handle larger workloads without paying a cent. The performance of Ampere A1 processors is highly competitive, and with up to **3,000 OCPU hours** per month, users can push these instances to handle significant loads, making them suitable for high-traffic websites, data processing tasks, or even hosting games like Minecraft.
|
||||
|
||||
Oracle’s free compute offerings stand out for providing more CPU hours than competitors, allowing for sustained, non-stop operations, unlike other platforms that offer more limited timeframes.
|
||||
|
||||
### **Developer Services**
|
||||
|
||||
- **APEX (Application Express)**: Oracle APEX is one of the industry’s leading **low-code platforms**, and Oracle’s inclusion of this in the Always Free Tier is a major boon for developers looking to quickly build and deploy applications. This service is ideal for businesses or individuals looking to create **internal tools**, web apps, or even mobile backends without needing to manage large infrastructure. With **up to 744 hours** per instance, it’s a valuable tool for anyone needing rapid development without the complexity of traditional coding.
|
||||
|
||||
### **Networking Features**
|
||||
|
||||
Networking is often where hidden costs accumulate in cloud platforms, but Oracle’s Always Free Tier offers a range of useful services that help alleviate these concerns.
|
||||
|
||||
- **Flexible Network Load Balancer**: Oracle’s **Network Load Balancer** ensures that your applications remain available, distributing traffic only to healthy servers. This is especially valuable for high-availability applications. While **1 instance** is available for free, it’s sufficient for most small-scale projects that require automated traffic distribution.
|
||||
|
||||
- **Load Balancer**: For those who need a more traditional load balancing setup with **provisioned bandwidth** of up to 10 Mbps, this service provides excellent reliability. Again, **1 instance** is included, which can support basic scaling needs for your applications without additional cost.
|
||||
|
||||
- **Outbound Data Transfer**: A key feature here is the **10 TB per month** of free outbound data transfer. This is **exceptionally generous**, especially when compared to AWS or Google Cloud, which often charge after a very limited amount of free outbound data. This amount allows you to handle moderate to high-traffic websites, content delivery, or other data-heavy applications without worrying about expensive data transfer fees.
|
||||
|
||||
- **Site-to-Site VPN**: For hybrid cloud setups or secure on-premises connections, Oracle’s free tier includes **50 IPSec VPN connections**. This feature is invaluable for enterprises or developers needing to securely extend their local network into the cloud.
|
||||
|
||||
- **VCN Flow Logs**: Oracle offers **up to 10 GB of VCN flow logs per month**. These logs are essential for auditing traffic, troubleshooting network issues, and ensuring security across your cloud infrastructure.
|
||||
|
||||
### **Observability and Management**
|
||||
|
||||
- **Application Performance Monitoring (APM)**: Application monitoring and tracing are typically expensive features in most cloud platforms, but Oracle includes **1000 tracing events** and **10 Synthetic Monitoring runs per hour**. This is particularly useful for developers needing to pinpoint performance bottlenecks or ensure their applications are running smoothly without extra cost.
|
||||
|
||||
- **Email Delivery**: Oracle’s free tier allows you to send **up to 100 emails per day**, making it a viable solution for sending transactional emails, marketing campaigns, or notifications directly from your cloud applications.
|
||||
|
||||
- **Logging**: The **Logging service** allows for **up to 10 GB per month** of log data. This amount is sufficient for most small- to medium-scale applications and provides a scalable way to store and analyze logs without paying for third-party logging solutions.
|
||||
|
||||
- **Monitoring and Notifications**: Oracle offers **500 million ingestion datapoints** and **1 billion retrieval datapoints**, which is ample for even larger-scale applications. The **Notifications service** adds another layer of observability, sending up to **1 million HTTP notifications** or **1,000 emails per month**. These capabilities are highly advantageous for DevOps teams or developers needing to monitor performance metrics in real-time.
|
||||
|
||||
### **Oracle Databases**
|
||||
|
||||
Oracle is well-known for its database technology, and the Always Free Tier includes multiple offerings that can be pivotal for building robust data-driven applications.
|
||||
|
||||
- **Autonomous Databases**: Oracle’s Autonomous Database products, such as **Autonomous Transaction Processing** and **Autonomous Data Warehouse**, offer up to **two databases** free of charge. These databases are ideal for organizations requiring high performance, automation, and scalability without the management overhead of traditional database administration.
|
||||
|
||||
- **HeatWave**: With **1 standalone HeatWave instance** available, Oracle allows users to perform **AI-enhanced analytics** and data processing without needing to integrate external services. HeatWave’s ability to handle transactional workloads and lakehouse-scale analytics makes it a unique offering among cloud providers.
|
||||
|
||||
- **NoSQL Database**: For those working with **key-value**, document-based, or fixed-schema data, Oracle’s NoSQL offering provides **133 million reads/writes per month** with **25 GB of storage per table**. This is a compelling choice for building scalable, low-latency applications without worrying about high database costs.
|
||||
|
||||
### **Security Features**
|
||||
|
||||
- **Bastions**: Securely managing cloud infrastructure can be complex, but Oracle simplifies this with **up to 5 Bastions**. These provide **restricted SSH access** to resources without exposing them to the internet, ensuring enhanced security.
|
||||
|
||||
- **Certificates**: Oracle’s **Certificates service** allows for **automatic renewal** of up to **150 private TLS certificates**, along with **5 Private CAs**. This makes it easy for developers to manage secure communication between applications.
|
||||
|
||||
- **Vault**: OCI Vault is included with **20 key versions** and **150 secrets**. This provides a managed, secure way to handle encryption keys and secrets, which is essential for any sensitive or mission-critical application.
|
||||
|
||||
### **Storage Services**
|
||||
|
||||
Oracle’s storage options are well-rounded and comprehensive:
|
||||
|
||||
- **Block Volume Storage**: Up to **2 block volumes** with **200 GB total** storage, along with **5 backups**, make Oracle’s block storage a solid choice for hosting applications, databases, or even Docker containers.
|
||||
|
||||
- **Object Storage**: With **50,000 API requests per month** and **20 GB of standard and infrequent storage**, Oracle ensures that you have enough capacity for most personal or small-business use cases.
|
||||
|
||||
- **Archive Storage**: With **20 GB** of archive storage included, Oracle offers an easy solution for long-term backups or low-cost storage of infrequently accessed data.
|
||||
|
||||
### My Thoughts: Oracle Cloud's Always Free Tier
|
||||
|
||||
Oracle Cloud’s **Always Free Tier** stands out as a top choice for developers, startups, and businesses that require a robust, scalable cloud environment without the burden of upfront costs. With an impressive suite of compute, storage, database, and networking services, Oracle consistently outperforms competitors, offering far more generous free resources that can support everything from small web applications to more demanding, high-traffic environments.
|
||||
|
||||
Whether you're building a simple website, running a data-heavy application, or deploying complex services, Oracle Cloud provides the performance and flexibility needed to grow without incurring significant costs. Here’s a more in-depth look at its advantages and potential drawbacks:
|
||||
|
||||
### **Pros**:
|
||||
- **Generous compute resources**: Oracle's Always Free Tier offers **Arm-based Ampere A1 cores** and **AMD-based VMs**, giving users access to up to **24 GB of memory**. These resources far exceed what other cloud providers offer for free, enabling you to run substantial workloads, such as high-traffic web servers, data processing, or even game hosting.
|
||||
|
||||
- **Substantial outbound data transfer**: Oracle provides **10 TB per month** of outbound data transfer, which is especially generous compared to AWS, Google Cloud, and Azure. This is more than enough to handle the data requirements of most websites, applications, or content delivery networks without worrying about hidden fees.
|
||||
|
||||
- **Industry-leading Autonomous and NoSQL Databases**: Free access to Oracle’s **Autonomous Database** and **NoSQL Database** ensures that users benefit from top-tier database management without the need for manual optimization or costly administration. This is a major selling point for developers who need powerful, scalable, and self-managing databases.
|
||||
|
||||
- **Extensive networking and security features**: Oracle includes **VPN**, **Site-to-Site VPN**, **Bastions**, and **Load Balancers**, all within the Always Free Tier. These networking and security tools are essential for securely connecting on-premise networks to the cloud and ensuring seamless service availability with minimal latency.
|
||||
|
||||
- **Comprehensive monitoring, logging, and notifications**: Oracle's observability services, including **Application Performance Monitoring**, **Logging**, **Monitoring**, and **Notifications**, provide deep insights into cloud applications. These tools offer real-time visibility into application health, performance metrics, and security, making it easy to maintain optimal operation without added cost.
|
||||
|
||||
### **Cons**:
|
||||
- **Complex interface and setup**: While Oracle Cloud is highly powerful, its interface and setup process can be more complex than other platforms, such as AWS or Google Cloud, which offer more beginner-friendly user experiences. For those unfamiliar with Oracle’s cloud ecosystem, the learning curve can be steep, requiring additional time and effort to master.
|
||||
|
||||
- **Limited third-party integrations**: Oracle's ecosystem may not offer as wide a selection of third-party integrations and tools as AWS or Google Cloud. If your project relies heavily on third-party services, you might find Oracle's range somewhat restrictive compared to the broad support offered by its competitors.
|
||||
|
||||
# **FAQs**
|
||||
|
||||
- **Can I use a Virtual Credit Card (VCC) with Oracle Cloud?**
|
||||
Unfortunately, Oracle Cloud does not support Virtual Credit Cards (VCC).
|
||||
|
||||
To complete the sign-up process, you’ll need to use a real credit card issued by a recognized bank.
|
||||
|
||||
This ensures verification and is necessary to activate your Oracle Cloud account, even for the free tier.
|
||||
|
||||
- **Will I ever be charged using a free teir account?**
|
||||
From what I have noticed Oracle does not seem to store payment details during the signup process within the always free service.
|
||||
|
||||
You must click the purple upgrade button and submit payment details aswell as wait 24 hours for your account to be upgraded to a paid version of the Oracle Cloud.
|
||||
|
||||
Due to this, there should not be any charges imposed during the usage of an always free account.
|
||||
|
||||
- **Why was my Oracle VM made inaccessible even though I'm on the free tier?**
|
||||
If your Oracle VM was created during the free trial period, it will be automatically locked after 30 days unless you upgrade to a paid account.
|
||||
|
||||
After the trial ends, you'll transition into the Always Free Tier, where any resources created under this tier will remain active indefinitely.
|
||||
|
||||
To retain the data from your current instance, you can terminate the premium instance created during the trial without deleting the boot disk.
|
||||
|
||||
You can then use that boot disk to create a new Always Free instance. Once booted, your server will resume as expected, with all your software and configurations intact.
|
||||
|
||||
- **Can I mine cryptocurrency on my Oracle Cloud account?**
|
||||
No, Oracle strictly prohibits cryptocurrency mining on its cloud infrastructure.
|
||||
|
||||
Any account found engaging in crypto mining will be terminated immediately.
|
||||
|
||||
Oracle enforces this policy to prevent resource abuse and ensure fair use of its free tier services.
|
||||
|
||||
- **Why are all ports blocked on my Oracle VPS?**
|
||||
By default, all incoming traffic is blocked to enhance security.
|
||||
|
||||
To allow specific traffic, you’ll need to create **ingress rules** in your security group settings to open the required ports.
|
||||
|
||||
This ensures that only authorized traffic can access your virtual private server, offering an additional layer of protection.
|
||||
|
||||
- **Is Windows VPS available in the free tier?**
|
||||
No, Windows VPS instances are not available in the Always Free Tier.
|
||||
|
||||
Access to Windows servers is reserved for upgraded accounts.
|
||||
|
||||
However, you can utilize Linux-based VMs, such as Ubuntu or Oracle Linux, in the free tier.
|
||||
|
||||
- **I received an "Out of Capacity" error. What should I do?**
|
||||
Oracle Cloud resources are limited by region, and if your selected region has reached capacity, you’ll receive this error.
|
||||
|
||||
To resolve this, you can either wait for Oracle to replenish resources in your chosen region or select another region with available capacity to create your instance.
|
||||
|
||||
I also find that upgrading your account is a great option to resolve this issue. Always free resources remain even if the account is upgraded.
|
||||
378
markdown/Peardock: P2P Container Managment.md
Normal file
@ -0,0 +1,378 @@
|
||||
<!-- lead -->
|
||||
Creating private and secure P2P Docker Managment System
|
||||
|
||||
## Introduction
|
||||
|
||||
**Peardock** is an innovative, peer-to-peer Docker management application inspired by [Portainer](https://www.portainer.io/).
|
||||
|
||||
Portainer offers various options for connecting to Docker environments, including **Agent**, **Socket**, and **REST API Endpoints**, catering to a wide range of use cases. However, deploying Portainer in large networks where exposing management software is a security concern can be challenging. Exposing management interfaces increases the attack surface and may not comply with organizational security policies.
|
||||
|
||||
Peardock addresses these challenges by leveraging peer-to-peer (P2P) networking to securely manage Docker containers without exposing any management software to the network. By using P2P connections, Peardock ensures that communication between the client and the agent is direct, encrypted, and confined to authenticated peers, enhancing security and efficiency.
|
||||
|
||||
This post provides an in-depth analysis of Peardock's design, backend architecture, custom message protocol, and the code that powers the entire application.
|
||||
|
||||
|
||||
|
||||
|
||||
# Source: https://git.ssh.surf/snxraven/Peardock
|
||||
|
||||
## Concept and Motivation
|
||||
|
||||
Portainer revolutionized the container industry by providing an easy-to-use interface for managing Docker containers. It offers amazing choices for connecting to Docker environments through **Agent**, **Socket**, and **REST API Endpoints**, making it versatile for various deployment scenarios.
|
||||
|
||||
However, in large networks where security is paramount, deploying Portainer may not be the most secure option. Exposing management software or APIs can introduce vulnerabilities, and in environments where you do not want to expose any management interfaces, this becomes a critical issue. The risk of unauthorized access, interception, or exploitation increases with exposed endpoints.
|
||||
|
||||
**Peardock** aims to bring similar functionalities to a peer-to-peer network, eliminating the need to expose any management endpoints. By providing a peer-to-peer client that communicates with its agent solely via a P2P network connection, Peardock enhances security by:
|
||||
|
||||
- **Not Exposing Management Software**: No open ports or endpoints are required, reducing the attack surface.
|
||||
- **Encrypted Communication**: All data transmitted over the P2P network is encrypted using secure protocols.
|
||||
- **Direct Peer-to-Peer Connections**: Communication occurs directly between authenticated peers without intermediaries.
|
||||
- **Decentralization**: Eliminates the need for centralized servers, mitigating single points of failure and potential targets for attacks.
|
||||
|
||||
By using peer-to-peer connections, users can manage Docker containers on remote hosts securely and efficiently. Peardock is designed for environments where security and privacy are critical, such as large enterprise networks, sensitive infrastructures, or situations where network exposure must be minimized.
|
||||
|
||||
## Architecture Overview
|
||||
|
||||
### Frontend
|
||||
|
||||
The frontend is a web application built with HTML, CSS, and JavaScript.
|
||||
|
||||
It uses:
|
||||
|
||||
- **Bootstrap** for responsive UI components.
|
||||
- **Xterm.js** for terminal emulation within the browser.
|
||||
- **Hyperswarm** for peer-to-peer communication.
|
||||
- **Browser APIs** for storage and event handling.
|
||||
|
||||
### Backend
|
||||
|
||||
The backend is a Node.js application that runs on each container host node:
|
||||
|
||||
- **Hyperswarm** is used to establish peer-to-peer connections.
|
||||
- **Dockerode** interacts with the Docker Engine API.
|
||||
- **Custom message protocol** facilitates command and response exchanges between peers.
|
||||
|
||||
## Peer-to-Peer Communication with Hyperswarm
|
||||
|
||||
[Hyperswarm](https://docs.pears.com/building-blocks/hyperswarm) is a networking stack that simplifies peer-to-peer connections using distributed hash tables (DHT).
|
||||
|
||||
In Peardock:
|
||||
|
||||
- Each peer joins a swarm identified by a unique **topic** (a cryptographic key).
|
||||
- Peers discover each other by announcing and looking up this topic in the DHT.
|
||||
- Once connected, peers communicate directly over encrypted channels.
|
||||
|
||||
This architecture ensures:
|
||||
|
||||
- **Decentralization**: No central server is required.
|
||||
- **Scalability**: Peers can join or leave without affecting the network.
|
||||
- **Security**: Communications are encrypted and confined to authenticated peers.
|
||||
|
||||
## Docker Interaction Using Dockerode
|
||||
|
||||
[Dockerode](https://github.com/apocas/dockerode) is a Node.js library for Docker's Remote API.
|
||||
|
||||
It allows:
|
||||
|
||||
- Managing containers (list, start, stop, remove).
|
||||
- Executing commands inside containers.
|
||||
- Streaming logs and stats.
|
||||
|
||||
In Peardock's backend (`server.js`):
|
||||
|
||||
- Dockerode interfaces with the local Docker daemon.
|
||||
- Commands received from peers are executed, and responses are sent back securely.
|
||||
|
||||
## Custom Message Protocol
|
||||
|
||||
Peardock uses a JSON-based custom message protocol over Hyperswarm connections.
|
||||
|
||||
### Command Structure
|
||||
|
||||
Every command sent from the client to the server has the following structure:
|
||||
|
||||
```json
|
||||
{
|
||||
"command": "commandName",
|
||||
"args": {
|
||||
"key1": "value1",
|
||||
"key2": "value2"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
- **command**: Specifies the action (e.g., `listContainers`, `startContainer`).
|
||||
- **args**: An object containing necessary parameters.
|
||||
|
||||
### Response Structure
|
||||
|
||||
Responses from the server follow this structure:
|
||||
|
||||
```json
|
||||
{
|
||||
"type": "responseType",
|
||||
"data": {
|
||||
"key1": "value1",
|
||||
"key2": "value2"
|
||||
},
|
||||
"success": true,
|
||||
"message": "Optional message",
|
||||
"error": "Optional error message"
|
||||
}
|
||||
```
|
||||
|
||||
- **type**: Indicates the type of response (e.g., `containers`, `terminalOutput`).
|
||||
- **data**: Contains the payload.
|
||||
- **success**: A boolean indicating the success of the operation.
|
||||
- **message**: Informational message.
|
||||
- **error**: Error message if the operation failed.
|
||||
|
||||
## Code Breakdown
|
||||
|
||||
### Frontend Components
|
||||
|
||||
#### Index.html
|
||||
|
||||
The main HTML file sets up the application's structure:
|
||||
|
||||
- **Title Bar**: A draggable region for desktop applications.
|
||||
- **Sidebar**: Manages connections to different peers.
|
||||
- **Content Area**: Displays the dashboard or welcome page.
|
||||
- **Modals**: For actions like duplicating containers, viewing logs, and deploying templates.
|
||||
- **Terminal Modal**: An embedded terminal using Xterm.js.
|
||||
- **Alert Container**: Displays notifications to the user.
|
||||
|
||||
**Key Sections:**
|
||||
|
||||
```html
|
||||
<!-- Connection List -->
|
||||
<ul id="connection-list" class="list-group mb-3"></ul>
|
||||
|
||||
<!-- Container List -->
|
||||
<tbody id="container-list"></tbody>
|
||||
|
||||
<!-- Terminal Modal -->
|
||||
<div id="terminal-modal">
|
||||
<!-- Terminal Content -->
|
||||
<div id="terminal-container"></div>
|
||||
</div>
|
||||
```
|
||||
|
||||
#### App.js
|
||||
|
||||
The primary JavaScript file responsible for:
|
||||
|
||||
- Managing connections.
|
||||
- Handling user interactions.
|
||||
- Communicating with the backend.
|
||||
- Rendering container lists and stats.
|
||||
|
||||
**Highlights:**
|
||||
|
||||
- **Connection Management**: Allows users to add and remove peer connections.
|
||||
- **Command Sending**: Sends JSON commands over Hyperswarm to the backend.
|
||||
- **Container Rendering**: Updates the UI with container information.
|
||||
- **Event Handling**: Responds to user actions like starting/stopping containers.
|
||||
|
||||
**Sample Function:**
|
||||
|
||||
```javascript
|
||||
function sendCommand(command, args = {}) {
|
||||
if (window.activePeer) {
|
||||
const message = JSON.stringify({ command, args });
|
||||
window.activePeer.write(message);
|
||||
} else {
|
||||
console.error('[ERROR] No active peer to send command.');
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### Terminal.js
|
||||
|
||||
Handles terminal sessions within the application:
|
||||
|
||||
- Uses **Xterm.js** to create terminal emulators.
|
||||
- Manages multiple terminal sessions.
|
||||
- Sends user input to the backend and displays output.
|
||||
|
||||
**Key Features:**
|
||||
|
||||
- **Session Management**: Tracks terminal sessions per container.
|
||||
- **Data Handling**: Encodes and decodes data for transmission.
|
||||
- **UI Integration**: Displays terminals in modals.
|
||||
|
||||
#### TemplateDeploy.js
|
||||
|
||||
Manages the deployment of containers using templates:
|
||||
|
||||
- Fetches templates from a remote source.
|
||||
- Allows users to search and select templates.
|
||||
- Sends deployment commands to the backend.
|
||||
|
||||
**Implementation Details:**
|
||||
|
||||
- **Template Fetching**: Uses `fetch` API to retrieve templates.
|
||||
- **Dynamic Form Generation**: Builds forms based on template parameters.
|
||||
- **Deployment Handling**: Validates inputs and sends commands.
|
||||
|
||||
#### DockerTerminal.js
|
||||
|
||||
Provides a Docker CLI terminal:
|
||||
|
||||
- Allows executing Docker commands on the remote peer.
|
||||
- Handles input/output with the backend.
|
||||
- Ensures security by sanitizing commands.
|
||||
|
||||
**Functionality:**
|
||||
|
||||
- **Command Prepending**: Ensures all commands start with `docker`.
|
||||
- **Input Buffering**: Manages user input before sending.
|
||||
- **Response Handling**: Decodes and displays output from the backend.
|
||||
|
||||
### Backend Components
|
||||
|
||||
#### Server.js
|
||||
|
||||
The Node.js backend that interacts with Docker and handles peer connections.
|
||||
|
||||
**Core Responsibilities:**
|
||||
|
||||
- **Hyperswarm Server**: Listens for incoming connections.
|
||||
- **Docker Management**: Uses Dockerode to control Docker.
|
||||
- **Command Handling**: Processes commands received from peers.
|
||||
- **Terminal Sessions**: Manages interactive sessions inside containers.
|
||||
- **Event Broadcasting**: Sends updates to all connected peers.
|
||||
|
||||
**Key Sections:**
|
||||
|
||||
- **Peer Connection Handling:**
|
||||
|
||||
```javascript
|
||||
swarm.on('connection', (peer) => {
|
||||
connectedPeers.add(peer);
|
||||
|
||||
peer.on('data', async (data) => {
|
||||
const parsedData = JSON.parse(data.toString());
|
||||
// Handle commands
|
||||
});
|
||||
|
||||
peer.on('close', () => {
|
||||
connectedPeers.delete(peer);
|
||||
// Clean up sessions
|
||||
});
|
||||
});
|
||||
```
|
||||
|
||||
- **Command Processing:**
|
||||
|
||||
```javascript
|
||||
switch (parsedData.command) {
|
||||
case 'listContainers':
|
||||
// List and send container data
|
||||
break;
|
||||
case 'startContainer':
|
||||
// Start specified container
|
||||
break;
|
||||
// Additional cases...
|
||||
}
|
||||
```
|
||||
|
||||
- **Terminal Handling:**
|
||||
|
||||
```javascript
|
||||
async function handleTerminal(containerId, peer) {
|
||||
const container = docker.getContainer(containerId);
|
||||
const exec = await container.exec({ /* ... */ });
|
||||
const stream = await exec.start({ hijack: true, stdin: true });
|
||||
// Handle input/output
|
||||
}
|
||||
```
|
||||
|
||||
## Features and Implementation Details
|
||||
|
||||
### Connection Management
|
||||
|
||||
- **Adding Connections**: Users can add new peers by entering a topic key.
|
||||
- **Persistent Storage**: Connections are saved in cookies for session persistence.
|
||||
- **Sidebar Interaction**: The UI allows switching between different peer connections.
|
||||
|
||||
**Code Snippet:**
|
||||
|
||||
```javascript
|
||||
function addConnection(topicHex) {
|
||||
const topic = b4a.from(topicHex, 'hex');
|
||||
const topicId = topicHex.substring(0, 12);
|
||||
connections[topicId] = { topic, peer: null, swarm: null, topicHex };
|
||||
// UI updates and event listeners
|
||||
}
|
||||
```
|
||||
|
||||
### Container Management
|
||||
|
||||
- **Listing Containers**: Retrieves a list of Docker containers from the peer.
|
||||
- **Starting/Stopping Containers**: Sends commands to control container states.
|
||||
- **Removing Containers**: Allows deletion of containers on the peer.
|
||||
|
||||
**Implementation:**
|
||||
|
||||
- Uses commands like `listContainers`, `startContainer`, etc.
|
||||
- Handles responses to update the UI accordingly.
|
||||
- Provides user feedback through alerts and status indicators.
|
||||
|
||||
### Terminal Sessions
|
||||
|
||||
- **Interactive Terminals**: Users can open terminals to interact with containers.
|
||||
- **Multiple Sessions**: Supports multiple terminal sessions simultaneously.
|
||||
- **Data Streaming**: Streams input/output between the client and the container.
|
||||
|
||||
**Backend Handling:**
|
||||
|
||||
```javascript
|
||||
async function handleTerminal(containerId, peer) {
|
||||
const container = docker.getContainer(containerId);
|
||||
const exec = await container.exec({ /* ... */ });
|
||||
const stream = await exec.start({ hijack: true, stdin: true });
|
||||
// Stream data between peer and container
|
||||
}
|
||||
```
|
||||
|
||||
### Template Deployment
|
||||
|
||||
- **Template Source**: Fetches application templates from a GitHub repository.
|
||||
- **Dynamic Forms**: Generates forms based on template parameters.
|
||||
- **Deployment Process**: Validates inputs and sends deployment commands.
|
||||
|
||||
**Frontend Workflow:**
|
||||
|
||||
1. Fetch templates using `fetchTemplates()`.
|
||||
2. Display templates in a searchable list.
|
||||
3. On selection, populate the deployment form.
|
||||
4. Handle form submission and send `deployContainer` command.
|
||||
|
||||
**Backend Deployment:**
|
||||
|
||||
```javascript
|
||||
case 'deployContainer':
|
||||
// Validate and sanitize inputs
|
||||
// Pull Docker image
|
||||
// Create and start the container
|
||||
// Send success or error response
|
||||
break;
|
||||
```
|
||||
|
||||
## Final Thoughts
|
||||
|
||||
Peardock brings a novel approach to Docker container management by harnessing peer-to-peer networks. By eliminating the need to expose any management software or endpoints, it offers a secure, decentralized, and efficient way to manage containers across different hosts.
|
||||
|
||||
The combination of Hyperswarm for networking and Dockerode for container management provides a robust backend. The custom message protocol ensures structured and efficient communication between peers, confined to authenticated connections.
|
||||
|
||||
The frontend offers a user-friendly interface with advanced functionalities like terminal access and template deployment. The modular codebase allows for easy maintenance and extension.
|
||||
|
||||
**Future Enhancements:**
|
||||
|
||||
- **Authentication and Access Control**: Implementing robust authentication mechanisms and access controls for secure peer connections.
|
||||
- **Advanced Monitoring**: Integrating detailed monitoring and alerting features for container health and performance.
|
||||
- **Plugin System**: Allowing third-party plugins to extend functionalities and adapt to specific needs.
|
||||
- **Mobile Support**: Optimizing the UI for mobile devices to manage containers on the go.
|
||||
|
||||
Peardock is a testament to the possibilities of decentralized applications and opens new avenues for managing containerized applications in distributed and security-sensitive environments. It combines the best of Portainer's user experience with the security and privacy benefits of peer-to-peer networking.
|
||||
623
markdown/The Bulding Blocks of Peer to Peer.md
Normal file
@ -0,0 +1,623 @@
|
||||
|
||||
<!-- lead -->
|
||||
The Hyper Ecosystem: A Deep Dive into Peer-to-Peer Building Blocks
|
||||
|
||||
In this post, we’re going to explore in great detail the powerful set of libraries that comprise the Hyper ecosystem. Whether you’re building distributed filesystems, real-time collaborative applications, or secure, append-only logs, these libraries offer the tools you need. We’ll cover everything from peer discovery to file replication, and from merging multiple writers’ inputs into a consistent log to providing a high-performance key/value store. This post will take you step-by-step through HyperSwarm, Hyper-DHT, Autobase, Hyperdrive, Hyperbee, and Hypercore, complete with code examples and real-world scenarios.
|
||||
|
||||
|
||||
## HyperSwarm: Peer Discovery and Connection Simplified
|
||||
|
||||
At the forefront of any decentralized application is the ability to find and connect to other peers. HyperSwarm is a high-level API designed to abstract the complexities of peer discovery. It leverages a distributed hash table (DHT) under the hood to let you join a “swarm” of peers that are interested in a specific 32-byte topic.
|
||||
|
||||
### Key Concepts
|
||||
|
||||
- Topics:
|
||||
Every topic must be exactly 32 bytes. They often represent a hashed value of a human-readable string.
|
||||
- Client and Server Modes:
|
||||
- Server Mode: Announce your presence on the DHT and accept incoming connections.
|
||||
- Client Mode: Actively search for peers that are announcing a particular topic and establish outgoing connections.
|
||||
|
||||
### Getting Started
|
||||
|
||||
Install HyperSwarm using npm:
|
||||
|
||||
```bash
|
||||
npm install hyperswarm
|
||||
```
|
||||
|
||||
Below is an example that demonstrates both client and server behavior:
|
||||
|
||||
```javascript
|
||||
const Hyperswarm = require('hyperswarm')
|
||||
|
||||
// Create two separate swarm instances
|
||||
const serverSwarm = new Hyperswarm()
|
||||
const clientSwarm = new Hyperswarm()
|
||||
|
||||
// Server: Listen for incoming connections on a topic
|
||||
serverSwarm.on('connection', (socket, info) => {
|
||||
console.log('Server: Connection established with', info.peer)
|
||||
socket.write('Hello from the server!')
|
||||
socket.end()
|
||||
})
|
||||
|
||||
// Client: Handle data received from the server
|
||||
clientSwarm.on('connection', (socket, info) => {
|
||||
socket.on('data', data => {
|
||||
console.log('Client: Received message:', data.toString())
|
||||
})
|
||||
})
|
||||
|
||||
// Define a 32-byte topic (here, a simple repeated string)
|
||||
const topic = Buffer.alloc(32, 'hello world')
|
||||
|
||||
// Server announces itself on the topic (server mode)
|
||||
const serverDiscovery = serverSwarm.join(topic, { server: true, client: false })
|
||||
await serverDiscovery.flushed() // Wait until fully announced
|
||||
|
||||
// Client searches for servers (client mode)
|
||||
clientSwarm.join(topic, { server: false, client: true })
|
||||
await clientSwarm.flush() // Wait until all connections are established
|
||||
```
|
||||
|
||||
### Advanced Features
|
||||
|
||||
- PeerDiscovery Object:
|
||||
The object returned by `swarm.join()` gives you control over the announcement or lookup lifecycle. Methods like `flushed()`, `refresh()`, and `destroy()` allow you to monitor or change discovery behavior on the fly.
|
||||
|
||||
- Direct Peer Connection:
|
||||
Use `swarm.joinPeer(noisePublicKey)` to establish a direct connection to a known peer. This is useful if you already have a peer’s public key and want to bypass the DHT lookup.
|
||||
|
||||
- Events and Metadata:
|
||||
Every connection event comes with a `PeerInfo` object, which includes details such as the peer’s Noise public key and the topics they are associated with. This information can be used to build custom user interfaces or manage reconnection strategies.
|
||||
|
||||
HyperSwarm makes it straightforward to integrate robust peer discovery into your P2P applications with minimal overhead.
|
||||
|
||||
|
||||
|
||||
## Hyper-DHT: The Low-Level Networking Backbone
|
||||
|
||||
Beneath HyperSwarm lies Hyper-DHT, the distributed hash table that enables decentralized peer discovery and connection. Hyper-DHT is built on top of [dht-rpc](https://github.com/mafintosh/dht-rpc) and uses a series of hole-punching techniques to connect peers even across restrictive NATs and firewalls.
|
||||
|
||||
### Core Features
|
||||
|
||||
- Public Key Identification:
|
||||
Unlike traditional DHTs that rely on IP addresses, Hyper-DHT identifies peers using public keys. This makes it easy to connect to peers regardless of network changes.
|
||||
|
||||
- Direct P2P Connections:
|
||||
You can both create P2P servers and initiate connections to remote servers using direct public keys.
|
||||
|
||||
### Setting Up a Hyper-DHT Node
|
||||
|
||||
Install Hyper-DHT via npm:
|
||||
|
||||
```bash
|
||||
npm install hyperdht
|
||||
```
|
||||
|
||||
Below is a simple example that creates a new DHT node and demonstrates bootstrapping:
|
||||
|
||||
```javascript
|
||||
const DHT = require('hyperdht')
|
||||
|
||||
// Create a DHT node with default bootstrap servers
|
||||
const node = new DHT()
|
||||
|
||||
// Generate a key pair for the node (or use an existing one)
|
||||
const keyPair = DHT.keyPair()
|
||||
|
||||
console.log('DHT node created with public key:', keyPair.publicKey.toString('hex'))
|
||||
```
|
||||
|
||||
### Creating and Managing P2P Servers
|
||||
|
||||
Hyper-DHT provides methods to create P2P servers that accept encrypted connections using the Noise protocol as well as libsodium.
|
||||
|
||||
```javascript
|
||||
// Create a server that accepts encrypted connections
|
||||
const server = node.createServer({
|
||||
firewall: (remotePublicKey, remoteHandshakePayload) => {
|
||||
// Here you can validate incoming connections
|
||||
// Return false to accept, true to reject
|
||||
return false
|
||||
}
|
||||
})
|
||||
|
||||
// Start listening on a key pair
|
||||
await server.listen(keyPair)
|
||||
console.log('Server is listening on:', server.address())
|
||||
|
||||
// Handle incoming connections
|
||||
server.on('connection', (socket) => {
|
||||
console.log('New connection from', socket.remotePublicKey.toString('hex'))
|
||||
})
|
||||
```
|
||||
|
||||
### Peer Discovery and Announcements
|
||||
|
||||
Hyper-DHT offers additional APIs for peer discovery:
|
||||
|
||||
- Lookup:
|
||||
```javascript
|
||||
const lookupStream = node.lookup(topic)
|
||||
lookupStream.on('data', (data) => {
|
||||
console.log('Lookup response:', data)
|
||||
})
|
||||
```
|
||||
|
||||
- Announce:
|
||||
Announce that you’re listening on a particular topic. This is especially useful for servers.
|
||||
|
||||
```javascript
|
||||
const announceStream = node.announce(topic, keyPair)
|
||||
// The stream returns details about nearby nodes
|
||||
announceStream.on('data', (data) => {
|
||||
console.log('Announced to:', data)
|
||||
})
|
||||
```
|
||||
|
||||
- Mutable/Immutable Records:
|
||||
Store and retrieve records in the DHT with methods such as `node.immutablePut()` and `node.mutableGet()`. This is useful for decentralized record storage.
|
||||
|
||||
Hyper-DHT provides the low-level connectivity and data exchange mechanisms that are essential for building robust P2P networks.
|
||||
|
||||
|
||||
|
||||
## Autobase: Merging Multiple Data Streams into One Linear Log
|
||||
|
||||
Autobase is an experimental module designed to automatically rebase multiple causally-linked Hypercores into a single, linearized Hypercore. This functionality is crucial for collaborative applications where multiple writers need to merge their changes into a consistent view.
|
||||
|
||||
### Why Autobase?
|
||||
|
||||
Imagine a multi-user chat application where each user has their own log of messages. Without a central coordinator, reconciling these different logs into a single, chronological order is challenging. Autobase solves this problem by:
|
||||
|
||||
- Automatically Rebasing Inputs:
|
||||
It takes several input Hypercores and computes a deterministic, causal ordering over all the entries.
|
||||
|
||||
- Producing a Linearized View:
|
||||
The output is a Hypercore-like log that represents a merged view, which can be used by higher-level data structures such as Hyperbee or Hyperdrive.
|
||||
|
||||
- Low-Friction Integration:
|
||||
Autobase’s output adheres to the Hypercore API, so you can plug it into your existing pipelines with minimal changes.
|
||||
|
||||
### Working with Autobase
|
||||
|
||||
Install Autobase with npm:
|
||||
|
||||
```bash
|
||||
npm install autobase
|
||||
```
|
||||
|
||||
Here’s an example demonstrating basic usage:
|
||||
|
||||
```javascript
|
||||
const Autobase = require('autobase')
|
||||
|
||||
// Assume we have multiple input Hypercores (inputCore1, inputCore2)
|
||||
const base = new Autobase({
|
||||
inputs: [inputCore1, inputCore2],
|
||||
localInput: localCore, // Use this core for local appends
|
||||
autostart: true // Automatically create the linearized view
|
||||
})
|
||||
|
||||
// Append a new entry (Autobase automatically embeds a causal clock)
|
||||
await base.append('Hello from user A')
|
||||
|
||||
// Create a causal stream to view the deterministic ordering of entries
|
||||
const causalStream = base.createCausalStream()
|
||||
causalStream.on('data', node => {
|
||||
console.log('Linearized node:', node)
|
||||
})
|
||||
```
|
||||
|
||||
### Customizing the Linearized View
|
||||
|
||||
Autobase allows you to customize how the merged log is processed by providing an `apply` function. This function can transform or filter the batch of nodes before they are appended to the output view.
|
||||
|
||||
```javascript
|
||||
base.start({
|
||||
async apply(batch) {
|
||||
// For example, uppercase all string messages before storing
|
||||
const transformed = batch.map(({ value }) =>
|
||||
Buffer.from(value.toString('utf-8').toUpperCase())
|
||||
)
|
||||
await base.view.append(transformed)
|
||||
}
|
||||
})
|
||||
```
|
||||
|
||||
With Autobase, you gain the flexibility to support multi-user collaborative workflows without having to build complex conflict resolution mechanisms from scratch.
|
||||
|
||||
|
||||
|
||||
## Hyperdrive: A Distributed, Real-Time Filesystem
|
||||
|
||||
Hyperdrive is a secure, real-time distributed filesystem that simplifies P2P file sharing. It’s built on top of Hypercore and Hyperbee and is used in projects like Holepunch and distributed web applications.
|
||||
|
||||
### The Core Idea
|
||||
|
||||
Hyperdrive abstracts away the complexity of distributed file storage and allows you to work with files and directories just like in a traditional filesystem. It uses Hyperbee for file metadata (such as file hierarchies, permissions, and timestamps) and Hypercore to replicate the actual file data (blobs).
|
||||
|
||||
### Setting Up a Hyperdrive
|
||||
|
||||
Install Hyperdrive along with a storage backend like Corestore:
|
||||
|
||||
```bash
|
||||
npm install hyperdrive corestore
|
||||
```
|
||||
|
||||
Below is a simple example using an in-memory store (for demonstration):
|
||||
|
||||
```javascript
|
||||
const Hyperdrive = require('hyperdrive')
|
||||
const Corestore = require('corestore')
|
||||
const ram = require('random-access-memory')
|
||||
|
||||
// Initialize a corestore using in-memory storage
|
||||
const store = new Corestore(ram)
|
||||
await store.ready()
|
||||
|
||||
// Create a new Hyperdrive instance
|
||||
const drive = new Hyperdrive(store)
|
||||
await drive.ready()
|
||||
|
||||
console.log('Hyperdrive ID:', drive.id)
|
||||
```
|
||||
|
||||
### File Operations
|
||||
|
||||
Hyperdrive provides a rich set of file operations similar to traditional filesystems:
|
||||
|
||||
- Writing Files:
|
||||
```javascript
|
||||
await drive.put('/hello.txt', Buffer.from('Hello, Hyperdrive!'))
|
||||
```
|
||||
|
||||
- Reading Files:
|
||||
```javascript
|
||||
const fileBuffer = await drive.get('/hello.txt')
|
||||
console.log('File content:', fileBuffer.toString('utf-8'))
|
||||
```
|
||||
|
||||
- Deleting and Updating Files:
|
||||
```javascript
|
||||
await drive.del('/hello.txt')
|
||||
```
|
||||
|
||||
- Directory Listing and Batch Operations:
|
||||
You can list directory entries, watch folders for changes, and even perform atomic batch updates.
|
||||
|
||||
### Replication and Networking
|
||||
|
||||
Hyperdrive integrates seamlessly with HyperSwarm and Hyper-DHT to replicate data between peers:
|
||||
|
||||
```javascript
|
||||
const Hyperswarm = require('hyperswarm')
|
||||
const swarm = new Hyperswarm()
|
||||
|
||||
swarm.on('connection', (socket) => {
|
||||
// Replicate the drive over the incoming connection
|
||||
drive.replicate(socket)
|
||||
})
|
||||
|
||||
// Use the drive's discovery key to join the swarm
|
||||
swarm.join(drive.discoveryKey)
|
||||
swarm.flush().then(() => {
|
||||
console.log('Hyperdrive replication is active')
|
||||
})
|
||||
```
|
||||
|
||||
Hyperdrive also includes tools like localdrive and mirrordrive to facilitate importing/exporting files between distributed and local environments.
|
||||
|
||||
|
||||
|
||||
## Hyperbee: The Append-Only B-Tree for Key/Value Storage
|
||||
|
||||
Hyperbee transforms the basic append-only log of Hypercore into a high-level, sorted key/value store. It is especially useful when you need a database-like interface with features such as atomic batch updates, sorted iterators, and efficient diffing between versions.
|
||||
|
||||
### Core Concepts
|
||||
|
||||
- Append-Only B-Tree:
|
||||
Data is stored in a structure that allows for sorted key iteration. New changes are appended, ensuring that the history of modifications is preserved.
|
||||
|
||||
- Encoding Options:
|
||||
Hyperbee supports customizable `keyEncoding` and `valueEncoding` (e.g., `'utf-8'`, `'json'`, or `'binary'`).
|
||||
|
||||
### Creating a Hyperbee Instance
|
||||
|
||||
Assuming you already have a Hypercore (possibly from Hyperdrive), you can create a Hyperbee:
|
||||
|
||||
```javascript
|
||||
const Hyperbee = require('hyperbee')
|
||||
|
||||
// Use an existing Hypercore instance for storage
|
||||
const db = new Hyperbee(drive.core, {
|
||||
keyEncoding: 'utf-8',
|
||||
valueEncoding: 'json'
|
||||
})
|
||||
|
||||
await db.ready()
|
||||
|
||||
// Put a key/value pair
|
||||
await db.put('greeting', { message: 'Hello, Hyperbee!' })
|
||||
|
||||
// Retrieve the stored value
|
||||
const { value } = await db.get('greeting')
|
||||
console.log('Retrieved from Hyperbee:', value)
|
||||
```
|
||||
|
||||
### Advanced Operations
|
||||
|
||||
- Batch Writes:
|
||||
Hyperbee allows you to perform atomic batch operations for improved performance:
|
||||
|
||||
```javascript
|
||||
const batch = db.batch()
|
||||
await batch.put('foo', 'bar')
|
||||
await batch.put('lorem', 'ipsum')
|
||||
await batch.flush()
|
||||
```
|
||||
|
||||
- Diff and History Streams:
|
||||
You can generate streams that show the history of changes or compute diffs between versions:
|
||||
|
||||
```javascript
|
||||
// Create a history stream to see all modifications
|
||||
const historyStream = db.createHistoryStream({ live: false })
|
||||
historyStream.on('data', (entry) => {
|
||||
console.log('History entry:', entry)
|
||||
})
|
||||
|
||||
// Generate a diff stream between two versions
|
||||
const diffStream = db.createDiffStream(previousVersion, { reverse: false })
|
||||
diffStream.on('data', diff => {
|
||||
console.log('Difference:', diff)
|
||||
})
|
||||
```
|
||||
|
||||
Hyperbee’s rich API makes it a great choice for building decentralized databases that require both performance and a clear history of changes.
|
||||
|
||||
|
||||
|
||||
## Hypercore: The Foundational Append-Only Log
|
||||
|
||||
At the heart of the entire ecosystem lies Hypercore. It is a secure, distributed append-only log that forms the basis for all higher-level data structures. Hypercore is designed for performance and security, making it ideal for real-time data streaming and replication.
|
||||
|
||||
### Understanding Hypercore
|
||||
|
||||
- Append-Only Log:
|
||||
Hypercore only allows data to be appended. Once written, data cannot be altered, ensuring an immutable history.
|
||||
|
||||
- Security and Integrity:
|
||||
Every block is cryptographically signed, and the log uses a Merkle tree for data verification. The use of a private key (that should remain on a single machine) guarantees that only the creator can modify the log.
|
||||
|
||||
- Replication:
|
||||
Hypercore includes robust replication capabilities, enabling peers to synchronize data over insecure networks using encrypted channels.
|
||||
|
||||
### Basic API Usage
|
||||
|
||||
Install Hypercore via npm:
|
||||
|
||||
```bash
|
||||
npm install hypercore
|
||||
```
|
||||
|
||||
Create a new Hypercore instance using an in-memory storage backend (for demo purposes):
|
||||
|
||||
```javascript
|
||||
const Hypercore = require('hypercore')
|
||||
const ram = require('random-access-memory')
|
||||
|
||||
const core = new Hypercore(ram, { valueEncoding: 'utf-8' })
|
||||
await core.ready()
|
||||
|
||||
// Append data to the log
|
||||
await core.append('This is the first block')
|
||||
await core.append('Here is the second block')
|
||||
console.log('Current core length:', core.length)
|
||||
```
|
||||
|
||||
### Advanced Operations
|
||||
|
||||
- Reading Data:
|
||||
You can read blocks individually or stream them:
|
||||
|
||||
```javascript
|
||||
// Get a specific block by index
|
||||
const block = await core.get(0)
|
||||
console.log('Block 0:', block)
|
||||
|
||||
// Create a read stream to iterate through all blocks
|
||||
const readStream = core.createReadStream()
|
||||
readStream.on('data', data => {
|
||||
console.log('Streamed block:', data)
|
||||
})
|
||||
```
|
||||
|
||||
- Replication:
|
||||
Replication can be done over any transport. For example, using a TCP connection:
|
||||
|
||||
```javascript
|
||||
// On the server side:
|
||||
const net = require('net')
|
||||
const server = net.createServer(socket => {
|
||||
socket.pipe(core.replicate(false)).pipe(socket)
|
||||
})
|
||||
server.listen(8000)
|
||||
|
||||
// On the client side:
|
||||
const clientSocket = net.connect(8000)
|
||||
clientSocket.pipe(core.replicate(true)).pipe(clientSocket)
|
||||
```
|
||||
|
||||
- Sessions and Snapshots:
|
||||
Sessions allow you to create lightweight clones of a Hypercore, and snapshots provide a consistent, read-only view:
|
||||
|
||||
```javascript
|
||||
const session = core.session()
|
||||
const snapshot = core.snapshot()
|
||||
// Use session and snapshot as independent Hypercore instances
|
||||
```
|
||||
|
||||
- Truncation and Forking:
|
||||
Hypercore supports truncating the log and intentionally forking the core using the `truncate()` method. This is particularly useful for applications that require resetting or pruning data.
|
||||
|
||||
```javascript
|
||||
// Truncate the core to a new length (and optionally set a fork ID)
|
||||
await core.truncate(1)
|
||||
console.log('Core length after truncation:', core.length)
|
||||
```
|
||||
|
||||
- Merkle Tree Hashing and Clearing Blocks:
|
||||
For verifying data integrity, you can compute the Merkle tree hash or clear stored blocks to reclaim space:
|
||||
|
||||
```javascript
|
||||
const treeHash = await core.treeHash()
|
||||
console.log('Merkle tree hash:', treeHash.toString('hex'))
|
||||
|
||||
// Clear a block from local storage
|
||||
await core.clear(0)
|
||||
```
|
||||
|
||||
Hypercore’s robust API and design make it the cornerstone of a secure, decentralized data ecosystem.
|
||||
|
||||
## HyperDB: Database Built for P2P and Local Indexing
|
||||
|
||||
HyperDB is a versatile database engine designed to serve both peer-to-peer applications and local indexing needs. Whether you’re looking to build a distributed, collaborative data store using Hyperbee or need a fast, local-only database backed by RocksDB, HyperDB provides a unified, high-level API that makes it easy to work with structured data.
|
||||
|
||||
### Installation
|
||||
|
||||
Install HyperDB via npm:
|
||||
|
||||
```bash
|
||||
npm install hyperdb
|
||||
```
|
||||
|
||||
### Usage
|
||||
|
||||
Before you start, generate your database definition using the builder. This definition specifies the schemas and collections you want to work with. (For now, see the example in the `./example` directory.)
|
||||
|
||||
You can then boot your database using the same definition for both fully P2P and local-only scenarios:
|
||||
|
||||
```javascript
|
||||
const HyperDB = require('hyperdb')
|
||||
|
||||
// Choose your engine:
|
||||
// For a local-only database backed by RocksDB:
|
||||
const db = HyperDB.rocks('./my-rocks.db', require('./my-definition'))
|
||||
|
||||
// Alternatively, for a P2P database backed by Hyperbee:
|
||||
// const db = HyperDB.bee(hypercore, require('./my-definition'), [options])
|
||||
|
||||
console.log('Database initialized!')
|
||||
```
|
||||
|
||||
It’s that simple.
|
||||
|
||||
### API Overview
|
||||
|
||||
HyperDB exposes a rich set of methods to query, update, and manage your data:
|
||||
|
||||
- **Database Creation**
|
||||
- `db = Hyperdb.bee(hypercore, definition, [options])`
|
||||
Create a P2P database powered by Hyperbee.
|
||||
- `db = Hyperdb.rocks(path, definition, [options])`
|
||||
Create a local-only database backed by RocksDB.
|
||||
|
||||
- **Querying**
|
||||
- **Find Documents:**
|
||||
```javascript
|
||||
const queryStream = db.find(collectionOrIndex, query, [options])
|
||||
```
|
||||
The `query` object follows this pattern:
|
||||
```js
|
||||
{
|
||||
gt: { /* lower bound (exclusive) */ },
|
||||
gte: { /* lower bound (inclusive) */ },
|
||||
lt: { /* upper bound (exclusive) */ },
|
||||
lte: { /* upper bound (inclusive) */ }
|
||||
}
|
||||
```
|
||||
And `options` may include:
|
||||
```js
|
||||
{
|
||||
limit, // maximum number of results
|
||||
reverse // whether to stream in reverse order
|
||||
}
|
||||
```
|
||||
*Note:* The query operates on a snapshot—any inserts or deletes made while the query stream is active will not affect the current results.
|
||||
|
||||
- **Stream Helpers:**
|
||||
- `all = await queryStream.toArray()` — collect all entries.
|
||||
- `one = await queryStream.one()` — retrieve the last entry.
|
||||
|
||||
- **Convenience Methods:**
|
||||
- `doc = await db.findOne(collectionOrIndex, query, [options])`
|
||||
*Alias for:* `await queryStream.one()`
|
||||
- `doc = await db.get(collection, query)`
|
||||
Get a single document from a collection.
|
||||
- `{ count } = await db.stats(collectionOrIndex)`
|
||||
Get statistics for a collection or index.
|
||||
|
||||
- **Modifying the Database**
|
||||
- **Inserting and Deleting:**
|
||||
```javascript
|
||||
await db.insert(collection, doc)
|
||||
await db.delete(collection, query)
|
||||
```
|
||||
*Note:* You need to call `await db.flush()` later to persist these changes.
|
||||
|
||||
- **Checking for Updates:**
|
||||
```javascript
|
||||
const updated = db.updated([collection], [query])
|
||||
```
|
||||
Returns a boolean indicating whether the database (or a specific record) has been updated.
|
||||
|
||||
- **Snapshot and Transaction Management**
|
||||
- `await db.flush()` — persist all pending changes.
|
||||
- `db.reload()` — reload the internal snapshot and clear memory state.
|
||||
- `const snapshot = db.snapshot()` — create a read-only snapshot locked in time.
|
||||
- `const txn = db.transaction()` — create a writable snapshot; flushing this snapshot updates the main instance.
|
||||
- `await db.close()` — close the database (remember to close any snapshots you’ve created).
|
||||
|
||||
### Builder API
|
||||
|
||||
The builder API lets you define the structure of your database. Each field in the definition file is an object that specifies its characteristics:
|
||||
|
||||
```javascript
|
||||
{
|
||||
name: 'field-name',
|
||||
type: 'uint', // a compact-encoding type, or a reference to another encoding defined in the builder file
|
||||
required: true, // set to false for optional fields
|
||||
array: false // set to true to store an array of this type
|
||||
}
|
||||
```
|
||||
|
||||
This flexible schema definition allows you to easily declare collections, indices, and relationships tailored to your application’s needs.
|
||||
|
||||
HyperDB’s rich feature set makes it an excellent choice for building robust, scalable databases that work seamlessly in both decentralized and local environments. Experiment with its flexible API to build custom queries, manage snapshots, and implement transactions effortlessly.
|
||||
|
||||
## Integrating the Ecosystem: Real-World Applications
|
||||
|
||||
The true power of the Hyper ecosystem is revealed when you combine these libraries to build real-world applications. Here are a few scenarios:
|
||||
|
||||
- Distributed Collaborative Applications:
|
||||
Use Autobase to merge multiple users’ Hypercores into a single, linearized log. With Hyperbee, index and query the merged log efficiently. Replicate the data using HyperSwarm and Hyper-DHT so that all participants stay in sync.
|
||||
|
||||
- Decentralized Filesystems:
|
||||
Hyperdrive leverages Hyperbee for file metadata and Hypercore for file content. With built-in replication and versioning, you can build a secure, real-time filesystem that works even under unreliable network conditions.
|
||||
|
||||
- Secure Data Streams and Logs:
|
||||
Hypercore provides the secure append-only log that can be used as the backbone for distributed messaging systems or real-time feeds. Its replication and snapshot capabilities allow for both live updates and historical consistency.
|
||||
|
||||
- Peer Discovery and Direct Connections:
|
||||
HyperSwarm and Hyper-DHT handle the complexities of NAT traversal, bootstrapping, and encrypted peer-to-peer connections, letting you focus on building the core logic of your application.
|
||||
|
||||
By understanding and leveraging these components, you can build highly resilient, decentralized applications that perform well at scale and provide a secure, tamper-proof data layer.
|
||||
|
||||
|
||||
|
||||
## What do I think?
|
||||
The Hyper ecosystem offers a modular yet deeply integrated set of tools for building the next generation of peer-to-peer applications. Whether you’re just starting out or looking to build a production-grade decentralized system, these libraries provide robust APIs, extensive customization options, and powerful features—from secure peer discovery with HyperSwarm and Hyper-DHT, to automatic conflict resolution and multi-user collaboration with Autobase, to distributed file sharing with Hyperdrive, and efficient key/value storage and append-only logs with Hyperbee and Hypercore.
|
||||
|
||||
By diving deep into these libraries, you gain the knowledge and flexibility to architect truly decentralized systems that are resilient, secure, and scalable. Experiment with the code examples, explore the API documentation on GitHub, and start building your own applications in this exciting ecosystem.
|
||||
@ -0,0 +1,202 @@
|
||||
<!-- lead -->
|
||||
Tensions between WordPress and WP Engine are raising concerns about the future of WordPress and its open-source values.
|
||||
|
||||
<CENTER><iframe width="50%" height="150" scrolling="no" frameborder="no" allow="" src="https://w.soundcloud.com/player/?url=https%3A//api.soundcloud.com/tracks/1925202203&color=%2310121c&auto_play=true&hide_related=true&show_comments=false&show_user=false&show_reposts=false&show_teaser=false&visual=true"></iframe><div style="font-size: 10px; color: #cccccc;line-break: anywhere;word-break: normal;overflow: hidden;white-space: nowrap;text-overflow: ellipsis; font-family: Interstate,Lucida Grande,Lucida Sans Unicode,Lucida Sans,Garuda,Verdana,Tahoma,sans-serif;font-weight: 100;"><a href="https://soundcloud.com/snxraven" title="snxraven" target="_blank" style="color: #cccccc; text-decoration: none;">snxraven</a> · <a href="https://soundcloud.com/snxraven/open-source-breakdown" title="Open Source Breakdown" target="_blank" style="color: #cccccc; text-decoration: none;">Open Source Breakdown</a></div></CENTER>
|
||||
|
||||
## The Beginning
|
||||
In recent days, the actions of WordPress.org and Automattic have raised serious concerns about the future of the open-source WordPress project and its relationship with developers, hosting providers, and users. While these entities claim to act in the best interests of the community, their recent choices have the potential to backfire, undermining trust, and pushing developers and web hosts to seek alternatives.
|
||||
|
||||
In this article, I will break down my thoughts on why the decisions made by WordPress and Automattic are not only detrimental but may ultimately erode their dominance within the content management system (CMS) space.
|
||||
|
||||
## The False Promise of Open Source
|
||||
WordPress has long been championed as the beacon of open-source software. Its extensive ecosystem, flexibility, and community-driven development have made it one of the most popular CMS platforms globally. However, as Automattic, the company behind WordPress.com and WooCommerce, gains more influence, it appears the open-source spirit is taking a back seat to corporate interests. This shift can have disastrous effects on the community at large.
|
||||
|
||||
Automattic’s insistence on enforcing the WordPress trademark is one example of this. WP Engine, a popular managed hosting provider, has come under fire from Automattic for allegedly misleading users by using "WP" in its name. WordPress.org’s recent updates to its **trademark policy** even go so far as to imply WP Engine is purposefully confusing users into thinking they are officially affiliated with WordPress. This aggressive trademark enforcement sets a dangerous precedent.
|
||||
|
||||
## Alienating Developers and Hosts
|
||||
At its core, WordPress thrives because of the vast network of developers and hosts who build, extend, and support it. Automattic’s growing tendency to view these third-party contributors as competitors is counterproductive and could spell the beginning of an exodus of talent from the platform.
|
||||
|
||||
WP Engine is just one case. Many developers and hosts contribute back to WordPress by creating themes, plugins, and infrastructure that power millions of websites. These contributions are integral to the success of the CMS, yet the heavy-handed approach Automattic is taking suggests they see themselves as the sole proprietors of WordPress. They even went so far as to criticize WP Engine for only contributing **40 hours a week** compared to Automattic’s **3,915 hours**, further intensifying the divide between corporate entities and independent contributors.
|
||||
|
||||
## Cutting Off Access to Resources
|
||||
One of the most troubling developments is WordPress.org’s decision to block WP Engine from accessing core resources on their platform. This move will likely affect WP Engine customers, leaving them without the critical infrastructure that WordPress.org provides. In essence, WordPress is asking WP Engine to replicate its entire infrastructure independently, including updates, security patches, directories, and more. This isn't just a blow to WP Engine—it's a disservice to the broader WordPress community that relies on these hosts.
|
||||
|
||||
Rather than working collaboratively with WP Engine to address concerns, WordPress.org has chosen to cut them off, effectively penalizing their users. These customers, who are already invested in the platform, will likely reconsider their allegiance to WordPress if the services they rely on degrade in quality.
|
||||
|
||||
## The Slippery Slope of Monopolizing Contributions
|
||||
Another major issue is Automattic’s increasing monopolization of contributions to WordPress. With their vast resources, they contribute an overwhelming share of hours to WordPress development. At first glance, this may seem like a positive. However, the imbalance of power means that Automattic is setting the agenda, steering the project to benefit its business model. This reduces the influence of independent developers and contributors and risks stagnating the diversity of ideas that have historically fueled the platform’s growth.
|
||||
|
||||
This shift in dynamics could cause independent developers, who have built their livelihoods around WordPress, to feel sidelined or neglected. If their contributions are increasingly seen as insignificant or undervalued compared to Automattic’s overwhelming presence, they may stop contributing altogether, further consolidating control in the hands of a single entity.
|
||||
|
||||
## The Community’s Growing Distrust
|
||||
For years, the WordPress community has prided itself on its openness, inclusivity, and ability to foster innovation from all corners of the world. Automattic’s actions, however, appear to be fracturing this community. The “scorched earth” approach taken by Automattic’s leadership—demanding exorbitant sums of money from competitors and discrediting them in public forums—reeks of corporate greed.
|
||||
|
||||
## What Lies Ahead?
|
||||
The trajectory Automattic and WordPress are on is unsustainable. By alienating core developers, web hosts, and their own user base, they risk driving away the very people who built WordPress into the powerhouse it is today.
|
||||
|
||||
The open-source nature of WordPress has always been its strength, allowing developers, designers, and users to collaborate and innovate freely. However, when a single entity exerts too much control, it undermines the core principles of the platform and forces people to seek alternatives. This is already happening, with some developers opting for platforms like **Joomla**, **Drupal**, **GHOST** or even building their own CMS from scratch to regain control over their content and infrastructure.
|
||||
|
||||
If Automattic continues to push forward with this “nuclear” approach, it may backfire spectacularly. What was once a thriving and vibrant community could fragment, with disgruntled developers and hosts breaking off to create new alternatives, leaving WordPress a shell of its former self.
|
||||
|
||||
## In the Eyes of the Community
|
||||
The recent feud between WordPress and WP Engine has sparked widespread frustration and disappointment within the WordPress community. Users across platforms, including Reddit, have expressed a strong sentiment that WordPress and Automattic's actions are misguided, damaging, and ultimately harmful to the broader ecosystem. Here’s a summary of the community’s key concerns and reactions:
|
||||
|
||||
### Confusion and Fear of Overreach
|
||||
Many users are concerned about the heavy-handed use of trademark enforcement, particularly the targeting of WP Engine for using "WP" in their branding. This has caused confusion and worry, as several other businesses in the WordPress space—such as WPForms, WP Rocket, and WP Astra—also use "WP" in their names. The fear is that these businesses could also become targets, leading to a chilling effect across the ecosystem. Users feel that Automattic's efforts to control the narrative around "WP" are excessive and could hurt smaller businesses in the space.
|
||||
|
||||
### Alienation of Developers and Web Hosts
|
||||
A significant portion of the community views Automattic’s approach as an attempt to consolidate control over WordPress at the expense of the open-source community. Some see this as Automattic using its power to extract money from competitors like WP Engine while diminishing contributions from those companies. This has led to a sense of alienation, with many expressing that Automattic's actions are pushing away developers and web hosts that have supported and contributed to WordPress for years.
|
||||
|
||||
### Disruption to Businesses and Users
|
||||
The most immediate impact has been the disruption to WP Engine users, many of whom are now unable to update plugins and themes on their sites. This has caused a cascade of issues for businesses that rely on WP Engine for hosting, leading to frustration and even legal threats. Users who manage numerous websites on WP Engine have been left in a difficult position, having to explain the situation to clients and stakeholders.
|
||||
|
||||
### Disappointment with Leadership
|
||||
The community has voiced strong criticism of Matt Mullenweg, CEO of Automattic, for his handling of the situation. Many see his actions as unprofessional, childish, and damaging to WordPress’s reputation. Comparisons have been made to figures like Elon Musk, with users noting that this "scorched earth" approach is unbecoming of a leader in an open-source project. Some are even calling for Mullenweg to step down or be removed from his leadership role, as they fear his personal vendetta is undermining the integrity of WordPress.
|
||||
|
||||
### Calls for a Fork
|
||||
In light of these events, some community members are seriously considering forking WordPress. What once seemed like an extreme option now feels like a necessary step to preserve the spirit of open source. Users are discussing the possibility of creating a version of WordPress free from Automattic’s influence, where contributions are not dictated by a single company. This potential fork is seen as a way to return to the values that originally made WordPress successful.
|
||||
|
||||
## My Final Thoughts Thus Far
|
||||
Automattic and WordPress.org must take a step back and consider the long-term consequences of their actions. A CMS platform is only as strong as the community that supports it. If they continue down this path of alienation and control, they will erode the foundation that has allowed WordPress to dominate the market for over a decade.
|
||||
|
||||
The WordPress community has always thrived on collaboration and shared success. By prioritizing corporate interests over the collective good, Automattic is at risk of turning WordPress into a product, rather than a project. And when that happens, developers, hosts, and users alike will be forced to ask themselves: Is WordPress still worth it?
|
||||
|
||||
The time for course correction is now.
|
||||
|
||||
# UPDATE 9.27
|
||||
## Matt Mullenweg Talks About WordPress Situation
|
||||
<CENTER>
|
||||
<iframe width="560" height="315" src="https://www.youtube.com/embed/H6F0PgMcKWM?si=z4OWyA1bWnP8qgqq" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share" referrerpolicy="strict-origin-when-cross-origin" allowfullscreen></iframe></CENTER>
|
||||
|
||||
### Community Sentiment Update
|
||||
|
||||
The impromptu interview with Matt Mullenweg, CEO of Automattic, has sparked widespread debate and a mix of emotions in the WordPress community. Matt's appearance was unexpected, leading to an unrehearsed discussion where he addressed a range of concerns, particularly surrounding the ongoing trademark disputes with WP Engine. The comment section of the video reveals a deepening divide within the community, as many users express frustration, confusion, and skepticism regarding both the handling of WordPress's trademark policies and Matt’s responses during the interview.
|
||||
|
||||
### Concerns About Trademark Enforcement and Legal Strategy
|
||||
|
||||
One of the core issues brought up in the interview is Automattic’s aggressive enforcement of the WordPress trademark, particularly against WP Engine, a prominent managed hosting provider. While many in the community believe WP Engine has built a successful business around the open-source CMS, Automattic’s insistence on contribution requirements has led to accusations of overreach.
|
||||
|
||||
For example, one user, @distilledmark, expressed concern that Matt’s stance could signal a shift in the WordPress ecosystem, where any company using “WP” in their name could become a target for trademark enforcement. Another commenter, @sodapoppug, pointed out the irony of trademark disputes over the use of "WP," noting how “saying 'WP' seems to defeat the purpose of speaking in acronyms since it’s twice as many syllables as just saying 'WordPress.’” This playful jab reflects a broader sentiment that the enforcement seems heavy-handed and unnecessary, especially when smaller businesses have been using "WP" in good faith for years without issue.
|
||||
|
||||
This concern is amplified by @nephatrine’s comment, which underscores how WP Engine’s branding may confuse users into thinking they are affiliated with the core WordPress project. The fear that Automattic’s legal actions may extend beyond WP Engine is echoed by many commenters, including @SoreBrain, who admits that they initially thought WP Engine was an official part of WordPress. This shows the confusion that exists within the community regarding the relationships between various WordPress-related companies.
|
||||
|
||||
### Community Frustration Over Matt’s Responses
|
||||
|
||||
Throughout the interview, many viewers felt that Matt failed to provide clear, fact-based answers to critical questions, often deflecting or giving vague responses. One commenter, @maxdayton614, criticized Matt for relying too much on emotional appeals rather than presenting concrete evidence. They noted that most of Matt’s arguments seemed to be based on personal frustration, such as his claim that WP Engine hasn’t contributed enough hours or money to WordPress. They wrote, “Almost every answer was emotionally charged. 'I’m the one committing to open source' or 'Look at all of the companies in good standing with me.'” This sentiment was echoed by others who were disappointed in the lack of legal documentation or hard evidence presented during the interview.
|
||||
|
||||
Another user, @rafalfaro, took a more critical stance, stating, “It should've been damage control, but he doubled down instead,” referring to Matt’s decision to continue pushing his point rather than acknowledging the potential faults in his legal strategy. This approach led to several comments questioning whether Matt was being entirely forthright during the interview. @datguy4104 added, “Around 11 minutes in, he says ‘Yeah, it’s open-source, you can do what you want with it,’ then at 15:15 refers to altering the Stripe plugin as ‘hacking’ it. He is very careful about using specific language to paint WP Engine as the bad guy.”
|
||||
|
||||
For some viewers, the lack of specificity was a major issue. @rns10 highlighted this by writing, “There is no definitive evidence in front of the public that what WP Engine is doing is wrong. Matt is going from a perspective of keeping his word, but without any written communication, WP Engine’s lawyers will chew him out.” This reflects a growing concern among the community that Matt’s personal frustrations are driving the legal battle, rather than a solid legal foundation.
|
||||
|
||||
### Ethical vs. Legal Obligations
|
||||
|
||||
Many commenters discussed the broader ethical implications of the situation, with some agreeing that WP Engine, as a highly profitable company, should be contributing more to the WordPress ecosystem. However, the method of enforcing this contribution through legal threats and trademark enforcement was seen as problematic.
|
||||
|
||||
@shableep raised an insightful point, arguing that while Matt may be ethically correct in believing that companies profiting from WordPress should contribute, the way Automattic has managed these situations feels coercive. They wrote, “At what level of revenue must you hit before you have to contribute or risk having the trademark enforced? Hosts are at the whim of when Matt decides enough is enough, and they must contribute. […] I think the way he’s been managing it by nudging these companies in the ‘right direction’ but asking for fees or contributions and it leading to an ‘or else’ conversation is probably, technically, extortion, even if his heart is in the right place.”
|
||||
|
||||
Other users like @roadrunner2324 attempted to summarize Matt’s stance: “Everyone is allowed to use the WP trademark, but if your company is making half a billion in revenue, and your huge base of clients consumes the official WordPress endpoints, then they would like you to pay for their license OR pay that amount in hours/contribution to the core to make the platform better for everyone.”
|
||||
|
||||
This comment captures the frustration many feel about the blurred lines between WordPress’s open-source nature and the business side of Automattic’s trademark policies. It highlights the delicate balance between open-source values and corporate realities—something that many users believe Matt is mishandling.
|
||||
|
||||
### Calls for Greater Transparency and Communication
|
||||
|
||||
A recurring theme in the comment section was the demand for more transparency and clearer guidelines from Automattic. Many viewers pointed out that the lack of clarity surrounding contribution requirements and trademark enforcement has caused confusion and fear within the community. @geoffl commented, “Matt needs to give clear guidelines on when/how he will ask for contributions from hosting companies. That will reduce consumer uncertainty on whether they will have access to plugins.”
|
||||
|
||||
The broader WordPress community seems unsure of where Automattic draws the line between companies that need to contribute and those that do not. @mauricioac added a general piece of advice about business dealings, saying, “Something I learned a long time ago after getting backstabbed: never make verbal agreements. Always, ALWAYS, have written records.” This sentiment reinforces the idea that Matt’s informal approach to business dealings with companies like WP Engine could come back to haunt him in court.
|
||||
|
||||
### The Risk of Alienating the WordPress Ecosystem
|
||||
|
||||
Another significant concern is the potential long-term damage to the WordPress ecosystem if this issue continues to escalate. Commenters like @UODZU-P expressed frustration that WP Engine customers were already being affected by the trademark dispute. They wrote, “We are now looking to migrate 20+ sites off WPE to something else because we can’t receive security updates due to him going ‘scorched earth.’ So now I’m looking to abandon WP from my tech stack altogether.”
|
||||
|
||||
This highlights a critical issue for Automattic: by taking legal action against a major player like WP Engine, they risk alienating the very community that has made WordPress successful. Many users expressed concern that similar actions could be taken against other hosting companies, leading to an exodus of developers, businesses, and users from the platform.
|
||||
|
||||
### My Thoughts: A Divided Community
|
||||
|
||||
Overall, the community sentiment following the interview with Matt Mullenweg reflects a growing divide between Automattic’s leadership and the broader WordPress community. While some users support Matt’s ethical stance, many are concerned about the legal strategies being employed and the potential fallout for the WordPress ecosystem. The lack of clear communication, the emotional nature of Matt’s responses, and the perceived coercion of companies like WP Engine have left many users feeling uneasy about the future of WordPress.
|
||||
|
||||
As one user, @sluffmo, summed it up: “All he’s achieved is showing the WP community that one immature, greedy dude throwing a tantrum can screw up their site without warning. Who cares about WP Engine? Time to pick another CMS.” This comment encapsulates the risk Automattic faces if they continue down this path—alienating the very developers and users who have built their success.
|
||||
|
||||
# UPDATE: 10.12
|
||||
### ACF Plugin Taken Over by WordPress.org
|
||||
|
||||
In a surprising and contentious move, WordPress.org has forcibly taken over control of the Advanced Custom Fields (ACF) plugin, a popular tool used by developers to customize their WordPress sites, without the consent of the ACF team. This action has left many in the WordPress community shocked and concerned about the future of the plugin, which has been trusted for over a decade.
|
||||
|
||||
### Key Points:
|
||||
|
||||
- **No Action Needed for WP Engine, Flywheel, or ACF PRO Customers**: If you are using WP Engine, Flywheel, or have ACF PRO, you will continue receiving updates directly from the ACF team. There’s no need to worry about losing access to future updates.
|
||||
|
||||
- **For Other Hosts**: If your site is hosted elsewhere, you must take action to ensure the security of your site. ACF advises users to perform a one-time download of version 6.3.8 from their website to maintain control over plugin updates. The ACF team no longer manages updates via WordPress.org, leaving many developers to manually update to stay protected.
|
||||
|
||||
- **ACF's Continued Commitment**: Despite the forced takeover, the ACF team reassures users that they will continue to support and enhance the plugin, maintaining its high standards of functionality and security.
|
||||
|
||||
### Community Response
|
||||
|
||||
This move by WordPress.org raises further questions about their aggressive control over key plugins in the ecosystem. With WP Engine and other major platforms already feeling the strain from WordPress’s trademark and legal pressures, the seizure of ACF only deepens concerns about the future of third-party development within the WordPress ecosystem.
|
||||
|
||||
The ACF team, trusted for over a decade, remains dedicated to serving their users outside of WordPress.org’s ecosystem, but this event adds fuel to the growing fire of distrust towards Automattic and their heavy-handed approach.
|
||||
|
||||
### What Does This Mean for Developers?
|
||||
|
||||
This takeover has developers wondering which plugin or service might be next. Many see this as another move by Automattic to centralize control over WordPress development, alienating independent plugin developers and reducing diversity in the ecosystem. The community is now asking: if even well-established plugins like ACF are not safe from WordPress.org’s actions, is any plugin truly secure?
|
||||
|
||||
As WordPress continues to push forward with such actions, developers, hosts, and users alike are reassessing their commitment to the platform.
|
||||
|
||||
⚠️ **Ensure your site's security by downloading the genuine ACF 6.3.8 version directly from the ACF team.**
|
||||
|
||||
|
||||
## The Corporate Battle: Silver Lake and the Future of WordPress
|
||||
|
||||
At the heart of the escalating conflict between WordPress and WP Engine lies the involvement of Silver Lake, a prominent private equity firm. Silver Lake, which acquired a majority stake in WP Engine in 2018, has been at the center of this dispute, introducing a new dimension of corporate power dynamics to the traditionally open-source-driven WordPress ecosystem.
|
||||
|
||||
### Silver Lake’s Role in the WP Engine Controversy
|
||||
|
||||
Silver Lake's acquisition of WP Engine marked a pivotal moment for the company, providing the financial backing to scale its operations and solidify its position as one of the leading managed WordPress hosting providers. However, this backing also means that WP Engine is no longer simply a player in the open-source world—it's now heavily influenced by the demands and expectations of its corporate stakeholders.
|
||||
|
||||
For Automattic, this creates a unique tension. On one hand, WP Engine is a vital part of the WordPress ecosystem, hosting countless websites and contributing to its overall success. On the other hand, Silver Lake’s presence signifies a shift towards commercial interests that may not align with WordPress's open-source values. Automattic founder Matt Mullenweg has framed this as a battle for the soul of WordPress, accusing Silver Lake of prioritizing profits over the community-driven ethos that WordPress was built upon.
|
||||
|
||||
In Mullenweg’s own words:
|
||||
|
||||
> "Silver Lake doesn’t care about your open-source ideals. It just wants a return on capital."
|
||||
|
||||
This sentiment reflects a broader concern among developers and users—namely, that the influence of private equity in the WordPress ecosystem could undermine the collaborative, open-source nature that has long been its strength.
|
||||
|
||||
### The Stakes for Open-Source Software
|
||||
|
||||
The involvement of a major private equity firm like Silver Lake raises questions about the long-term sustainability of open-source projects like WordPress. While open-source software has always operated in a delicate balance between community contributions and commercial interests, the current dispute underscores the challenges that arise when corporate entities with vastly different goals enter the picture.
|
||||
|
||||
Silver Lake’s role in WP Engine brings into focus the larger debate about how open-source projects should be monetized and governed. Can a company like WP Engine, backed by corporate interests, still claim to champion the open-source philosophy that made WordPress successful? Or does Silver Lake’s influence signify a shift towards a more closed, profit-driven model that could alienate developers and users alike?
|
||||
|
||||
### The Risk of Fragmentation
|
||||
|
||||
As the legal battle between Automattic and WP Engine unfolds, there is a real risk of fragmentation within the WordPress ecosystem. Some developers and hosting providers may begin to look for alternatives, fearing that Automattic’s increasingly aggressive stance toward WP Engine could set a precedent for other companies that use WordPress as part of their business model.
|
||||
|
||||
The broader question that arises is: **How much control should Automattic have over the WordPress ecosystem?**
|
||||
|
||||
Silver Lake’s involvement complicates this question, as it introduces a powerful corporate entity into the mix, one that is primarily concerned with generating returns for its investors. The friction between Automattic’s vision for WordPress and Silver Lake’s business interests could drive a wedge between the various stakeholders in the community, ultimately leading to forks of the platform or the rise of new competitors.
|
||||
|
||||
### A Battle for the Future of WordPress
|
||||
|
||||
This conflict between Automattic and WP Engine, with Silver Lake as a key player, is about more than just trademark disputes or licensing fees. It's about the future of WordPress itself. Will WordPress remain an open, community-driven platform, or will it evolve into a more corporatized product, shaped by the interests of private equity and large businesses?
|
||||
|
||||
For developers, hosts, and users, the outcome of this legal battle will have far-reaching implications. The decisions made in the coming months could determine whether WordPress continues to thrive as an open-source project, or whether it becomes increasingly controlled by a small number of corporate entities with competing interests.
|
||||
|
||||
As one Reddit commenter put it:
|
||||
|
||||
> "This feels like a turning point for WordPress. If we’re not careful, we could lose the open-source spirit that made this platform great in the first place."
|
||||
|
||||
As the battle between Automattic, WP Engine, and Silver Lake rages on, it’s clear that the stakes couldn’t be higher—for WordPress, for its community, and for the future of open-source software.
|
||||
|
||||
# To summarize
|
||||
|
||||
<iframe width="560" height="315" src="https://www.youtube.com/embed/mc5P_082bvY?si=xVGqhKRS35yk98sl" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share" referrerpolicy="strict-origin-when-cross-origin" allowfullscreen></iframe>
|
||||
|
||||
## Sources
|
||||
|
||||
- [WordPress.org: WP Engine is not WordPress](https://wordpress.org/news/2024/09/wp-engine/)
|
||||
- [WP Engine Cease and Desist Letter](https://wpengine.com/wp-content/uploads/2024/09/Cease-and-Desist-Letter-to-Automattic-and-Request-to-Preserve-Documents-Sent.pdf)
|
||||
- [WordPress Trademark Policy Changes (Archived)](https://web.archive.org/web/20240924024555/https://wordpressfoundation.org/trademark-policy/)
|
||||
- [WordPress Foundation: Trademark Policy](https://wordpressfoundation.org/trademark-policy/)
|
||||
- [Reddit Discussion: WordPress Trademark Policy](https://www.reddit.com/r/Wordpress/comments/1foknoq/the_wordpress_foundation_trademark_policy_was/?share_id=pDvacXlhttDifEUjnc5tq)
|
||||
- [Reddit Discussion: WP Engine Plugin Repository Inaccessibility](https://www.reddit.com/r/Wordpress/comments/1fpeqn2/plugin_repository_inaccessible_to_wp_engine/)
|
||||
- [WordPress.org: WP Engine Banned](https://wordpress.org/news/2024/09/wp-engine-banned/)
|
||||
- [WordPress.org: ACF](https://www.advancedcustomfields.com/)
|
||||
@ -0,0 +1,531 @@
|
||||
<!-- lead -->
|
||||
Empowering Open Communication Through Decentralized Audio Streaming
|
||||
|
||||
Control over information is both a powerful asset and a contentious issue. Centralized services hold significant sway over what content can be shared, placing constraints on open communication. But with advancements in peer-to-peer (P2P) technology, we're beginning to break down these walls. One powerful tool for this revolution is **pearCast**, an entirely decentralized, real-time audio broadcasting application that enables users to share audio without any centralized control or reliance on third-party servers.
|
||||
|
||||
pearCast leverages **Hyperswarm** and **WebRTC** to allow anyone with internet access to broadcast audio directly to listeners, removing the need for external servers and intermediaries. This P2P approach offers advantages like privacy, resilience against censorship, and enhanced freedom of communication. Built with **Pear CLI**, pearCast is accessible as a desktop application, empowering users with tools to sidestep centralized restrictions and create their own channels of communication.
|
||||
|
||||
<p align="center">
|
||||
<img src="https://git.ssh.surf/snxraven/pearCast/media/branch/main/screenshots/create.png" alt="pearCast">
|
||||
</p>
|
||||
|
||||
# Source
|
||||
|
||||
## [https://git.ssh.surf/snxraven/pearCast](https://git.ssh.surf/snxraven/pearCast)
|
||||
|
||||
## The Power of P2P Broadcasting
|
||||
|
||||
In a traditional client-server setup, broadcasters send their data to a central server, which then redistributes it to listeners. However, central servers can impose restrictions, leading to censorship, surveillance, and single points of failure. pearCast changes this by adopting a P2P model: data flows directly between the broadcaster and each listener, avoiding central servers and even third-party STUN/TURN servers altogether.
|
||||
|
||||
This approach offers significant benefits:
|
||||
|
||||
1. **Freedom from Censorship**: In a P2P model, there's no central authority that can restrict, alter, or monitor content. The decentralized nature of pearCast means that control is distributed among the users.
|
||||
|
||||
2. **Enhanced Privacy**: With no central server or third-party servers logging or monitoring user activity, P2P connections enhance privacy. pearCast uses end-to-end encryption provided by Hyperswarm, ensuring that only intended recipients can access the content.
|
||||
|
||||
3. **Resilience**: In pearCast, if one peer disconnects, the network remains operational. Broadcasters retain control, and connections remain active for listeners who are still tuned in. There is no single point of failure.
|
||||
|
||||
P2P connections are especially useful in regions where internet access is regulated or in situations where people need a secure way to broadcast audio without surveillance. With pearCast, users can host a private radio station, hold secure discussions, or share music with friends—all without centralized oversight.
|
||||
|
||||
## Behind the Scenes: How pearCast Works
|
||||
|
||||
pearCast is powered by several key technologies:
|
||||
|
||||
- **Hyperswarm** for peer discovery and P2P connections.
|
||||
- **WebRTC** for real-time audio streaming.
|
||||
- **Web Audio API** for audio capture and playback.
|
||||
- **Pear CLI** for running the app as a desktop application.
|
||||
|
||||
Let's delve deeper into how these technologies work together to create a seamless, decentralized audio broadcasting experience.
|
||||
|
||||
### Hyperswarm: Building P2P Connections
|
||||
|
||||
#### Overview of Hyperswarm
|
||||
|
||||
Hyperswarm is a networking stack designed for building scalable, decentralized P2P applications. It operates over a Distributed Hash Table (DHT), allowing peers to discover each other based on shared cryptographic keys, known as "topics." Hyperswarm abstracts the complexity of peer discovery and connection establishment, handling Network Address Translation (NAT) traversal and hole punching internally.
|
||||
|
||||
Key features of Hyperswarm:
|
||||
|
||||
- **Topic-Based Peer Discovery**: Peers announce or look up topics (32-byte keys), enabling them to find each other without a central server.
|
||||
- **End-to-End Encryption**: Connections are secured using the Noise Protocol framework.
|
||||
- **NAT Traversal**: Automatically handles NAT traversal techniques to establish direct connections between peers.
|
||||
|
||||
#### How pearCast Uses Hyperswarm
|
||||
|
||||
In pearCast, Hyperswarm is the backbone for both signaling and data transport. Here's a detailed breakdown:
|
||||
|
||||
- **Station Key Generation**: When a broadcaster creates a station, pearCast generates a unique 32-byte cryptographic key using `crypto.randomBytes(32)`. This key serves as the station's identifier and is shared with listeners.
|
||||
|
||||
```javascript
|
||||
let stationKey = crypto.randomBytes(32); // Generate a unique station key
|
||||
```
|
||||
|
||||
- **Joining the Network**: Both broadcasters and listeners use Hyperswarm to join the network based on the station key.
|
||||
|
||||
- **Broadcaster**:
|
||||
|
||||
```javascript
|
||||
swarm.join(stationKey, { client: false, server: true });
|
||||
```
|
||||
|
||||
The broadcaster joins as a server, announcing its presence and listening for incoming connections.
|
||||
|
||||
- **Listener**:
|
||||
|
||||
```javascript
|
||||
swarm.join(stationKey, { client: true, server: false });
|
||||
```
|
||||
|
||||
Listeners join as clients, searching for peers that have announced themselves under the same station key.
|
||||
|
||||
- **Connection Handling**: When a connection is established, Hyperswarm emits a `'connection'` event, providing a duplex stream (`conn`) for communication.
|
||||
|
||||
```javascript
|
||||
swarm.on('connection', (conn) => {
|
||||
// Handle the connection
|
||||
});
|
||||
```
|
||||
|
||||
- **Security and Privacy**: Connections over Hyperswarm are end-to-end encrypted using the Noise Protocol framework, ensuring that only peers with the correct station key can communicate.
|
||||
|
||||
#### NAT Traversal and Hole Punching
|
||||
|
||||
Hyperswarm handles NAT traversal through techniques like UDP hole punching and the use of relay servers in the DHT. This is crucial because many users are behind NATs, which can prevent direct P2P connections.
|
||||
|
||||
- **UDP Hole Punching**: Hyperswarm attempts to establish direct connections by coordinating connection attempts between peers, sending packets simultaneously to penetrate NATs.
|
||||
|
||||
### Custom Signaling over Hyperswarm
|
||||
|
||||
#### The Challenge of NAT Traversal in WebRTC
|
||||
|
||||
WebRTC relies on ICE (Interactive Connectivity Establishment) to discover the best path for media data between peers, handling NAT traversal and network topology differences. Traditionally, this requires STUN and TURN servers:
|
||||
|
||||
- **STUN Servers**: Provide external network addresses to peers behind NATs, facilitating direct connections.
|
||||
- **TURN Servers**: Relay media data when direct connections cannot be established, acting as a middleman.
|
||||
|
||||
In pearCast, we aim to eliminate reliance on third-party STUN/TURN servers to achieve true decentralization.
|
||||
|
||||
#### Implementing Signaling Over Hyperswarm
|
||||
|
||||
To achieve a fully P2P connection without external servers, pearCast uses Hyperswarm connections for signaling:
|
||||
|
||||
- **Data Channels for Signaling**: The `conn` object provided by Hyperswarm serves as a data channel to exchange signaling messages (SDP offers, answers, and ICE candidates).
|
||||
|
||||
- **Custom Signaling Protocol**: Signaling messages are serialized as JSON and sent over the Hyperswarm connection.
|
||||
|
||||
```javascript
|
||||
// Sending an offer
|
||||
conn.write(JSON.stringify({ type: 'offer', offer }));
|
||||
|
||||
// Handling incoming signaling messages
|
||||
conn.on('data', async (data) => {
|
||||
const message = JSON.parse(data.toString());
|
||||
// Process the message
|
||||
});
|
||||
```
|
||||
|
||||
- **Empty ICE Servers Configuration**: We configure `RTCPeerConnection` with an empty `iceServers` array, ensuring that WebRTC uses only the ICE candidates exchanged over Hyperswarm.
|
||||
|
||||
```javascript
|
||||
const configuration = {
|
||||
iceServers: [], // No external ICE servers
|
||||
};
|
||||
const peerConnection = new RTCPeerConnection(configuration);
|
||||
```
|
||||
|
||||
#### Exchanging ICE Candidates
|
||||
|
||||
- **ICE Candidate Gathering**: As ICE candidates are discovered by WebRTC, they are sent over Hyperswarm to the remote peer.
|
||||
|
||||
```javascript
|
||||
peerConnection.onicecandidate = ({ candidate }) => {
|
||||
if (candidate) {
|
||||
conn.write(JSON.stringify({ type: 'candidate', candidate }));
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
- **Adding Remote ICE Candidates**: Received ICE candidates are added to the `RTCPeerConnection`.
|
||||
|
||||
```javascript
|
||||
if (message.type === 'candidate') {
|
||||
await peerConnection.addIceCandidate(new RTCIceCandidate(message.candidate));
|
||||
}
|
||||
```
|
||||
|
||||
#### Broadcaster-Hosted TURN-like Functionality
|
||||
|
||||
In cases where direct connections are not possible due to NAT restrictions, the broadcaster acts as a relay for media streams:
|
||||
|
||||
- **Media Relay**: The broadcaster forwards media streams between peers, effectively mimicking TURN server functionality but within the Hyperswarm network.
|
||||
|
||||
- **Advantages**:
|
||||
|
||||
- **No Third-Party Dependency**: The relay is hosted by the broadcaster, eliminating the need for external servers.
|
||||
|
||||
- **Privacy and Control**: The broadcaster maintains control over the relay, enhancing privacy.
|
||||
|
||||
### WebRTC and NAT Traversal
|
||||
|
||||
#### Establishing Peer Connections Without STUN/TURN Servers
|
||||
|
||||
By exchanging ICE candidates over Hyperswarm, pearCast enables WebRTC to attempt direct peer-to-peer connections using host candidates (local IP addresses). While this may not always work due to NAT restrictions, Hyperswarm's ability to traverse NATs at the network layer complements WebRTC's connection attempts.
|
||||
|
||||
### Web Audio API: Capturing and Streaming Audio
|
||||
|
||||
#### Capturing Audio Input
|
||||
|
||||
- **Accessing Microphone**: pearCast uses the Web Audio API to request access to the user's microphone.
|
||||
|
||||
```javascript
|
||||
localStream = await navigator.mediaDevices.getUserMedia({
|
||||
audio: { deviceId: currentDeviceId ? { exact: currentDeviceId } : undefined },
|
||||
});
|
||||
```
|
||||
|
||||
- **Handling Multiple Audio Sources**: Broadcasters can select from available audio input devices.
|
||||
|
||||
```javascript
|
||||
// Populating audio input sources
|
||||
const devices = await navigator.mediaDevices.enumerateDevices();
|
||||
```
|
||||
|
||||
#### Streaming Audio via WebRTC
|
||||
|
||||
- **Adding Tracks to Peer Connection**: The audio tracks from the microphone are added to the `RTCPeerConnection`.
|
||||
|
||||
```javascript
|
||||
localStream.getTracks().forEach((track) => {
|
||||
peerConnection.addTrack(track, localStream);
|
||||
});
|
||||
```
|
||||
|
||||
- **Media Encoding**: WebRTC handles media encoding and streaming, optimizing for bandwidth and latency.
|
||||
|
||||
#### Receiving and Playing Audio
|
||||
|
||||
- **Handling Remote Streams**: Listeners receive the audio stream through the `ontrack` event.
|
||||
|
||||
```javascript
|
||||
peerConnection.ontrack = (event) => {
|
||||
const [remoteStream] = event.streams;
|
||||
audioElement.srcObject = remoteStream;
|
||||
};
|
||||
```
|
||||
|
||||
- **Playback Using Audio Elements**: The received stream is played using an HTML `<audio>` element, providing native playback controls.
|
||||
|
||||
### Pear CLI: Running as a Desktop Application
|
||||
|
||||
#### Benefits of Pear CLI
|
||||
|
||||
- **Native Application Experience**: Pear CLI allows pearCast to run as a desktop application, bypassing browser limitations and providing better performance.
|
||||
|
||||
- **Enhanced P2P Capabilities**: Pear CLI integrates with the Pear network, facilitating peer discovery and connection management.
|
||||
|
||||
#### Installation and Usage
|
||||
|
||||
- **Installing Pear CLI**:
|
||||
|
||||
```bash
|
||||
npm install -g pear
|
||||
```
|
||||
|
||||
- **Running pearCast**:
|
||||
|
||||
```bash
|
||||
pear run pear://q3rutpfbtdsr7ikdpntpojcxy5u356qfczzgqomxqk3jdxn6ao8y
|
||||
```
|
||||
|
||||
## Setting Up pearCast
|
||||
|
||||
### P2P Runtime
|
||||
|
||||
To run pearCast via the Pear network:
|
||||
|
||||
1. **Install Pear CLI**:
|
||||
|
||||
```bash
|
||||
npm install -g pear
|
||||
```
|
||||
|
||||
2. **Run pearCast**:
|
||||
|
||||
```bash
|
||||
pear run pear://q3rutpfbtdsr7ikdpntpojcxy5u356qfczzgqomxqk3jdxn6ao8y
|
||||
```
|
||||
|
||||
### Development Setup
|
||||
|
||||
To set up and use pearCast in a development environment:
|
||||
|
||||
1. **Clone the Repository**:
|
||||
|
||||
```bash
|
||||
git clone https://git.ssh.surf/snxraven/pearCast.git
|
||||
cd pearCast
|
||||
```
|
||||
|
||||
2. **Install Dependencies**:
|
||||
|
||||
```bash
|
||||
npm install
|
||||
```
|
||||
|
||||
3. **Run the Application**:
|
||||
|
||||
```bash
|
||||
pear run --dev .
|
||||
```
|
||||
|
||||
## Walkthrough of pearCast’s Code
|
||||
|
||||
Let's dive into pearCast's code to understand how each component works together to create this powerful P2P audio streaming experience.
|
||||
|
||||
### Initializing the Application
|
||||
|
||||
#### Event Listeners and UI Initialization
|
||||
|
||||
Upon DOM content loaded, pearCast sets up event listeners for UI elements:
|
||||
|
||||
```javascript
|
||||
document.addEventListener("DOMContentLoaded", () => {
|
||||
// Set up event listeners
|
||||
});
|
||||
```
|
||||
|
||||
- **Create Station**: Opens a modal to create a new station.
|
||||
- **Join Station**: Opens a modal to join an existing station.
|
||||
- **Audio Input Selection**: Allows broadcasters to select and apply different audio input sources.
|
||||
|
||||
#### Populating Audio Input Sources
|
||||
|
||||
```javascript
|
||||
async function populateAudioInputSources() {
|
||||
const devices = await navigator.mediaDevices.enumerateDevices();
|
||||
// Populate the dropdown with audio input devices
|
||||
}
|
||||
```
|
||||
|
||||
### Setting Up Hyperswarm Connections
|
||||
|
||||
#### Broadcaster Setup
|
||||
|
||||
When a broadcaster creates a station:
|
||||
|
||||
```javascript
|
||||
async function setupStation(key) {
|
||||
swarm = new Hyperswarm();
|
||||
swarm.join(key, { client: false, server: true });
|
||||
|
||||
swarm.on('connection', (conn) => {
|
||||
// Handle new connections
|
||||
});
|
||||
}
|
||||
```
|
||||
|
||||
- **Server Mode**: The broadcaster announces its presence on the network.
|
||||
- **Connection Handling**: For each new connection, the broadcaster sets up peer connections and signaling.
|
||||
|
||||
#### Listener Setup
|
||||
|
||||
When a listener joins a station:
|
||||
|
||||
```javascript
|
||||
async function joinStation() {
|
||||
swarm = new Hyperswarm();
|
||||
swarm.join(topicBuffer, { client: true, server: false });
|
||||
|
||||
swarm.on('connection', (conn) => {
|
||||
// Handle connection to broadcaster
|
||||
});
|
||||
}
|
||||
```
|
||||
|
||||
- **Client Mode**: The listener searches for peers announcing the same station key.
|
||||
- **Initiating Signaling**: The listener initiates the WebRTC offer to the broadcaster.
|
||||
|
||||
### Custom Signaling and WebRTC Peer Connections
|
||||
|
||||
#### Peer Connection Configuration
|
||||
|
||||
```javascript
|
||||
const configuration = {
|
||||
iceServers: [], // No external ICE servers
|
||||
};
|
||||
const peerConnection = new RTCPeerConnection(configuration);
|
||||
```
|
||||
|
||||
#### Exchanging Offers and Answers
|
||||
|
||||
- **Listener Initiates Offer**:
|
||||
|
||||
```javascript
|
||||
const offer = await peerConnection.createOffer();
|
||||
await peerConnection.setLocalDescription(offer);
|
||||
conn.write(JSON.stringify({ type: 'offer', offer }));
|
||||
```
|
||||
|
||||
- **Broadcaster Responds with Answer**:
|
||||
|
||||
```javascript
|
||||
await peerConnection.setRemoteDescription(new RTCSessionDescription(message.offer));
|
||||
const answer = await peerConnection.createAnswer();
|
||||
await peerConnection.setLocalDescription(answer);
|
||||
conn.write(JSON.stringify({ type: 'answer', answer }));
|
||||
```
|
||||
|
||||
#### Handling ICE Candidates Over Hyperswarm
|
||||
|
||||
- **Sending ICE Candidates**:
|
||||
|
||||
```javascript
|
||||
peerConnection.onicecandidate = ({ candidate }) => {
|
||||
if (candidate) {
|
||||
conn.write(JSON.stringify({ type: 'candidate', candidate }));
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
- **Receiving and Adding ICE Candidates**:
|
||||
|
||||
```javascript
|
||||
if (message.type === 'candidate') {
|
||||
await peerConnection.addIceCandidate(new RTCIceCandidate(message.candidate));
|
||||
}
|
||||
```
|
||||
|
||||
### Capturing and Streaming Audio with WebRTC
|
||||
|
||||
#### Broadcaster's Audio Capture and Streaming
|
||||
|
||||
- **Accessing the Microphone**:
|
||||
|
||||
```javascript
|
||||
localStream = await navigator.mediaDevices.getUserMedia({ audio: true });
|
||||
```
|
||||
|
||||
- **Adding Tracks to Peer Connection**:
|
||||
|
||||
```javascript
|
||||
localStream.getTracks().forEach((track) => {
|
||||
peerConnection.addTrack(track, localStream);
|
||||
});
|
||||
```
|
||||
|
||||
#### Listener's Audio Reception and Playback
|
||||
|
||||
- **Handling Incoming Tracks**:
|
||||
|
||||
```javascript
|
||||
peerConnection.ontrack = (event) => {
|
||||
const [remoteStream] = event.streams;
|
||||
// Play the audio stream
|
||||
};
|
||||
```
|
||||
|
||||
- **Playing the Audio Stream**:
|
||||
|
||||
```javascript
|
||||
const audioElement = document.createElement('audio');
|
||||
audioElement.srcObject = remoteStream;
|
||||
audioElement.autoplay = true;
|
||||
document.body.appendChild(audioElement);
|
||||
```
|
||||
|
||||
### Managing Peer Connections and Disconnects
|
||||
|
||||
#### Connection Lifecycle Management
|
||||
|
||||
- **Connection Close Handling**:
|
||||
|
||||
```javascript
|
||||
conn.on('close', () => {
|
||||
// Clean up peer connections and data channels
|
||||
});
|
||||
```
|
||||
|
||||
- **Error Handling**:
|
||||
|
||||
```javascript
|
||||
conn.on('error', (err) => {
|
||||
// Handle connection errors
|
||||
});
|
||||
```
|
||||
|
||||
#### Maintaining Peer Count
|
||||
|
||||
- **Updating Peer Count**:
|
||||
|
||||
```javascript
|
||||
function updatePeerCount() {
|
||||
const peerCount = conns.length;
|
||||
// Update UI with the current peer count
|
||||
}
|
||||
```
|
||||
|
||||
### Error Handling and Resilience
|
||||
|
||||
#### Handling Network Errors
|
||||
|
||||
- **Connection Resets**: The application logs and handles `ECONNRESET` errors gracefully.
|
||||
|
||||
- **Reconnection Logic**: Implementing reconnection attempts can enhance resilience.
|
||||
|
||||
#### Limitations and Mitigations
|
||||
|
||||
- **Browser Restrictions**: Ensuring compatibility with different browsers may require additional handling.
|
||||
|
||||
- **NAT Types**: Recognizing that some NAT types may prevent direct connections, and considering fallback mechanisms.
|
||||
|
||||
## Use Cases and Real-World Applications
|
||||
|
||||
### Independent News Stations
|
||||
|
||||
In regions with strict media control, pearCast enables journalists and activists to broadcast uncensored news directly to an audience without fear of censorship.
|
||||
|
||||
- **Anonymity**: The lack of central servers makes it difficult for authorities to track broadcasters.
|
||||
|
||||
- **Security**: Encrypted connections over Hyperswarm protect the content from interception.
|
||||
|
||||
### Community Radio
|
||||
|
||||
Local communities can create their own radio stations, sharing music, news, and discussions relevant to their audience.
|
||||
|
||||
- **Cost-Effective**: No need for expensive server infrastructure.
|
||||
|
||||
- **Engagement**: Listeners can join and participate without barriers.
|
||||
|
||||
### Private Discussions
|
||||
|
||||
pearCast can be used for private group communications where privacy is paramount.
|
||||
|
||||
- **Confidentiality**: End-to-end encryption ensures conversations remain private.
|
||||
|
||||
- **Accessibility**: Easy to set up and join, requiring only the station ID.
|
||||
|
||||
### Remote Music Jams
|
||||
|
||||
Musicians can collaborate in real-time, broadcasting performances to peers.
|
||||
|
||||
- **Low Latency**: Direct P2P connections minimize latency.
|
||||
|
||||
- **Simplicity**: Musicians can focus on performance without technical distractions.
|
||||
|
||||
## Final Thoughts
|
||||
|
||||
pearCast exemplifies the potential of decentralized technologies to empower users and promote open communication. By integrating Hyperswarm and WebRTC without reliance on external servers, it offers a robust solution for secure, private, and censorship-resistant audio broadcasting.
|
||||
|
||||
**Key Takeaways**:
|
||||
|
||||
- **Decentralization**: Eliminates single points of failure and control.
|
||||
|
||||
- **Privacy**: End-to-end encryption and lack of central logging enhance user privacy.
|
||||
|
||||
- **Flexibility**: Suitable for a wide range of applications, from personal to professional use cases.
|
||||
|
||||
- **Innovation**: Demonstrates how combining existing technologies in novel ways can overcome traditional limitations.
|
||||
|
||||
Whether you're an activist seeking to disseminate information freely, a community organizer wanting to connect with your audience, or an enthusiast exploring P2P technologies, pearCast provides a platform that aligns with the values of openness, privacy, and user empowerment.
|
||||
|
||||
**Join the movement towards decentralized communication with pearCast, and experience the freedom of P2P audio broadcasting today.**
|
||||
19
me/about-rayai.md
Normal file
@ -0,0 +1,19 @@
|
||||
<h1 style="text-align: center;">About RayAI</h1>
|
||||
|
||||
<h2 style="text-align: center;">System Overview</h2>
|
||||
|
||||
<p style="text-align: center;">OS: Ubuntu 24.04 LTS (x86_64)</p>
|
||||
<p style="text-align: center;">Kernel: 15.5</p>
|
||||
|
||||
<h2 style="text-align: center;">Hardware Specs</h2>
|
||||
|
||||
<p style="text-align: center;">CPU: AMD FX-8320E (8 cores) @ 3.20 GHz</p>
|
||||
<p style="text-align: center;">GPU: NVIDIA GeForce RTX 2060 SUPER</p>
|
||||
<p style="text-align: center;">Total System Memory: 24 GB</p>
|
||||
|
||||
<h2 style="text-align: center;">AI Model</h2>
|
||||
|
||||
<p style="text-align: center;">Model: Meta-Llama-3.2 (3B)</p>
|
||||
|
||||
<p style="text-align: center;"><a href= "https://blog.raven-scott.fyi/rayai-at-home-chat-assistant-server">https://blog.raven-scott.fyi/rayai-at-home-chat-assistant-server</a></p>
|
||||
|
||||
17
me/about.md
Normal file
@ -0,0 +1,17 @@
|
||||
# About Me
|
||||
|
||||
Hi, I’m Raven Scott, a Linux enthusiast and problem solver with a deep passion for technology and creativity. I thrive in environments where I can learn, experiment, and turn ideas into reality. Whether it's building systems, coding, or tackling complex technical challenges, I find joy in using technology to make life easier and more efficient.
|
||||
|
||||
My passion for Linux and open-source technologies began early on, and since then, I’ve been on a continuous journey of growth and discovery. From troubleshooting networking issues to optimizing servers for performance, I love diving deep into the intricate details of how things work. The thrill of solving problems, especially when it comes to system security or performance optimization, is what fuels me every day.
|
||||
|
||||
## What Drives Me
|
||||
|
||||
I’m passionate about more than just the technical side. I believe in the power of technology to bring people together, and that’s why I’m dedicated to creating platforms and solutions that are accessible and impactful. Whether it's hosting services, developing peer-to-peer applications, or automating complex tasks, I’m always exploring new ways to push the boundaries of what's possible.
|
||||
|
||||
Outside of work, I love contributing to community projects and sharing my knowledge with others. Helping people grow their own skills is one of the most rewarding aspects of what I do. From mentoring to writing documentation, I’m constantly looking for ways to give back to the tech community.
|
||||
|
||||
## Creative Side
|
||||
|
||||
When I’m not deep in the technical world, I’m exploring my creative side through music. I run my own music label, where I produce and distribute AI-generated music across all platforms. Music and technology blend seamlessly for me, as both are outlets for innovation and expression.
|
||||
|
||||
In everything I do, from coding to creating music, my goal is to keep learning, growing, and sharing my passion with the world. If you ever want to connect, collaborate, or simply chat about tech or music, feel free to reach out!
|
||||
@ -10,6 +10,7 @@
|
||||
"author": "",
|
||||
"license": "ISC",
|
||||
"dependencies": {
|
||||
"axios": "^1.7.7",
|
||||
"body-parser": "^1.20.3",
|
||||
"bootstrap": "^5.3.3",
|
||||
"date-fns": "^4.0.0",
|
||||
|
||||
BIN
public/android-chrome-192x192.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 8.9 KiB |
BIN
public/android-chrome-512x512.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 27 KiB |
BIN
public/apple-touch-icon.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 8.3 KiB |
9
public/browserconfig.xml
Normal file
@ -0,0 +1,9 @@
|
||||
<?xml version="1.0" encoding="utf-8"?>
|
||||
<browserconfig>
|
||||
<msapplication>
|
||||
<tile>
|
||||
<square150x150logo src="/mstile-150x150.png"/>
|
||||
<TileColor>#da532c</TileColor>
|
||||
</tile>
|
||||
</msapplication>
|
||||
</browserconfig>
|
||||
369
public/css/chat.css
Normal file
@ -0,0 +1,369 @@
|
||||
html,
|
||||
body {
|
||||
height: 100%;
|
||||
margin: 0;
|
||||
padding: 0;
|
||||
overflow: hidden;
|
||||
background-color: #121212;
|
||||
color: white;
|
||||
font-family: Arial, sans-serif;
|
||||
}
|
||||
|
||||
p {
|
||||
margin-top: 3px;
|
||||
margin-bottom: 5.2px;
|
||||
}
|
||||
|
||||
a {
|
||||
color: #32a4e0;
|
||||
text-decoration: none;
|
||||
}
|
||||
|
||||
a:hover {
|
||||
color: #1e8ac6;
|
||||
/* Optional: Darker shade on hover */
|
||||
text-decoration: underline;
|
||||
}
|
||||
|
||||
|
||||
.bg-dark {
|
||||
background-color: #121212 !important;
|
||||
}
|
||||
|
||||
.chat-container {
|
||||
display: flex;
|
||||
flex-direction: column;
|
||||
height: 100%;
|
||||
}
|
||||
|
||||
.navbar {
|
||||
flex-shrink: 0;
|
||||
}
|
||||
|
||||
.chat-box {
|
||||
display: flex;
|
||||
flex-direction: column;
|
||||
flex-grow: 1;
|
||||
background-color: #1e1e1e;
|
||||
overflow: hidden;
|
||||
}
|
||||
|
||||
.messages {
|
||||
flex-grow: 1;
|
||||
overflow-y: auto;
|
||||
padding: 20px;
|
||||
background-color: #2e2e2e;
|
||||
border-radius: 5px;
|
||||
display: flex;
|
||||
flex-direction: column;
|
||||
}
|
||||
|
||||
.message {
|
||||
margin-bottom: 10px;
|
||||
padding: 10px;
|
||||
border-radius: 5px;
|
||||
}
|
||||
|
||||
.alert {
|
||||
margin-top: 10px;
|
||||
text-align: center;
|
||||
/* Center the text content */
|
||||
display: flex;
|
||||
/* Make sure the alert is a flex container */
|
||||
justify-content: center;
|
||||
/* Center flex items horizontally */
|
||||
align-items: center;
|
||||
/* Center flex items vertically (if needed) */
|
||||
}
|
||||
|
||||
body,
|
||||
.container {
|
||||
background-color: transparent;
|
||||
}
|
||||
|
||||
/* Success Alert - Blue Theme */
|
||||
.alert-success {
|
||||
background-color: #000000;
|
||||
/* Blue background similar to your button */
|
||||
color: white;
|
||||
/* White text */
|
||||
border: none;
|
||||
/* Remove border */
|
||||
padding: 10px 20px;
|
||||
/* Padding for spacing */
|
||||
border-radius: 5px;
|
||||
/* Rounded corners */
|
||||
text-align: center;
|
||||
/* Center text */
|
||||
display: flex;
|
||||
/* Flex layout */
|
||||
justify-content: center;
|
||||
/* Center horizontally */
|
||||
align-items: center;
|
||||
/* Center vertically */
|
||||
}
|
||||
|
||||
/* Error Alert - Maroon Red Theme */
|
||||
.alert-danger {
|
||||
background-color: #800000;
|
||||
/* Maroon red background */
|
||||
color: white;
|
||||
/* White text */
|
||||
border: none;
|
||||
/* Remove border */
|
||||
padding: 10px 20px;
|
||||
/* Padding for spacing */
|
||||
border-radius: 5px;
|
||||
/* Rounded corners */
|
||||
text-align: center;
|
||||
/* Center text */
|
||||
display: flex;
|
||||
/* Flex layout */
|
||||
justify-content: center;
|
||||
/* Center horizontally */
|
||||
align-items: center;
|
||||
/* Center vertically */
|
||||
}
|
||||
|
||||
/* Common alert styles */
|
||||
.alert {
|
||||
margin-top: 10px;
|
||||
/* Add margin at the top */
|
||||
font-size: 14px;
|
||||
/* Adjust the font size for readability */
|
||||
}
|
||||
|
||||
.message.user {
|
||||
background-color: #3a3a3a;
|
||||
color: white;
|
||||
}
|
||||
|
||||
.message.assistant {
|
||||
background-color: #282828;
|
||||
color: #f1f1f1;
|
||||
}
|
||||
|
||||
.form-control {
|
||||
background-color: #2e2e2e;
|
||||
color: white;
|
||||
border-color: #444;
|
||||
}
|
||||
|
||||
.form-control:focus {
|
||||
background-color: #2e2e2e;
|
||||
color: white;
|
||||
border-color: #888;
|
||||
}
|
||||
|
||||
pre code {
|
||||
background-color: #1e1e1e;
|
||||
color: #f8f8f2;
|
||||
padding: 10px;
|
||||
border-radius: 5px;
|
||||
display: block;
|
||||
white-space: pre-wrap;
|
||||
word-wrap: break-word;
|
||||
}
|
||||
|
||||
.copy-button {
|
||||
background-color: #444;
|
||||
color: white;
|
||||
border: none;
|
||||
cursor: pointer;
|
||||
padding: 5px;
|
||||
margin-top: 5px;
|
||||
margin-bottom: 5px;
|
||||
display: inline-block;
|
||||
}
|
||||
|
||||
.copy-button:hover {
|
||||
background-color: #555;
|
||||
}
|
||||
|
||||
.input-area {
|
||||
background-color: #1e1e1e;
|
||||
padding: 10px 20px;
|
||||
z-index: 10;
|
||||
flex-shrink: 0;
|
||||
color: white;
|
||||
}
|
||||
|
||||
.footer {
|
||||
flex-shrink: 0;
|
||||
text-align: center;
|
||||
padding: 10px;
|
||||
background-color: #121212;
|
||||
}
|
||||
|
||||
.copy-button {
|
||||
background-color: #444;
|
||||
/* Button background color */
|
||||
color: white;
|
||||
/* Button text color */
|
||||
border: none;
|
||||
/* Remove border */
|
||||
cursor: pointer;
|
||||
/* Pointer cursor for interaction */
|
||||
padding: 5px 10px;
|
||||
/* Adjusted padding for smaller size */
|
||||
margin-top: 5px;
|
||||
/* Space at the top */
|
||||
display: inline-block;
|
||||
/* Keep the button in line */
|
||||
font-size: 14px;
|
||||
/* Slightly smaller font size for compactness */
|
||||
width: 147px;
|
||||
/* Prevent the button from stretching */
|
||||
text-align: left;
|
||||
/* Align the text left */
|
||||
}
|
||||
|
||||
.copy-button-code {
|
||||
background-color: #444;
|
||||
/* Button background color */
|
||||
color: white;
|
||||
/* Button text color */
|
||||
border: none;
|
||||
/* Remove border */
|
||||
cursor: pointer;
|
||||
/* Pointer cursor for interaction */
|
||||
padding: 5px 10px;
|
||||
/* Adjusted padding for smaller size */
|
||||
margin-top: 5px;
|
||||
/* Space at the top */
|
||||
display: inline-block;
|
||||
/* Keep the button in line */
|
||||
font-size: 14px;
|
||||
/* Slightly smaller font size for compactness */
|
||||
width: 56px;
|
||||
/* Prevent the button from stretching */
|
||||
text-align: left;
|
||||
/* Align the text left */
|
||||
}
|
||||
|
||||
.copy-button:hover {
|
||||
background-color: #555;
|
||||
/* Darker shade on hover */
|
||||
}
|
||||
|
||||
/* Add animations for the alerts */
|
||||
@keyframes fadeSlideIn {
|
||||
0% {
|
||||
opacity: 0;
|
||||
transform: translateY(-20px);
|
||||
}
|
||||
|
||||
100% {
|
||||
opacity: 1;
|
||||
transform: translateY(0);
|
||||
}
|
||||
}
|
||||
|
||||
@keyframes fadeSlideOut {
|
||||
0% {
|
||||
opacity: 1;
|
||||
transform: translateY(0);
|
||||
}
|
||||
|
||||
100% {
|
||||
opacity: 0;
|
||||
transform: translateY(-20px);
|
||||
}
|
||||
}
|
||||
|
||||
/* Success Alert with fade-in and slide-down animation */
|
||||
.alert {
|
||||
opacity: 0;
|
||||
transition: opacity 0.5s ease-in-out, transform 0.5s ease-in-out;
|
||||
display: flex;
|
||||
justify-content: center;
|
||||
align-items: center;
|
||||
animation: fadeSlideIn 0.5s forwards;
|
||||
}
|
||||
|
||||
/* Add class for fading out when alert is being removed */
|
||||
.alert.fade-out {
|
||||
animation: fadeSlideOut 0.5s forwards;
|
||||
}
|
||||
|
||||
|
||||
/* Dropdown menu styling */
|
||||
.navbar .dropdown-menu {
|
||||
background-color: #1e1e1e;
|
||||
/* Match the chat box background */
|
||||
border: none;
|
||||
/* Remove border */
|
||||
box-shadow: none;
|
||||
/* Remove shadow */
|
||||
padding: 0;
|
||||
/* Remove padding */
|
||||
}
|
||||
|
||||
.navbar .dropdown-item {
|
||||
background-color: #1e1e1e;
|
||||
/* Match the chat box background */
|
||||
color: white;
|
||||
/* White text */
|
||||
padding: 10px 20px;
|
||||
/* Add padding for spacing */
|
||||
border-bottom: 1px solid #444;
|
||||
/* Add a subtle separator */
|
||||
}
|
||||
|
||||
.navbar .dropdown-item:last-child {
|
||||
border-bottom: none;
|
||||
/* Remove border for the last item */
|
||||
}
|
||||
|
||||
.navbar .dropdown-item:hover {
|
||||
background-color: #282828;
|
||||
/* Slightly lighter background on hover */
|
||||
color: #f1f1f1;
|
||||
/* Lighter text on hover */
|
||||
}
|
||||
|
||||
.navbar .dropdown-item:focus {
|
||||
background-color: #282828;
|
||||
/* Match hover style for focused items */
|
||||
outline: none;
|
||||
/* Remove default outline */
|
||||
}
|
||||
|
||||
.navbar .dropdown-toggle {
|
||||
color: white;
|
||||
/* White text */
|
||||
}
|
||||
|
||||
.navbar .dropdown-toggle::after {
|
||||
border-top: 0.3em solid white;
|
||||
/* White arrow for dropdown */
|
||||
}
|
||||
|
||||
.navbar .dropdown-menu.show {
|
||||
opacity: 1;
|
||||
/* Fully opaque when shown */
|
||||
transform: translateY(0);
|
||||
/* Reset transform */
|
||||
transition: opacity 0.3s ease-in-out, transform 0.3s ease-in-out;
|
||||
/* Smooth fade and slide transition */
|
||||
}
|
||||
|
||||
.navbar .dropdown-menu {
|
||||
opacity: 0;
|
||||
transform: translateY(-10px);
|
||||
/* Start hidden and slightly raised */
|
||||
transition: opacity 0.3s ease-in-out, transform 0.3s ease-in-out;
|
||||
/* Smooth fade and slide transition */
|
||||
}
|
||||
|
||||
/* Styling the dropdown toggle button */
|
||||
.navbar .dropdown-toggle:hover {
|
||||
color: #f1f1f1;
|
||||
/* Lighter text on hover */
|
||||
}
|
||||
|
||||
/* Separator between regular menu items and dropdown */
|
||||
.navbar .separator {
|
||||
color: #555;
|
||||
/* Subtle separator color */
|
||||
}
|
||||
@ -1,3 +1,4 @@
|
||||
/* Base Styles */
|
||||
body {
|
||||
font-family: 'Roboto', sans-serif;
|
||||
display: flex;
|
||||
@ -5,49 +6,81 @@ body {
|
||||
min-height: 100vh;
|
||||
color: #333;
|
||||
margin: 0;
|
||||
background-color: #f8f9fa;
|
||||
}
|
||||
|
||||
main {
|
||||
flex-grow: 1;
|
||||
padding: 20px;
|
||||
}
|
||||
|
||||
a {
|
||||
color: #000;
|
||||
text-decoration: none;
|
||||
transition: color 0.2s ease;
|
||||
}
|
||||
|
||||
a:hover {
|
||||
color: #42484a;
|
||||
}
|
||||
|
||||
/* Add margin between list items */
|
||||
li {
|
||||
margin-bottom: 1rem; /* Space between list items */
|
||||
line-height: 1.6; /* Improve readability for longer text */
|
||||
}
|
||||
|
||||
/* Adjust list container margins */
|
||||
dl, ol, ul {
|
||||
margin-top: -13px;
|
||||
margin-top: 0;
|
||||
margin-bottom: 1rem;
|
||||
}
|
||||
|
||||
/* Primary Background */
|
||||
.bg-primary {
|
||||
--bs-bg-opacity: 1;
|
||||
background-color: rgb(0, 0, 0) !important;
|
||||
}
|
||||
|
||||
.bg-dark {
|
||||
--bs-bg-opacity: 1;
|
||||
background-color: rgb(0 0 0) !important;
|
||||
}
|
||||
|
||||
/* Navbar Styles */
|
||||
.navbar {
|
||||
background-color: #121212;
|
||||
background-color: #000000;
|
||||
padding: 10px 20px;
|
||||
}
|
||||
|
||||
.navbar-brand {
|
||||
font-size: 1.75rem;
|
||||
font-weight: bold;
|
||||
color: #ffffff;
|
||||
transition: color 0.2s ease;
|
||||
}
|
||||
|
||||
.navbar-brand:hover {
|
||||
color: #42484a;
|
||||
}
|
||||
|
||||
.navbar-nav .nav-link {
|
||||
font-size: 1.15rem;
|
||||
padding-right: 1rem;
|
||||
color: #ffffff;
|
||||
transition: color 0.2s ease;
|
||||
}
|
||||
|
||||
.navbar-nav .nav-link:hover {
|
||||
color: #42484a;
|
||||
}
|
||||
|
||||
/* Header */
|
||||
header {
|
||||
background: #000000;
|
||||
background: #000;
|
||||
color: #fff;
|
||||
padding: 2px 0;
|
||||
padding: 10px 0;
|
||||
text-align: center;
|
||||
height: auto;
|
||||
}
|
||||
|
||||
h1 {
|
||||
@ -57,9 +90,10 @@ h1 {
|
||||
|
||||
p.lead {
|
||||
font-size: 1.5rem;
|
||||
margin-bottom: 1.5rem;
|
||||
}
|
||||
|
||||
/* Read Article Button Styling */
|
||||
/* Button Styles */
|
||||
.btn-outline-primary {
|
||||
font-size: 1.25rem;
|
||||
padding: 10px 20px;
|
||||
@ -70,38 +104,41 @@ p.lead {
|
||||
}
|
||||
|
||||
.btn-outline-primary:hover {
|
||||
background-color: #2c5364;
|
||||
border-color: #2c5364;
|
||||
background-color: #42484a;
|
||||
border-color: #42484a;
|
||||
color: #ffffff;
|
||||
}
|
||||
|
||||
/* Pagination Styling */
|
||||
/* Pagination Styles */
|
||||
.pagination {
|
||||
margin-top: 20px;
|
||||
display: flex;
|
||||
justify-content: center;
|
||||
}
|
||||
|
||||
.pagination .page-item .page-link {
|
||||
color: #ffffff;
|
||||
background-color: #1e1e1e;
|
||||
border: 1px solid #2c5364;
|
||||
border: 1px solid #42484a;
|
||||
padding: 10px 15px;
|
||||
transition: background-color 0.3s ease, color 0.3s ease;
|
||||
}
|
||||
|
||||
.pagination .page-item.active .page-link {
|
||||
background-color: #2c5364;
|
||||
border-color: #2c5364;
|
||||
background-color: #42484a;
|
||||
border-color: #42484a;
|
||||
color: #ffffff;
|
||||
}
|
||||
|
||||
.pagination .page-item .page-link:hover {
|
||||
background-color: #2c5364;
|
||||
border-color: #2c5364;
|
||||
background-color: #42484a;
|
||||
border-color: #42484a;
|
||||
color: #ffffff;
|
||||
}
|
||||
|
||||
/* Footer Styles */
|
||||
footer {
|
||||
background-color: #121212;
|
||||
background-color: #000000;
|
||||
color: #fff;
|
||||
padding: 20px 0;
|
||||
text-align: center;
|
||||
@ -111,40 +148,21 @@ footer {
|
||||
.footer-logo {
|
||||
font-size: 1.5rem;
|
||||
font-weight: bold;
|
||||
margin-bottom: 10px;
|
||||
}
|
||||
|
||||
.footer-links a {
|
||||
color: #999;
|
||||
text-decoration: none;
|
||||
margin-right: 1rem;
|
||||
transition: color 0.2s ease;
|
||||
}
|
||||
|
||||
.footer-links a:hover {
|
||||
color: #fff;
|
||||
}
|
||||
|
||||
/* Custom Styles for Navbar and Dropdown */
|
||||
.navbar {
|
||||
background-color: #121212;
|
||||
}
|
||||
|
||||
.navbar-brand {
|
||||
font-size: 1.75rem;
|
||||
font-weight: bold;
|
||||
color: #ffffff;
|
||||
}
|
||||
|
||||
.navbar-nav .nav-link {
|
||||
font-size: 1.15rem;
|
||||
color: #ffffff;
|
||||
padding-right: 1rem;
|
||||
}
|
||||
|
||||
.navbar-nav .nav-link:hover {
|
||||
color: #2c5364;
|
||||
}
|
||||
|
||||
/* Custom Dropdown Styling */
|
||||
/* Dropdown Styles */
|
||||
.custom-dropdown {
|
||||
background-color: #1e1e1e;
|
||||
border: none;
|
||||
@ -159,21 +177,77 @@ footer {
|
||||
transition: background-color 0.3s ease, color 0.3s ease;
|
||||
}
|
||||
|
||||
.custom-dropdown .dropdown-item:hover {
|
||||
background-color: #000000;
|
||||
color: #ffffff;
|
||||
}
|
||||
|
||||
.custom-dropdown .dropdown-item:hover,
|
||||
.custom-dropdown .dropdown-item:active {
|
||||
background-color: #000000;
|
||||
color: #ffffff;
|
||||
}
|
||||
|
||||
/* Mobile Toggler */
|
||||
/* Mobile Navbar Toggler */
|
||||
.navbar-toggler {
|
||||
border-color: #ffffff;
|
||||
}
|
||||
|
||||
.navbar-toggler-icon {
|
||||
background-color: #ffffff;
|
||||
width: 30px;
|
||||
height: 3px;
|
||||
}
|
||||
|
||||
/* .py-4 {
|
||||
padding-top: 1.2rem !important;
|
||||
padding-bottom: 1.5rem !important;
|
||||
} */
|
||||
|
||||
.py-4 {
|
||||
padding-top: 0.2rem !important;
|
||||
padding-bottom: 0.5rem !important;
|
||||
}
|
||||
|
||||
/* Search Button Styles */
|
||||
.input-group .btn-primary {
|
||||
font-size: 1.25rem;
|
||||
padding: 10px 20px;
|
||||
color: #ffffff;
|
||||
border: 2px solid #000000;
|
||||
background-color: #000000;
|
||||
transition: background-color 0.3s ease, color 0.3s ease;
|
||||
}
|
||||
|
||||
|
||||
p {
|
||||
margin-top: 3px;
|
||||
margin-bottom: 5.2px;
|
||||
}
|
||||
|
||||
.input-group .btn-primary:hover {
|
||||
background-color: #42484a;
|
||||
border-color: #42484a;
|
||||
color: #ffffff;
|
||||
}
|
||||
|
||||
/* Custom Scrollbar for WebKit (Chrome, Safari) */
|
||||
::-webkit-scrollbar {
|
||||
width: 8px; /* Width of the entire scrollbar */
|
||||
}
|
||||
|
||||
::-webkit-scrollbar-thumb {
|
||||
background-color: #42484a; /* Color of the scrollbar handle */
|
||||
border-radius: 10px; /* Roundness of the handle */
|
||||
}
|
||||
|
||||
::-webkit-scrollbar-thumb:hover {
|
||||
background-color: #333; /* Handle color on hover */
|
||||
}
|
||||
|
||||
::-webkit-scrollbar-track {
|
||||
background-color: #121212; /* Color of the scrollbar background/track */
|
||||
}
|
||||
|
||||
/* Responsive Image Styling */
|
||||
img {
|
||||
max-width: 100%; /* Ensures the image cannot be larger than its container */
|
||||
height: auto; /* Maintains the aspect ratio */
|
||||
display: block; /* Removes any inline spacing */
|
||||
object-fit: contain; /* Ensures the image scales within its container */
|
||||
}
|
||||
BIN
public/favicon-16x16.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 1.0 KiB |
BIN
public/favicon-32x32.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 1.6 KiB |
BIN
public/favicon.ico
Normal file
|
After Width: | Height: | Size: 15 KiB |
238
public/js/chat-local.js
Normal file
@ -0,0 +1,238 @@
|
||||
// Handles key down event to send message on Enter
|
||||
function handleKeyDown(event) {
|
||||
if (event.key === 'Enter' && !event.shiftKey) {
|
||||
event.preventDefault();
|
||||
sendMessage();
|
||||
}
|
||||
}
|
||||
|
||||
// Sends a message to the chat API
|
||||
async function sendMessage() {
|
||||
const messageInput = document.getElementById('messageInput');
|
||||
let message = messageInput.value.trim();
|
||||
|
||||
if (message === '') return;
|
||||
|
||||
// Encode the message to avoid XSS attacks
|
||||
message = he.encode(message);
|
||||
|
||||
// Display the user's message in the chat
|
||||
displayMessage(message, 'user');
|
||||
messageInput.value = ''; // Clear the input
|
||||
toggleLoading(true); // Show loading indicator
|
||||
|
||||
try {
|
||||
const response = await fetch('https://infer.x64.world/chat', {
|
||||
method: 'POST',
|
||||
headers: {
|
||||
'Content-Type': 'application/json'
|
||||
},
|
||||
body: JSON.stringify({ message: message })
|
||||
});
|
||||
|
||||
if (response.ok) {
|
||||
const data = await response.json();
|
||||
displayMessage(data, 'assistant');
|
||||
} else {
|
||||
handleErrorResponse(response.status);
|
||||
}
|
||||
} catch (error) {
|
||||
displayMessage('Error: ' + error.message, 'assistant');
|
||||
} finally {
|
||||
toggleLoading(false); // Hide loading indicator
|
||||
}
|
||||
}
|
||||
|
||||
// Toggles the loading indicator
|
||||
function toggleLoading(show) {
|
||||
const loadingElement = document.getElementById('loading');
|
||||
loadingElement.style.display = show ? 'block' : 'none';
|
||||
}
|
||||
|
||||
// Displays a message in the chat window
|
||||
function displayMessage(content, sender) {
|
||||
const messages = document.getElementById('messages');
|
||||
const messageElement = document.createElement('div');
|
||||
messageElement.classList.add('message', sender);
|
||||
|
||||
// Decode HTML entities and render Markdown
|
||||
const decodedContent = he.decode(content);
|
||||
const htmlContent = marked(decodedContent);
|
||||
messageElement.innerHTML = htmlContent;
|
||||
|
||||
messages.appendChild(messageElement);
|
||||
messages.scrollTop = messages.scrollHeight; // Scroll to the bottom of the chat
|
||||
|
||||
// Highlight code blocks if any
|
||||
document.querySelectorAll('pre code').forEach((block) => {
|
||||
hljs.highlightElement(block);
|
||||
if (sender === 'assistant') {
|
||||
addCopyButton(block); // Add copy button to code blocks
|
||||
}
|
||||
});
|
||||
|
||||
// Add "Copy Full Response" button after each assistant response
|
||||
if (sender === 'assistant') {
|
||||
addCopyFullResponseButton(messages, messageElement);
|
||||
}
|
||||
}
|
||||
|
||||
// Adds a copy button to a code block
|
||||
function addCopyButton(block) {
|
||||
const button = document.createElement('button');
|
||||
button.classList.add('copy-button-code');
|
||||
button.textContent = 'Copy';
|
||||
button.addEventListener('click', () => copyToClipboard(block));
|
||||
block.parentNode.appendChild(button);
|
||||
}
|
||||
|
||||
// Adds "Copy Full Response" button below the assistant response
|
||||
function addCopyFullResponseButton(messagesContainer, messageElement) {
|
||||
const copyFullResponseButton = document.createElement('button');
|
||||
copyFullResponseButton.classList.add('copy-button');
|
||||
copyFullResponseButton.textContent = 'Copy Full Response';
|
||||
copyFullResponseButton.addEventListener('click', () => copyFullResponse(messageElement));
|
||||
|
||||
messagesContainer.appendChild(copyFullResponseButton);
|
||||
}
|
||||
|
||||
// Copies code block content to the clipboard
|
||||
function copyToClipboard(block) {
|
||||
const text = block.innerText;
|
||||
navigator.clipboard.writeText(text).then(() => {
|
||||
displayAlert('success', 'The code block was copied to the clipboard!');
|
||||
}).catch((err) => {
|
||||
displayAlert('error', 'Failed to copy code: ' + err);
|
||||
});
|
||||
}
|
||||
|
||||
// Copies the full response content to the clipboard in Markdown format
|
||||
function copyFullResponse(messageElement) {
|
||||
const markdownContent = convertToMarkdown(messageElement);
|
||||
navigator.clipboard.writeText(markdownContent).then(() => {
|
||||
displayAlert('success', 'Full response copied to clipboard!');
|
||||
}).catch((err) => {
|
||||
displayAlert('error', 'Failed to copy response: ' + err);
|
||||
});
|
||||
}
|
||||
|
||||
// Converts the HTML content of the response to Markdown, including language identifier
|
||||
function convertToMarkdown(element) {
|
||||
let markdown = '';
|
||||
const nodes = element.childNodes;
|
||||
|
||||
nodes.forEach(node => {
|
||||
if (node.nodeName === 'P') {
|
||||
markdown += `${node.innerText}\n\n`;
|
||||
} else if (node.nodeName === 'PRE') {
|
||||
const codeBlock = node.querySelector('code');
|
||||
const languageClass = codeBlock.className.match(/language-(\w+)/); // Extract language from class if available
|
||||
const language = languageClass ? languageClass[1] : ''; // Default to empty if no language found
|
||||
const codeText = codeBlock.innerText;
|
||||
|
||||
// Add language identifier to the Markdown code block
|
||||
markdown += `\`\`\`${language}\n${codeText}\n\`\`\`\n\n`;
|
||||
}
|
||||
});
|
||||
|
||||
return markdown;
|
||||
}
|
||||
|
||||
// Displays an alert message with animation
|
||||
function displayAlert(type, message) {
|
||||
const alertElement = document.getElementById(`${type}-alert`);
|
||||
alertElement.textContent = message;
|
||||
alertElement.style.display = 'flex'; // Show the alert
|
||||
alertElement.classList.remove('fade-out'); // Remove fade-out class if present
|
||||
alertElement.style.opacity = '1'; // Ensure it's fully visible
|
||||
|
||||
// Automatically hide the alert after 3 seconds with animation
|
||||
setTimeout(() => {
|
||||
alertElement.classList.add('fade-out'); // Add fade-out class to trigger animation
|
||||
setTimeout(() => {
|
||||
alertElement.style.display = 'none'; // Hide after animation finishes
|
||||
}, 500); // Match this time to the animation duration
|
||||
}, 3000); // Show the alert for 3 seconds before hiding
|
||||
}
|
||||
|
||||
// Handles error responses based on status code
|
||||
function handleErrorResponse(status) {
|
||||
const messages = document.getElementById('messages');
|
||||
const lastMessage = messages.lastElementChild;
|
||||
|
||||
if (status === 429) {
|
||||
displayAlert('error', 'Sorry, I am currently too busy at the moment!');
|
||||
// Remove the last user message if the status is 429
|
||||
if (lastMessage && lastMessage.classList.contains('user')) {
|
||||
messages.removeChild(lastMessage);
|
||||
}
|
||||
} else {
|
||||
displayMessage('Error: ' + status, 'assistant');
|
||||
// Remove the last user message for any other errors
|
||||
if (lastMessage && lastMessage.classList.contains('user')) {
|
||||
messages.removeChild(lastMessage);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// Helper function to reset the conversation on the server
|
||||
async function sendResetRequest() {
|
||||
const response = await fetch('https://infer.x64.world/reset-conversation', {
|
||||
method: 'POST',
|
||||
headers: {
|
||||
'Content-Type': 'application/json'
|
||||
}
|
||||
});
|
||||
return response;
|
||||
}
|
||||
|
||||
// Resets the chat messages and optionally displays a success message
|
||||
async function resetChat(displaySuccessMessage = true) {
|
||||
try {
|
||||
const response = await sendResetRequest();
|
||||
|
||||
if (response.ok) {
|
||||
const messagesContainer = document.getElementById('messages');
|
||||
messagesContainer.innerHTML = ''; // Clear all messages
|
||||
|
||||
if (displaySuccessMessage) {
|
||||
displayAlert('success', 'Messages Cleared!');
|
||||
}
|
||||
} else {
|
||||
displayAlert('error', 'Failed to reset conversation. Please try again.');
|
||||
}
|
||||
} catch (error) {
|
||||
displayAlert('error', 'An error occurred while resetting the conversation.');
|
||||
}
|
||||
}
|
||||
|
||||
// Resets the chat on page load without displaying the success message
|
||||
document.addEventListener('DOMContentLoaded', function () {
|
||||
resetChat(false);
|
||||
});
|
||||
|
||||
function openWindow(url, windowName, width, height) {
|
||||
window.open(url, windowName, `width=${width},height=${height},menubar=no,toolbar=no,location=no,status=no,scrollbars=yes,resizable=yes`);
|
||||
}
|
||||
|
||||
function openGpuStats() {
|
||||
openWindow('https://raven-scott.fyi/smi.html', 'gpuStatsWindow', 800, 600);
|
||||
}
|
||||
|
||||
function openLiveLog() {
|
||||
openWindow('https://llama-live-log.x64.world/', 'liveLogWindow', 600, 600);
|
||||
}
|
||||
|
||||
function openTop() {
|
||||
openWindow('https://ai-top.x64.world/', 'liveLogGtopWindow', 800, 600);
|
||||
}
|
||||
|
||||
function openNetdata() {
|
||||
openWindow('https://ai-monitor.x64.world/', 'netDataWindow', 800, 650);
|
||||
}
|
||||
|
||||
function openAbout() {
|
||||
openWindow('https://raven-scott.fyi/about-rayai', 'aboutRAIWindow', 800, 650);
|
||||
}
|
||||
|
||||
|
||||
238
public/js/chat.js
Normal file
@ -0,0 +1,238 @@
|
||||
// Handles key down event to send message on Enter
|
||||
function handleKeyDown(event) {
|
||||
if (event.key === 'Enter' && !event.shiftKey) {
|
||||
event.preventDefault();
|
||||
sendMessage();
|
||||
}
|
||||
}
|
||||
|
||||
// Sends a message to the chat API
|
||||
async function sendMessage() {
|
||||
const messageInput = document.getElementById('messageInput');
|
||||
let message = messageInput.value.trim();
|
||||
|
||||
if (message === '') return;
|
||||
|
||||
// Encode the message to avoid XSS attacks
|
||||
message = he.encode(message);
|
||||
|
||||
// Display the user's message in the chat
|
||||
displayMessage(message, 'user');
|
||||
messageInput.value = ''; // Clear the input
|
||||
toggleLoading(true); // Show loading indicator
|
||||
|
||||
try {
|
||||
const response = await fetch('https://infer.x64.world/api/v1/chat', {
|
||||
method: 'POST',
|
||||
headers: {
|
||||
'Content-Type': 'application/json'
|
||||
},
|
||||
body: JSON.stringify({ message: message })
|
||||
});
|
||||
|
||||
if (response.ok) {
|
||||
const data = await response.json();
|
||||
displayMessage(data, 'assistant');
|
||||
} else {
|
||||
handleErrorResponse(response.status);
|
||||
}
|
||||
} catch (error) {
|
||||
displayMessage('Error: ' + error.message, 'assistant');
|
||||
} finally {
|
||||
toggleLoading(false); // Hide loading indicator
|
||||
}
|
||||
}
|
||||
|
||||
// Toggles the loading indicator
|
||||
function toggleLoading(show) {
|
||||
const loadingElement = document.getElementById('loading');
|
||||
loadingElement.style.display = show ? 'block' : 'none';
|
||||
}
|
||||
|
||||
// Displays a message in the chat window
|
||||
function displayMessage(content, sender) {
|
||||
const messages = document.getElementById('messages');
|
||||
const messageElement = document.createElement('div');
|
||||
messageElement.classList.add('message', sender);
|
||||
|
||||
// Decode HTML entities and render Markdown
|
||||
const decodedContent = he.decode(content);
|
||||
const htmlContent = marked(decodedContent);
|
||||
messageElement.innerHTML = htmlContent;
|
||||
|
||||
messages.appendChild(messageElement);
|
||||
messages.scrollTop = messages.scrollHeight; // Scroll to the bottom of the chat
|
||||
|
||||
// Highlight code blocks if any
|
||||
document.querySelectorAll('pre code').forEach((block) => {
|
||||
hljs.highlightElement(block);
|
||||
if (sender === 'assistant') {
|
||||
addCopyButton(block); // Add copy button to code blocks
|
||||
}
|
||||
});
|
||||
|
||||
// Add "Copy Full Response" button after each assistant response
|
||||
if (sender === 'assistant') {
|
||||
addCopyFullResponseButton(messages, messageElement);
|
||||
}
|
||||
}
|
||||
|
||||
// Adds a copy button to a code block
|
||||
function addCopyButton(block) {
|
||||
const button = document.createElement('button');
|
||||
button.classList.add('copy-button-code');
|
||||
button.textContent = 'Copy';
|
||||
button.addEventListener('click', () => copyToClipboard(block));
|
||||
block.parentNode.appendChild(button);
|
||||
}
|
||||
|
||||
// Adds "Copy Full Response" button below the assistant response
|
||||
function addCopyFullResponseButton(messagesContainer, messageElement) {
|
||||
const copyFullResponseButton = document.createElement('button');
|
||||
copyFullResponseButton.classList.add('copy-button');
|
||||
copyFullResponseButton.textContent = 'Copy Full Response';
|
||||
copyFullResponseButton.addEventListener('click', () => copyFullResponse(messageElement));
|
||||
|
||||
messagesContainer.appendChild(copyFullResponseButton);
|
||||
}
|
||||
|
||||
// Copies code block content to the clipboard
|
||||
function copyToClipboard(block) {
|
||||
const text = block.innerText;
|
||||
navigator.clipboard.writeText(text).then(() => {
|
||||
displayAlert('success', 'The code block was copied to the clipboard!');
|
||||
}).catch((err) => {
|
||||
displayAlert('error', 'Failed to copy code: ' + err);
|
||||
});
|
||||
}
|
||||
|
||||
// Copies the full response content to the clipboard in Markdown format
|
||||
function copyFullResponse(messageElement) {
|
||||
const markdownContent = convertToMarkdown(messageElement);
|
||||
navigator.clipboard.writeText(markdownContent).then(() => {
|
||||
displayAlert('success', 'Full response copied to clipboard!');
|
||||
}).catch((err) => {
|
||||
displayAlert('error', 'Failed to copy response: ' + err);
|
||||
});
|
||||
}
|
||||
|
||||
// Converts the HTML content of the response to Markdown, including language identifier
|
||||
function convertToMarkdown(element) {
|
||||
let markdown = '';
|
||||
const nodes = element.childNodes;
|
||||
|
||||
nodes.forEach(node => {
|
||||
if (node.nodeName === 'P') {
|
||||
markdown += `${node.innerText}\n\n`;
|
||||
} else if (node.nodeName === 'PRE') {
|
||||
const codeBlock = node.querySelector('code');
|
||||
const languageClass = codeBlock.className.match(/language-(\w+)/); // Extract language from class if available
|
||||
const language = languageClass ? languageClass[1] : ''; // Default to empty if no language found
|
||||
const codeText = codeBlock.innerText;
|
||||
|
||||
// Add language identifier to the Markdown code block
|
||||
markdown += `\`\`\`${language}\n${codeText}\n\`\`\`\n\n`;
|
||||
}
|
||||
});
|
||||
|
||||
return markdown;
|
||||
}
|
||||
|
||||
// Displays an alert message with animation
|
||||
function displayAlert(type, message) {
|
||||
const alertElement = document.getElementById(`${type}-alert`);
|
||||
alertElement.textContent = message;
|
||||
alertElement.style.display = 'flex'; // Show the alert
|
||||
alertElement.classList.remove('fade-out'); // Remove fade-out class if present
|
||||
alertElement.style.opacity = '1'; // Ensure it's fully visible
|
||||
|
||||
// Automatically hide the alert after 3 seconds with animation
|
||||
setTimeout(() => {
|
||||
alertElement.classList.add('fade-out'); // Add fade-out class to trigger animation
|
||||
setTimeout(() => {
|
||||
alertElement.style.display = 'none'; // Hide after animation finishes
|
||||
}, 500); // Match this time to the animation duration
|
||||
}, 3000); // Show the alert for 3 seconds before hiding
|
||||
}
|
||||
|
||||
// Handles error responses based on status code
|
||||
function handleErrorResponse(status) {
|
||||
const messages = document.getElementById('messages');
|
||||
const lastMessage = messages.lastElementChild;
|
||||
|
||||
if (status === 429) {
|
||||
displayAlert('error', 'Sorry, I am currently too busy at the moment!');
|
||||
// Remove the last user message if the status is 429
|
||||
if (lastMessage && lastMessage.classList.contains('user')) {
|
||||
messages.removeChild(lastMessage);
|
||||
}
|
||||
} else {
|
||||
displayMessage('Error: ' + status, 'assistant');
|
||||
// Remove the last user message for any other errors
|
||||
if (lastMessage && lastMessage.classList.contains('user')) {
|
||||
messages.removeChild(lastMessage);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// Helper function to reset the conversation on the server
|
||||
async function sendResetRequest() {
|
||||
const response = await fetch('https://infer.x64.world/api/v1/reset-conversation', {
|
||||
method: 'POST',
|
||||
headers: {
|
||||
'Content-Type': 'application/json'
|
||||
}
|
||||
});
|
||||
return response;
|
||||
}
|
||||
|
||||
// Resets the chat messages and optionally displays a success message
|
||||
async function resetChat(displaySuccessMessage = true) {
|
||||
try {
|
||||
const response = await sendResetRequest();
|
||||
|
||||
if (response.ok) {
|
||||
const messagesContainer = document.getElementById('messages');
|
||||
messagesContainer.innerHTML = ''; // Clear all messages
|
||||
|
||||
if (displaySuccessMessage) {
|
||||
displayAlert('success', 'Messages Cleared!');
|
||||
}
|
||||
} else {
|
||||
displayAlert('error', 'Failed to reset conversation. Please try again.');
|
||||
}
|
||||
} catch (error) {
|
||||
displayAlert('error', 'An error occurred while resetting the conversation.');
|
||||
}
|
||||
}
|
||||
|
||||
// Resets the chat on page load without displaying the success message
|
||||
document.addEventListener('DOMContentLoaded', function () {
|
||||
resetChat(false);
|
||||
});
|
||||
|
||||
function openWindow(url, windowName, width, height) {
|
||||
window.open(url, windowName, `width=${width},height=${height},menubar=no,toolbar=no,location=no,status=no,scrollbars=yes,resizable=yes`);
|
||||
}
|
||||
|
||||
function openGpuStats() {
|
||||
openWindow('https://raven-scott.fyi/smi.html', 'gpuStatsWindow', 800, 600);
|
||||
}
|
||||
|
||||
function openLiveLog() {
|
||||
openWindow('https://llama-live-log.x64.world/', 'liveLogWindow', 600, 600);
|
||||
}
|
||||
|
||||
function openTop() {
|
||||
openWindow('https://ai-top.x64.world/', 'liveLogGtopWindow', 800, 600);
|
||||
}
|
||||
|
||||
function openNetdata() {
|
||||
openWindow('https://ai-monitor.x64.world/', 'netDataWindow', 800, 650);
|
||||
}
|
||||
|
||||
function openAbout() {
|
||||
openWindow('https://raven-scott.fyi/about-rayai', 'aboutRAIWindow', 800, 650);
|
||||
}
|
||||
|
||||
|
||||
BIN
public/mstile-150x150.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 6.7 KiB |
3
public/robots.txt
Normal file
@ -0,0 +1,3 @@
|
||||
User-agent: *
|
||||
Allow: /
|
||||
Sitemap: https://raven-scott.fyi/sitemap.xml
|
||||
19
public/site.webmanifest
Normal file
@ -0,0 +1,19 @@
|
||||
{
|
||||
"name": "",
|
||||
"short_name": "",
|
||||
"icons": [
|
||||
{
|
||||
"src": "/android-chrome-192x192.png",
|
||||
"sizes": "192x192",
|
||||
"type": "image/png"
|
||||
},
|
||||
{
|
||||
"src": "/android-chrome-512x512.png",
|
||||
"sizes": "512x512",
|
||||
"type": "image/png"
|
||||
}
|
||||
],
|
||||
"theme_color": "#ffffff",
|
||||
"background_color": "#ffffff",
|
||||
"display": "standalone"
|
||||
}
|
||||
118
public/smi.html
Normal file
@ -0,0 +1,118 @@
|
||||
<!DOCTYPE html>
|
||||
<html lang="en">
|
||||
<head>
|
||||
<meta charset="UTF-8">
|
||||
<meta name="viewport" content="width=device-width, initial-scale=1.0">
|
||||
<title>GPU Stats</title>
|
||||
<style>
|
||||
body {
|
||||
background-color: #121212;
|
||||
color: #ffffff;
|
||||
font-family: Arial, sans-serif;
|
||||
padding: 20px;
|
||||
line-height: 1.6;
|
||||
}
|
||||
.container {
|
||||
max-width: 800px;
|
||||
margin: 0 auto;
|
||||
padding: 20px;
|
||||
border: 1px solid #333;
|
||||
border-radius: 10px;
|
||||
background-color: #1e1e1e;
|
||||
}
|
||||
.title {
|
||||
font-size: 2em;
|
||||
margin-bottom: 20px;
|
||||
text-align: center;
|
||||
}
|
||||
.stat-group {
|
||||
margin-bottom: 20px;
|
||||
}
|
||||
.stat-group h2 {
|
||||
font-size: 1.5em;
|
||||
margin-bottom: 10px;
|
||||
border-bottom: 1px solid #444;
|
||||
padding-bottom: 5px;
|
||||
}
|
||||
.stat {
|
||||
margin-bottom: 10px;
|
||||
}
|
||||
.stat span {
|
||||
font-weight: bold;
|
||||
}
|
||||
pre {
|
||||
white-space: pre-wrap;
|
||||
word-wrap: break-word;
|
||||
}
|
||||
</style>
|
||||
</head>
|
||||
<body>
|
||||
<div class="container">
|
||||
<div class="title">GPU Statistics</div>
|
||||
<div id="gpu-stats"></div>
|
||||
</div>
|
||||
|
||||
<script>
|
||||
async function fetchGpuStats() {
|
||||
try {
|
||||
const response = await fetch('https://smi.x64.world/nvidia-smi');
|
||||
const data = await response.json();
|
||||
displayStats(data);
|
||||
} catch (error) {
|
||||
console.error('Error fetching GPU stats:', error);
|
||||
}
|
||||
}
|
||||
|
||||
function displayStats(data) {
|
||||
const gpuStatsDiv = document.getElementById('gpu-stats');
|
||||
const gpu = data.nvidia_smi_log.gpu;
|
||||
|
||||
gpuStatsDiv.innerHTML = `
|
||||
<div class="stat-group">
|
||||
<h2>Processes</h2>
|
||||
${Array.isArray(gpu.processes.process_info) ? gpu.processes.process_info.map(process => `
|
||||
<div class="stat"><span>Process ID:</span> ${process.pid}, <span>Name:</span> ${process.process_name}, <span>Memory Used:</span> ${process.used_memory}</div>
|
||||
`).join('') : `<div class="stat"><span>Process ID:</span> ${gpu.processes.process_info.pid}, <span>Name:</span> ${gpu.processes.process_info.process_name}, <span>Memory Used:</span> ${gpu.processes.process_info.used_memory}</div>`}
|
||||
</div>
|
||||
<div class="stat-group">
|
||||
<h2>Utilization</h2>
|
||||
<div class="stat"><span>GPU Utilization:</span> ${gpu.utilization.gpu_util}</div>
|
||||
<div class="stat"><span>Memory Utilization:</span> ${gpu.utilization.memory_util}</div>
|
||||
</div>
|
||||
<div class="stat-group">
|
||||
<h2>Clocks</h2>
|
||||
<div class="stat"><span>Graphics Clock:</span> ${gpu.clocks.graphics_clock}</div>
|
||||
<div class="stat"><span>SM Clock:</span> ${gpu.clocks.sm_clock}</div>
|
||||
<div class="stat"><span>Memory Clock:</span> ${gpu.clocks.mem_clock}</div>
|
||||
<div class="stat"><span>Video Clock:</span> ${gpu.clocks.video_clock}</div>
|
||||
</div>
|
||||
<div class="stat-group">
|
||||
<h2>Memory Usage</h2>
|
||||
<div class="stat"><span>Total FB Memory:</span> ${gpu.fb_memory_usage.total}</div>
|
||||
<div class="stat"><span>Used FB Memory:</span> ${gpu.fb_memory_usage.used}</div>
|
||||
<div class="stat"><span>Free FB Memory:</span> ${gpu.fb_memory_usage.free}</div>
|
||||
</div>
|
||||
<div class="stat-group">
|
||||
<h2>Performance</h2>
|
||||
<div class="stat"><span>Performance State:</span> ${gpu.performance_state}</div>
|
||||
<div class="stat"><span>Fan Speed:</span> ${gpu.fan_speed}</div>
|
||||
<div class="stat"><span>Power Draw:</span> ${gpu.gpu_power_readings.power_draw}</div>
|
||||
</div>
|
||||
<div class="stat-group">
|
||||
<h2>General Information</h2>
|
||||
<div class="stat"><span>Product Name:</span> ${gpu.product_name}</div>
|
||||
<div class="stat"><span>Product Brand:</span> ${gpu.product_brand}</div>
|
||||
<div class="stat"><span>Architecture:</span> ${gpu.product_architecture}</div>
|
||||
<div class="stat"><span>UUID:</span> ${gpu.uuid}</div>
|
||||
<div class="stat"><span>VBIOS Version:</span> ${gpu.vbios_version}</div>
|
||||
</div>
|
||||
`;
|
||||
}
|
||||
|
||||
window.onload = () => {
|
||||
fetchGpuStats();
|
||||
setInterval(fetchGpuStats, 2000);
|
||||
};
|
||||
</script>
|
||||
</body>
|
||||
</html>
|
||||
BIN
public/twit_linux.webp
Normal file
{kind=link}
|
After Width: | Height: | Size: 45 KiB |
61
views/about-rayai.ejs
Normal file
@ -0,0 +1,61 @@
|
||||
<!DOCTYPE html>
|
||||
<html lang="en">
|
||||
|
||||
<head>
|
||||
<!-- Meta and Title -->
|
||||
<meta charset="UTF-8">
|
||||
<meta name="viewport" content="width=device-width, initial-scale=1.0">
|
||||
<meta name="description" content="<%= process.env.OWNER_NAME %>'s Blog">
|
||||
<title><%= title %> | <%= process.env.OWNER_NAME %>'s' Blog</title>
|
||||
<!-- Bootstrap CSS -->
|
||||
<link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/bootstrap@5.3.0-alpha1/dist/css/bootstrap.min.css">
|
||||
<!-- Font Awesome CSS for Icons -->
|
||||
<link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/font-awesome/6.0.0-beta3/css/all.min.css">
|
||||
<!-- Custom CSS -->
|
||||
<link rel="stylesheet" href="<%= process.env.HOST_URL %>/css/styles.css">
|
||||
<link rel="apple-touch-icon" sizes="180x180" href="/apple-touch-icon.png">
|
||||
<link rel="icon" type="image/png" sizes="32x32" href="/favicon-32x32.png">
|
||||
<link rel="icon" type="image/png" sizes="16x16" href="/favicon-16x16.png">
|
||||
<link rel="manifest" href="/site.webmanifest">
|
||||
<meta name="msapplication-TileColor" content="#da532c">
|
||||
<meta name="theme-color" content="#ffffff">
|
||||
</head>
|
||||
|
||||
<body>
|
||||
|
||||
<!-- Navbar -->
|
||||
<nav class="navbar navbar-expand-lg navbar-dark">
|
||||
<div class="container-fluid">
|
||||
<a class="navbar-brand" href="<%= process.env.HOST_URL %>"><%= process.env.SITE_NAME %></a>
|
||||
<button class="navbar-toggler" type="button" data-bs-toggle="collapse" data-bs-target="#navbarNav" aria-controls="navbarNav" aria-expanded="false" aria-label="Toggle navigation">
|
||||
<span class="navbar-toggler-icon"></span>
|
||||
</button>
|
||||
<div class="collapse navbar-collapse" id="navbarNav">
|
||||
<ul class="navbar-nav ms-auto">
|
||||
<% menuItems.forEach(item => { %>
|
||||
<li class="nav-item">
|
||||
<a class="nav-link" href="<%= item.url %>" <%= item.openNewPage ? 'target="_blank"' : '' %>><%= item.title %></a>
|
||||
</li>
|
||||
<% }) %>
|
||||
</ul>
|
||||
</div>
|
||||
</div>
|
||||
</nav>
|
||||
|
||||
<!-- About Me Section -->
|
||||
<section class="about-me py-5">
|
||||
<div class="container">
|
||||
<div class="section-divider"></div>
|
||||
<!-- Inject the HTML content generated from the markdown -->
|
||||
<div class="markdown-content">
|
||||
<%- content %>
|
||||
</div>
|
||||
</div>
|
||||
</section>
|
||||
|
||||
<!-- Bootstrap JS Bundle -->
|
||||
<script src="https://cdn.jsdelivr.net/npm/bootstrap@5.3.0-alpha1/dist/js/bootstrap.bundle.min.js"></script>
|
||||
|
||||
</body>
|
||||
|
||||
</html>
|
||||
128
views/about.ejs
@ -5,102 +5,38 @@
|
||||
<!-- Meta and Title -->
|
||||
<meta charset="UTF-8">
|
||||
<meta name="viewport" content="width=device-width, initial-scale=1.0">
|
||||
<title>About Me - Raven Scott</title>
|
||||
<meta name="description" content="<%= process.env.OWNER_NAME %>'s Blog">
|
||||
<title><%= title %> | <%= process.env.OWNER_NAME %>'s' Blog</title>
|
||||
<!-- Bootstrap CSS -->
|
||||
<link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/bootstrap@5.3.0-alpha1/dist/css/bootstrap.min.css">
|
||||
<!-- Font Awesome CSS for Icons -->
|
||||
<link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/font-awesome/6.0.0-beta3/css/all.min.css">
|
||||
<!-- Custom CSS -->
|
||||
<link rel="stylesheet" href="/css/styles.css">
|
||||
<style>
|
||||
/* Custom styles for a more professional look */
|
||||
body {
|
||||
background-color: #1a1a1a;
|
||||
color: #e0e0e0;
|
||||
}
|
||||
|
||||
|
||||
.about-me h2,
|
||||
.about-me h3 {
|
||||
color: #ffffff;
|
||||
font-weight: bold;
|
||||
}
|
||||
|
||||
.about-me p {
|
||||
font-size: 1.1rem;
|
||||
line-height: 1.7;
|
||||
color: #d1d1d1;
|
||||
}
|
||||
|
||||
.about-me {
|
||||
padding: 50px 0;
|
||||
}
|
||||
|
||||
.container {
|
||||
max-width: 900px;
|
||||
margin: auto;
|
||||
}
|
||||
|
||||
.footer-logo {
|
||||
font-size: 1.5rem;
|
||||
font-weight: bold;
|
||||
}
|
||||
|
||||
.footer-links a {
|
||||
color: #9a9a9a;
|
||||
font-size: 0.9rem;
|
||||
}
|
||||
|
||||
.footer-links a:hover {
|
||||
color: #ffffff;
|
||||
}
|
||||
|
||||
.btn-primary {
|
||||
background-color: #007bff;
|
||||
border-color: #007bff;
|
||||
}
|
||||
|
||||
.btn-primary:hover {
|
||||
background-color: #0056b3;
|
||||
border-color: #004085;
|
||||
}
|
||||
|
||||
/* Add padding for better text readability */
|
||||
.about-me p {
|
||||
padding-bottom: 15px;
|
||||
}
|
||||
|
||||
/* Separator style for sections */
|
||||
.section-divider {
|
||||
width: 80px;
|
||||
height: 3px;
|
||||
background-color: #007bff;
|
||||
margin: 20px 0;
|
||||
border-radius: 2px;
|
||||
}
|
||||
</style>
|
||||
<link rel="stylesheet" href="<%= process.env.HOST_URL %>/css/styles.css">
|
||||
<link rel="apple-touch-icon" sizes="180x180" href="/apple-touch-icon.png">
|
||||
<link rel="icon" type="image/png" sizes="32x32" href="/favicon-32x32.png">
|
||||
<link rel="icon" type="image/png" sizes="16x16" href="/favicon-16x16.png">
|
||||
<link rel="manifest" href="/site.webmanifest">
|
||||
<meta name="msapplication-TileColor" content="#da532c">
|
||||
<meta name="theme-color" content="#ffffff">
|
||||
</head>
|
||||
|
||||
<body>
|
||||
|
||||
<!-- Navigation Bar -->
|
||||
<!-- Navbar -->
|
||||
<nav class="navbar navbar-expand-lg navbar-dark">
|
||||
<div class="container-fluid">
|
||||
<a class="navbar-brand" href="/">raven-scott.fyi</a>
|
||||
<a class="navbar-brand" href="<%= process.env.HOST_URL %>"><%= process.env.SITE_NAME %></a>
|
||||
<button class="navbar-toggler" type="button" data-bs-toggle="collapse" data-bs-target="#navbarNav" aria-controls="navbarNav" aria-expanded="false" aria-label="Toggle navigation">
|
||||
<span class="navbar-toggler-icon"></span>
|
||||
</button>
|
||||
<div class="collapse navbar-collapse" id="navbarNav">
|
||||
<ul class="navbar-nav ms-auto">
|
||||
<li class="nav-item">
|
||||
<a class="nav-link" href="/">Home</a>
|
||||
</li>
|
||||
<li class="nav-item">
|
||||
<a class="nav-link active" href="/about">About Me</a>
|
||||
</li>
|
||||
<li class="nav-item">
|
||||
<a class="nav-link" href="/contact">Contact</a>
|
||||
</li>
|
||||
<% menuItems.forEach(item => { %>
|
||||
<li class="nav-item">
|
||||
<a class="nav-link" href="<%= item.url %>" <%= item.openNewPage ? 'target="_blank"' : '' %>><%= item.title %></a>
|
||||
</li>
|
||||
<% }) %>
|
||||
</ul>
|
||||
</div>
|
||||
</div>
|
||||
@ -108,37 +44,27 @@
|
||||
|
||||
<!-- About Me Section -->
|
||||
<section class="about-me py-5">
|
||||
<div class="container text-center">
|
||||
<h2 class="text-white mb-4">About Me</h2>
|
||||
<div class="container">
|
||||
<div class="section-divider"></div>
|
||||
<p class="lead">Hi, I’m Raven Scott, a Linux enthusiast and problem solver with a deep passion for technology and creativity. I thrive in environments where I can learn, experiment, and turn ideas into reality. Whether it's building systems, coding, or tackling complex technical challenges, I find joy in using technology to make life easier and more efficient.</p>
|
||||
|
||||
<p>My passion for Linux and open-source technologies began early on, and since then, I’ve been on a continuous journey of growth and discovery. From troubleshooting networking issues to optimizing servers for performance, I love diving deep into the intricate details of how things work. The thrill of solving problems, especially when it comes to system security or performance optimization, is what fuels me every day.</p>
|
||||
|
||||
<h3 class="text-white mt-5">What Drives Me</h3>
|
||||
<div class="section-divider"></div>
|
||||
<p>I’m passionate about more than just the technical side. I believe in the power of technology to bring people together, and that’s why I’m dedicated to creating platforms and solutions that are accessible and impactful. Whether it's hosting services, developing peer-to-peer applications, or automating complex tasks, I’m always exploring new ways to push the boundaries of what's possible.</p>
|
||||
|
||||
<p>Outside of work, I love contributing to community projects and sharing my knowledge with others. Helping people grow their own skills is one of the most rewarding aspects of what I do. From mentoring to writing documentation, I’m constantly looking for ways to give back to the tech community.</p>
|
||||
|
||||
<h3 class="text-white mt-5">Creative Side</h3>
|
||||
<div class="section-divider"></div>
|
||||
<p>When I’m not deep in the technical world, I’m exploring my creative side through music. I run my own music label, where I produce and distribute AI-generated music across all platforms. Music and technology blend seamlessly for me, as both are outlets for innovation and expression.</p>
|
||||
|
||||
<p>In everything I do, from coding to creating music, my goal is to keep learning, growing, and sharing my passion with the world. If you ever want to connect, collaborate, or simply chat about tech or music, feel free to reach out!</p>
|
||||
<!-- Inject the HTML content generated from the markdown -->
|
||||
<div class="markdown-content">
|
||||
<%- content %>
|
||||
</div>
|
||||
</div>
|
||||
</section>
|
||||
|
||||
<!-- Footer -->
|
||||
<footer class="bg-dark text-white text-center py-4">
|
||||
<footer class="text-white text-center py-4">
|
||||
<div class="container">
|
||||
<h4 class="footer-logo mb-3">Never Stop Learning</h4>
|
||||
<h4 class="footer-logo mb-3"><%= process.env.FOOTER_TAGLINE %></h4>
|
||||
<p class="footer-links mb-3">
|
||||
<a href="/" class="text-white text-decoration-none me-3">Home</a>
|
||||
<a href="/about" class="text-white text-decoration-none me-3">About</a>
|
||||
<a href="/contact" class="text-white text-decoration-none">Contact</a>
|
||||
<a href="/contact" class="text-white text-decoration-none me-3">Contact</a>
|
||||
<a href="<%= process.env.HOST_URL %>/sitemap.xml" class="text-white text-decoration-none me-3">Sitemap</a>
|
||||
<a href="<%= process.env.HOST_URL %>/rss" class="text-white text-decoration-none">RSS Feed</a>
|
||||
</p>
|
||||
<p class="mb-0">© 2024 Raven Scott. All rights reserved.</p>
|
||||
<p class="mb-0">© 2025 <%= process.env.OWNER_NAME %>. All rights reserved.</p>
|
||||
</div>
|
||||
</footer>
|
||||
|
||||
|
||||
@ -3,41 +3,43 @@
|
||||
<head>
|
||||
<meta charset="UTF-8">
|
||||
<meta name="viewport" content="width=device-width, initial-scale=1.0">
|
||||
<title><%= title %></title>
|
||||
<meta name="description" content="<%= description %>">
|
||||
<title><%= title %> | <%= process.env.OWNER_NAME %>'s Blog</title>
|
||||
<!-- Stylesheets -->
|
||||
<link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/bootstrap@5.3.0-alpha1/dist/css/bootstrap.min.css">
|
||||
<link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/font-awesome/6.0.0-beta3/css/all.min.css">
|
||||
<link rel="stylesheet" href="/css/styles.css">
|
||||
<link rel="stylesheet" href="<%= process.env.HOST_URL %>/css/styles.css">
|
||||
<!-- Highlight.js CSS for Syntax Highlighting -->
|
||||
<!-- <link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/highlight.js/11.8.0/styles/default.min.css"> -->
|
||||
<link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/highlight.js/11.6.0/styles/atom-one-dark.min.css">
|
||||
|
||||
<link rel="apple-touch-icon" sizes="180x180" href="<%= process.env.HOST_URL %>/apple-touch-icon.png">
|
||||
<link rel="icon" type="image/png" sizes="32x32" href="<%= process.env.HOST_URL %>/favicon-32x32.png">
|
||||
<link rel="icon" type="image/png" sizes="16x16" href="<%= process.env.HOST_URL %>/favicon-16x16.png">
|
||||
<link rel="manifest" href="<%= process.env.HOST_URL %>/site.webmanifest">
|
||||
<meta name="msapplication-TileColor" content="#da532c">
|
||||
<meta name="theme-color" content="#ffffff">
|
||||
</head>
|
||||
<body>
|
||||
|
||||
<!-- Navbar -->
|
||||
<nav class="navbar navbar-expand-lg navbar-dark">
|
||||
<div class="container-fluid">
|
||||
<a class="navbar-brand" href="/">raven-scott.fyi</a>
|
||||
<a class="navbar-brand" href="<%= process.env.HOST_URL %>"><%= process.env.SITE_NAME %></a>
|
||||
<button class="navbar-toggler" type="button" data-bs-toggle="collapse" data-bs-target="#navbarNav" aria-controls="navbarNav" aria-expanded="false" aria-label="Toggle navigation">
|
||||
<span class="navbar-toggler-icon"></span>
|
||||
</button>
|
||||
<div class="collapse navbar-collapse" id="navbarNav">
|
||||
<ul class="navbar-nav ms-auto">
|
||||
<li class="nav-item">
|
||||
<a class="nav-link active" href="/">Home</a>
|
||||
</li>
|
||||
<li class="nav-item">
|
||||
<a class="nav-link" href="/about">About Me</a>
|
||||
</li>
|
||||
<li class="nav-item">
|
||||
<a class="nav-link" href="/contact">Contact</a>
|
||||
</li>
|
||||
<% menuItems.forEach(item => { %>
|
||||
<li class="nav-item">
|
||||
<a class="nav-link" href="<%= item.url %>" <%= item.openNewPage ? 'target="_blank"' : '' %>><%= item.title %></a>
|
||||
</li>
|
||||
<% }) %>
|
||||
</ul>
|
||||
</div>
|
||||
</div>
|
||||
</nav>
|
||||
|
||||
|
||||
<header class="bg-primary text-white text-center py-5">
|
||||
<h1><%= title %></h1>
|
||||
<p class="lead"><%= lead %></p> <!-- Lead is dynamically set here -->
|
||||
@ -51,15 +53,17 @@
|
||||
</main>
|
||||
|
||||
<!-- Footer -->
|
||||
<footer class="bg-dark text-white text-center py-4">
|
||||
<footer class="text-white text-center py-4">
|
||||
<div class="container">
|
||||
<h4 class="footer-logo mb-3">Never Stop Learning</h4>
|
||||
<h4 class="footer-logo mb-3"><%= process.env.FOOTER_TAGLINE %></h4>
|
||||
<p class="footer-links mb-3">
|
||||
<a href="/" class="text-white text-decoration-none me-3">Home</a>
|
||||
<a href="/about" class="text-white text-decoration-none me-3">About</a>
|
||||
<a href="/contact" class="text-white text-decoration-none">Contact</a>
|
||||
<a href="/contact" class="text-white text-decoration-none me-3">Contact</a>
|
||||
<a href="<%= process.env.HOST_URL %>/sitemap.xml" class="text-white text-decoration-none me-3">Sitemap</a>
|
||||
<a href="<%= process.env.HOST_URL %>/rss" class="text-white text-decoration-none">RSS Feed</a>
|
||||
</p>
|
||||
<p class="mb-0">© 2024 Raven Scott. All rights reserved.</p>
|
||||
<p class="mb-0">© 2024 <%= process.env.OWNER_NAME %>. All rights reserved.</p>
|
||||
</div>
|
||||
</footer>
|
||||
|
||||
|
||||
123
views/chat.ejs
Normal file
@ -0,0 +1,123 @@
|
||||
<!DOCTYPE html>
|
||||
<html lang="en">
|
||||
|
||||
<head>
|
||||
<!-- Meta and Title -->
|
||||
<meta charset="UTF-8">
|
||||
<meta name="viewport" content="width=device-width, initial-scale=1.0">
|
||||
<meta name="description" content="<%= process.env.OWNER_NAME %>'s Blog">
|
||||
<title>
|
||||
<%= title %> | <%= process.env.OWNER_NAME %>'s Blog
|
||||
</title>
|
||||
<!-- Bootstrap CSS -->
|
||||
<link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/bootstrap@5.3.0-alpha1/dist/css/bootstrap.min.css">
|
||||
<!-- Font Awesome CSS for Icons -->
|
||||
<link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/font-awesome/6.0.0-beta3/css/all.min.css">
|
||||
<link rel="stylesheet"
|
||||
href="https://cdnjs.cloudflare.com/ajax/libs/highlight.js/11.6.0/styles/atom-one-dark.min.css">
|
||||
<!-- Custom CSS -->
|
||||
<link rel="stylesheet" href="<%= process.env.HOST_URL %>/css/styles.css">
|
||||
<link rel="stylesheet" href="<%= process.env.HOST_URL %>/css/chat.css">
|
||||
<link rel="apple-touch-icon" sizes="180x180" href="/apple-touch-icon.png">
|
||||
<link rel="icon" type="image/png" sizes="32x32" href="/favicon-32x32.png">
|
||||
<link rel="icon" type="image/png" sizes="16x16" href="/favicon-16x16.png">
|
||||
<link rel="manifest" href="/site.webmanifest">
|
||||
<meta name="msapplication-TileColor" content="#da532c">
|
||||
<meta name="theme-color" content="#ffffff">
|
||||
</head>
|
||||
|
||||
<body class="bg-dark text-white">
|
||||
|
||||
<div class="chat-container">
|
||||
<!-- Navbar -->
|
||||
<nav class="navbar navbar-expand-lg navbar-dark">
|
||||
<div class="container-fluid">
|
||||
<a class="navbar-brand" href="<%= process.env.HOST_URL %>">
|
||||
<%= process.env.SITE_NAME %>
|
||||
</a>
|
||||
<button class="navbar-toggler" type="button" data-bs-toggle="collapse" data-bs-target="#navbarNav"
|
||||
aria-controls="navbarNav" aria-expanded="false" aria-label="Toggle navigation">
|
||||
<span class="navbar-toggler-icon"></span>
|
||||
</button>
|
||||
<div class="collapse navbar-collapse" id="navbarNav">
|
||||
<ul class="navbar-nav ms-auto">
|
||||
<% menuItems.forEach(item=> { %>
|
||||
<li class="nav-item">
|
||||
<a class="nav-link" href="<%= item.url %>" <%=item.openNewPage ? 'target="_blank"' : ''
|
||||
%>>
|
||||
<%= item.title %>
|
||||
</a>
|
||||
</li>
|
||||
<% }) %>
|
||||
|
||||
<!-- Add a vertical divider -->
|
||||
<!-- <li class="nav-item">
|
||||
<span class="nav-link separator">|</span>
|
||||
</li> -->
|
||||
|
||||
<!-- Inject custom menu items here as a dropdown -->
|
||||
<!-- <li class="nav-item dropdown">
|
||||
<a class="nav-link dropdown-toggle" href="#" id="navbarDropdown" role="button"
|
||||
data-bs-toggle="dropdown" aria-expanded="false">
|
||||
Tools
|
||||
</a>
|
||||
<ul class="dropdown-menu dropdown-menu-end" aria-labelledby="navbarDropdown">
|
||||
<li><a class="dropdown-item" href="#" onclick="openLiveLog()">Live Log</a></li>
|
||||
<li><a class="dropdown-item" href="#" onclick="openTop()">Top</a></li>
|
||||
<li><a class="dropdown-item" href="#" onclick="openNetdata()">Netdata</a></li>
|
||||
<li><a class="dropdown-item" href="#" onclick="openGpuStats()">GPU Stats</a>
|
||||
</li>
|
||||
<li><a class="dropdown-item" href="#" onclick="openAbout()">About RayAI</a></li>
|
||||
</ul>
|
||||
</li> -->
|
||||
</ul>
|
||||
</div>
|
||||
</div>
|
||||
</nav>
|
||||
|
||||
|
||||
<!-- Alert Messages -->
|
||||
<div id="success-alert" class="alert alert-success mt-3" style="display: none;"></div>
|
||||
<div id="error-alert" class="alert alert-danger mt-3" style="display: none;"></div>
|
||||
<!-- Chat Box -->
|
||||
<div class="chat-box">
|
||||
<div id="messages" class="messages"></div>
|
||||
|
||||
<!-- Input area with sticky behavior -->
|
||||
<div class="input-area">
|
||||
<textarea id="messageInput" class="form-control mb-2" rows="3" placeholder=""
|
||||
onkeydown="handleKeyDown(event)" autofocus></textarea>
|
||||
|
||||
<!-- Buttons side by side -->
|
||||
<div class="d-flex justify-content-between">
|
||||
<button class="btn btn-secondary" onclick="resetChat()">Reset Chat</button>
|
||||
|
||||
<!-- Loading Indicator -->
|
||||
<div id="loading" class="text-center mt-3" style="display: none;">
|
||||
<div class="spinner-border spinner-border-sm text-primary" role="status">
|
||||
<span class="visually-hidden">Loading...</span>
|
||||
</div>
|
||||
</div>
|
||||
<button class="btn btn-primary" onclick="sendMessage()">Send Message</button>
|
||||
|
||||
</div>
|
||||
</div>
|
||||
|
||||
|
||||
|
||||
</div>
|
||||
|
||||
</div>
|
||||
|
||||
<!-- Bootstrap JS Bundle -->
|
||||
<script src="https://cdn.jsdelivr.net/npm/bootstrap@5.3.0-alpha1/dist/js/bootstrap.bundle.min.js"></script>
|
||||
<!-- Additional Libraries -->
|
||||
<script src="https://cdnjs.cloudflare.com/ajax/libs/marked/3.0.7/marked.min.js"></script>
|
||||
<script src="https://cdnjs.cloudflare.com/ajax/libs/highlight.js/11.6.0/highlight.min.js"></script>
|
||||
<script src="https://cdn.jsdelivr.net/npm/he@1.2.0/he.min.js"></script>
|
||||
|
||||
<!-- Inline JavaScript -->
|
||||
<script src="<%= process.env.HOST_URL %>/js/chat.js"></script>
|
||||
</body>
|
||||
|
||||
</html>
|
||||
@ -5,35 +5,41 @@
|
||||
<!-- Meta and Title -->
|
||||
<meta charset="UTF-8">
|
||||
<meta name="viewport" content="width=device-width, initial-scale=1.0">
|
||||
<title>Contact Me - Raven Scott</title>
|
||||
<meta name="description" content="Contact <%= process.env.OWNER_NAME %> using a contact form">
|
||||
|
||||
<title>Contact Me - <%= process.env.OWNER_NAME %></title>
|
||||
<!-- Bootstrap CSS -->
|
||||
<link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/bootstrap@5.3.0-alpha1/dist/css/bootstrap.min.css">
|
||||
<!-- Font Awesome CSS for Icons -->
|
||||
<link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/font-awesome/6.0.0-beta3/css/all.min.css">
|
||||
<!-- Custom CSS -->
|
||||
<link rel="stylesheet" href="/css/styles.css">
|
||||
<link rel="stylesheet" href="<%= process.env.HOST_URL %>/css/styles.css">
|
||||
<link rel="apple-touch-icon" sizes="180x180" href="<%= process.env.HOST_URL %>/apple-touch-icon.png">
|
||||
<link rel="icon" type="image/png" sizes="32x32" href="<%= process.env.HOST_URL %>/favicon-32x32.png">
|
||||
<link rel="icon" type="image/png" sizes="16x16" href="<%= process.env.HOST_URL %>/favicon-16x16.png">
|
||||
<link rel="manifest" href="<%= process.env.HOST_URL %>/site.webmanifest">
|
||||
<meta name="msapplication-TileColor" content="#da532c">
|
||||
<meta name="theme-color" content="#ffffff">
|
||||
<!-- reCAPTCHA API -->
|
||||
<script src="https://www.google.com/recaptcha/api.js" async defer></script>
|
||||
</head>
|
||||
|
||||
<body class="bg-dark text-white">
|
||||
|
||||
<!-- Navigation Bar -->
|
||||
<!-- Navbar -->
|
||||
<nav class="navbar navbar-expand-lg navbar-dark">
|
||||
<div class="container-fluid">
|
||||
<a class="navbar-brand" href="/">raven-scott.fyi</a>
|
||||
<a class="navbar-brand" href="<%= process.env.HOST_URL %>"><%= process.env.SITE_NAME %></a>
|
||||
<button class="navbar-toggler" type="button" data-bs-toggle="collapse" data-bs-target="#navbarNav" aria-controls="navbarNav" aria-expanded="false" aria-label="Toggle navigation">
|
||||
<span class="navbar-toggler-icon"></span>
|
||||
</button>
|
||||
<div class="collapse navbar-collapse" id="navbarNav">
|
||||
<ul class="navbar-nav ms-auto">
|
||||
<li class="nav-item">
|
||||
<a class="nav-link active" href="/">Home</a>
|
||||
</li>
|
||||
<li class="nav-item">
|
||||
<a class="nav-link" href="/about">About Me</a>
|
||||
</li>
|
||||
<li class="nav-item">
|
||||
<a class="nav-link" href="/contact">Contact</a>
|
||||
</li>
|
||||
<% menuItems.forEach(item => { %>
|
||||
<li class="nav-item">
|
||||
<a class="nav-link" href="<%= item.url %>" <%= item.openNewPage ? 'target="_blank"' : '' %>><%= item.title %></a>
|
||||
</li>
|
||||
<% }) %>
|
||||
</ul>
|
||||
</div>
|
||||
</div>
|
||||
@ -42,7 +48,7 @@
|
||||
<!-- Contact Me Section -->
|
||||
<header class="d-flex align-items-center justify-content-center text-center py-5">
|
||||
<div class="container">
|
||||
<h2 class="mb-4 text-white">Contact Me</h2>
|
||||
<h2 class="mb-4 text-white">Contacting <%= process.env.OWNER_NAME %></h2>
|
||||
<p class="lead text-white">Have a question or need help with a project? Fill out the form below, and I'll be in touch!</p>
|
||||
|
||||
<!-- Display success or error message -->
|
||||
@ -70,21 +76,19 @@
|
||||
<label for="message" class="form-label">Your Message<span class="text-danger">*</span></label>
|
||||
<textarea class="form-control bg-dark text-white border-secondary" id="message" name="message" rows="6" required></textarea>
|
||||
</div>
|
||||
|
||||
<!-- reCAPTCHA -->
|
||||
<CENTER><div class="g-recaptcha" data-sitekey="<%= process.env.CAPTCHA_SITE_KEY %>"></div></CENTER>
|
||||
<BR>
|
||||
<button type="submit" class="btn btn-primary">Send Message</button>
|
||||
</form>
|
||||
</div>
|
||||
</header>
|
||||
|
||||
<!-- Footer -->
|
||||
<footer class="bg-dark text-white text-center py-4">
|
||||
<footer class=" text-white text-center py-4">
|
||||
<div class="container">
|
||||
<h4 class="footer-logo mb-3">Never Stop Learning</h4>
|
||||
<p class="footer-links mb-3">
|
||||
<a href="/" class="text-white text-decoration-none me-3">Home</a>
|
||||
<a href="/about" class="text-white text-decoration-none me-3">About</a>
|
||||
<a href="/contact" class="text-white text-decoration-none">Contact</a>
|
||||
</p>
|
||||
<p class="mb-0">© 2024 Raven Scott. All rights reserved.</p>
|
||||
<p class="mb-0">© 2025 <%= process.env.OWNER_NAME %>. All rights reserved.</p>
|
||||
</div>
|
||||
</footer>
|
||||
|
||||
|
||||
@ -3,56 +3,79 @@
|
||||
<head>
|
||||
<meta charset="UTF-8">
|
||||
<meta name="viewport" content="width=device-width, initial-scale=1.0">
|
||||
<meta name="description" content="<%= process.env.OWNER_NAME %>'s Blog">
|
||||
<title><%= title %></title>
|
||||
<link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/bootstrap@5.3.0-alpha1/dist/css/bootstrap.min.css">
|
||||
<link rel="stylesheet" href="/css/styles.css">
|
||||
<link rel="stylesheet" href="<%= process.env.HOST_URL %>/css/styles.css">
|
||||
<script>
|
||||
window.onload = function() {
|
||||
const input = document.getElementById("search-input");
|
||||
input.focus();
|
||||
input.setSelectionRange(input.value.length, input.value.length);
|
||||
};
|
||||
</script>
|
||||
</head>
|
||||
<body>
|
||||
<!-- Navbar -->
|
||||
<nav class="navbar navbar-expand-lg navbar-dark">
|
||||
<div class="container-fluid">
|
||||
<a class="navbar-brand" href="/">raven-scott.fyi</a>
|
||||
<a class="navbar-brand" href="<%= process.env.HOST_URL %>"><%= process.env.SITE_NAME %></a>
|
||||
<button class="navbar-toggler" type="button" data-bs-toggle="collapse" data-bs-target="#navbarNav" aria-controls="navbarNav" aria-expanded="false" aria-label="Toggle navigation">
|
||||
<span class="navbar-toggler-icon"></span>
|
||||
</button>
|
||||
<div class="collapse navbar-collapse" id="navbarNav">
|
||||
<ul class="navbar-nav ms-auto">
|
||||
<li class="nav-item">
|
||||
<a class="nav-link active" href="/">Home</a>
|
||||
</li>
|
||||
<li class="nav-item">
|
||||
<a class="nav-link" href="/about">About Me</a>
|
||||
</li>
|
||||
<li class="nav-item">
|
||||
<a class="nav-link" href="/contact">Contact</a>
|
||||
</li>
|
||||
<% menuItems.forEach(item => { %>
|
||||
<li class="nav-item">
|
||||
<a class="nav-link" href="<%= item.url %>" <%= item.openNewPage ? 'target="_blank"' : '' %>><%= item.title %></a>
|
||||
</li>
|
||||
<% }) %>
|
||||
</ul>
|
||||
</div>
|
||||
</div>
|
||||
</nav>
|
||||
|
||||
|
||||
<!-- Main Content -->
|
||||
<header class="py-5">
|
||||
<div class="container text-center">
|
||||
<h1>Welcome to my long form post blog</h1>
|
||||
<p class="lead">Latest articles and insights from Raven Scott</p>
|
||||
<h1><%= process.env.FRONT_PAGE_TITLE %></h1>
|
||||
<p class="lead"><%= process.env.FRONT_PAGE_LEAD %></p>
|
||||
<form action="/" method="get" class="mb-4">
|
||||
<div class="input-group">
|
||||
<input type="text" id="search-input" name="search" class="form-control" placeholder="Search blog posts..." value="<%= typeof searchQuery !== 'undefined' ? searchQuery : '' %>" autofocus>
|
||||
</div>
|
||||
</form>
|
||||
</div>
|
||||
</header>
|
||||
|
||||
<!-- Blog Content -->
|
||||
<section class="py-5">
|
||||
<div class="container">
|
||||
<h2>Recent Posts</h2>
|
||||
<!-- Blog post list -->
|
||||
<% if (noResults) { %>
|
||||
<p><center>Sorry, no blog posts found matching "<%= searchQuery %>"</center></p>
|
||||
<% } else { %>
|
||||
<h2><%= searchQuery ? 'Search results for "' + searchQuery + '"' : 'Recent Posts' %></h2>
|
||||
<% } %>
|
||||
<ul class="list-group list-group-flush">
|
||||
<% blogPosts.forEach(post => { %>
|
||||
<li class="list-group-item d-flex justify-content-between align-items-center py-4">
|
||||
<div>
|
||||
<h5 class="mb-1"><a href="/blog/<%= post.slug %>"> <%= post.title %> </a></h5>
|
||||
<p class="mb-1 text-muted">Posted on <%= post.date %></p>
|
||||
<h5 class="mb-1"><a href="<%= process.env.BLOG_URL %><%= post.slug %>"><%= post.title %></a></h5>
|
||||
<p class="mb-1 text-muted">Posted on
|
||||
<%= new Date(post.dateCreated).toLocaleDateString('en-US', {
|
||||
year: 'numeric',
|
||||
month: 'long',
|
||||
day: 'numeric'
|
||||
}) %>
|
||||
</p>
|
||||
</div>
|
||||
<a href="/blog/<%= post.slug %>" class="btn btn-outline-primary">Read Article</a>
|
||||
<a href="<%= process.env.BLOG_URL %><%= post.slug %>" class="btn btn-outline-primary">Read Article</a>
|
||||
</li>
|
||||
<% }) %>
|
||||
</ul>
|
||||
|
||||
|
||||
<!-- Pagination controls -->
|
||||
<nav aria-label="Page navigation">
|
||||
<ul class="pagination justify-content-center mt-4">
|
||||
@ -61,13 +84,13 @@
|
||||
<a class="page-link" href="?page=<%= currentPage - 1 %>">Previous</a>
|
||||
</li>
|
||||
<% } %>
|
||||
|
||||
|
||||
<% for (let i = 1; i <= totalPages; i++) { %>
|
||||
<li class="page-item <%= currentPage === i ? 'active' : '' %>">
|
||||
<a class="page-link" href="?page=<%= i %>"><%= i %></a>
|
||||
</li>
|
||||
<% } %>
|
||||
|
||||
|
||||
<% if (currentPage < totalPages) { %>
|
||||
<li class="page-item">
|
||||
<a class="page-link" href="?page=<%= currentPage + 1 %>">Next</a>
|
||||
@ -78,18 +101,37 @@
|
||||
</div>
|
||||
</section>
|
||||
|
||||
<footer class="bg-dark text-white text-center py-4">
|
||||
<footer class="text-white text-center py-4">
|
||||
<div class="container">
|
||||
<h4 class="footer-logo mb-3">Never Stop Learning</h4>
|
||||
<h4 class="footer-logo mb-3"><%= process.env.FOOTER_TAGLINE %></h4>
|
||||
<p class="footer-links mb-3">
|
||||
<a href="/" class="text-white text-decoration-none me-3">Home</a>
|
||||
<a href="/about" class="text-white text-decoration-none me-3">About</a>
|
||||
<a href="/contact" class="text-white text-decoration-none">Contact</a>
|
||||
<a href="/contact" class="text-white text-decoration-none me-3">Contact</a>
|
||||
<a href="<%= process.env.HOST_URL %>/sitemap.xml" class="text-white text-decoration-none me-3">Sitemap</a>
|
||||
<a href="<%= process.env.HOST_URL %>/rss" class="text-white text-decoration-none">RSS Feed</a>
|
||||
</p>
|
||||
<p class="mb-0">© 2024 Raven Scott. All rights reserved.</p>
|
||||
<p class="mb-0">© 2025 <%= process.env.OWNER_NAME %>. All rights reserved.</p>
|
||||
</div>
|
||||
</footer>
|
||||
|
||||
<script src="https://cdn.jsdelivr.net/npm/bootstrap@5.3.0-alpha1/dist/js/bootstrap.bundle.min.js"></script>
|
||||
<script>
|
||||
let typingTimer; // Timer identifier
|
||||
const doneTypingInterval = 500; // Time in ms, adjust for desired delay
|
||||
|
||||
const searchInput = document.getElementById('search-input');
|
||||
|
||||
searchInput.addEventListener('input', function() {
|
||||
clearTimeout(typingTimer);
|
||||
typingTimer = setTimeout(function() {
|
||||
searchInput.form.submit();
|
||||
}, doneTypingInterval);
|
||||
});
|
||||
|
||||
searchInput.addEventListener('keydown', function() {
|
||||
clearTimeout(typingTimer);
|
||||
});
|
||||
</script>
|
||||
</body>
|
||||
</html>
|
||||
|
||||